铁岭做网站一般多少钱真正永久免费的建站系统有哪些
文章目录
- 冷热集群架构的应用场景
- 冷热集群架构的优势
- 冷热集群架构实战
- 搭建集群
- 索引生命周期管理
- 认识索引生命周期
- 索引生命周期管理的历史演变
- 索引生命周期管理的基础知识
- Rollover:滚动索引
冷热集群架构的应用场景
某客户的线上业务场景如下:系统每天增加6TB日志数据,高峰时段的写入和查询频率都很高,导致Elasticsearch集群压力大,经常出现查询缓慢的问题。
目前采用冷热集群架构,其中热节点使用SSD,并具有良好的索引和搜索性能,将数据保存4天后推送到温节点中,并使用HDD进行存储。改善架构后,集群性能有极大提升。
总之,在成本有限的情况下,让客户专注于实时数据和历史数据之间的硬件隔离可以最大化解决客户反映的检索响应慢的问题。
冷热集群架构的优势
Elasticsearch集群采用冷热集群架构会具有以下优势。
1)有效降低存储成本:将不常用的数据存储在冷节点上,可以减小热节点上索引大小并降低存储成本。这可有效降低硬件成本并提高索引查询效率。
2)更好地管理数据:将不同类型的数据分配到不同类型的节点上,可以更好地管理数据。这为索引生命周期管理提供了保障。
3)提高查询性能:将热节点用于处理最常访问的数据,而将冷节点用于存储不常用的数据,可以缩短查询响应时间并提高查询性能。
4)优化集群性能:将不同类型的任务分配给不同类型的节点,可以避免资源争夺现象,从而提高整个集群系统性能。
5)更好的可扩展性:使用冷热集群架构,在需要适应数据量增长或其他需求变化时,运维人员可以更容易地扩展集群、添加或删除节点。综上所述,Elasticsearch的冷热集群架构可以提高查询性能、降低存储成本、优化集群性能、更好地管理数据和提高可扩展性。这些优势使其成为处理PB级时序大数据的理想选择。
冷热集群架构实战
搭建集群
首先搭建一个具有3个节点的集群,划分冷、温、热节点角色。在节点层面设置节点类型,分别如下所示。
version: '2.2'
services:cerebro:image: lmenezes/cerebro:0.8.3container_name: hwc_cerebroports:- "9000:9000"command:- -Dhosts.0.host=http://elasticsearch:9200networks:- hwc_es7netkibana:image: docker.elastic.co/kibana/kibana:7.1.0container_name: hwc_kibana7environment:- XPACK_GRAPH_ENABLED=true- TIMELION_ENABLED=true- XPACK_MONITORING_COLLECTION_ENABLED="true"ports:- "5601:5601"networks:- hwc_es7netelasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_hotenvironment:- cluster.name=geektime-hwc- node.name=es7_hot- node.attr.box_type=hot- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_hot:/usr/share/elasticsearch/dataports:- 9200:9200networks:- hwc_es7netelasticsearch2:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_warmenvironment:- cluster.name=geektime-hwc- node.name=es7_warm- node.attr.box_type=warm- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_warm:/usr/share/elasticsearch/datanetworks:- hwc_es7netelasticsearch3:image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0container_name: es7_coldenvironment:- cluster.name=geektime-hwc- node.name=es7_cold- node.attr.box_type=cold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.seed_hosts=es7_hot,es7_warm,es7_cold- cluster.initial_master_nodes=es7_hot,es7_warm,es7_coldulimits:memlock:soft: -1hard: -1volumes:- hwc_es7data_cold:/usr/share/elasticsearch/datanetworks:- hwc_es7netvolumes:hwc_es7data_hot:driver: localhwc_es7data_warm:driver: localhwc_es7data_cold:driver: localnetworks:hwc_es7net:driver: bridge
三个节点冷热集群架构启动后,使用如下命令查看节点。
GET /_cat/nodes?v

查询节点属性使用如下命令
GET _cat/nodeattrs
es7_warm 172.21.0.6 172.21.0.6 ml.machine_memory 9698672640
es7_warm 172.21.0.6 172.21.0.6 ml.max_open_jobs 20
es7_warm 172.21.0.6 172.21.0.6 box_type warm
es7_warm 172.21.0.6 172.21.0.6 xpack.installed true
es7_cold 172.21.0.2 172.21.0.2 ml.machine_memory 9698672640
es7_cold 172.21.0.2 172.21.0.2 ml.max_open_jobs 20
es7_cold 172.21.0.2 172.21.0.2 box_type cold
es7_cold 172.21.0.2 172.21.0.2 xpack.installed true
es7_hot 172.21.0.4 172.21.0.4 ml.machine_memory 9698672640
es7_hot 172.21.0.4 172.21.0.4 box_type hot
es7_hot 172.21.0.4 172.21.0.4 xpack.installed true
es7_hot 172.21.0.4 172.21.0.4 ml.max_open_jobs 20方案一:在索引层面指定节点角色写入数据。
PUT mytest
{"settings":{"number_of_shards":1,"number_of_replicas":0,"index.routing.allocation.require.box_type":"cold"}
}
GET /_cat/shards/mytest?h=i,shard,p,node
mytest 0 p es7_cold
方案二:通过模板指定节点角色写入数据。
POST _template/my-template
{"index_patterns": "test-*","settings": {"index.number_of_replicas": "0","index.routing.allocation.require.box_type":"cold"}
}GET _template/my-templatePUT /test-01GET /_cat/shards/test-01?h=i,shard,p,node
索引生命周期管理
认识索引生命周期
在大规模系统中,特别是以日志、指标和实时时间序列为基础的系统中,集群索引的发展和变化遵循其固有规律。理论上来说,一旦创建了索引,它就可能永久存在。然而,在创建后,如果让索引无限制地扩张下去,则会演变成一个数据量庞大且过度膨胀的实体。这种情况可能导致一系列问题,例如,随着时间推移,时序数据和业务数据量逐步增加。
实际上,索引并非无限制存在的,举例如下。
❑集群单个分片的最大文档数上限约为20亿条(即232-1)。
❑根据官方的最佳实践建议,应将索引分片大小控制在30GB~50GB之间。
❑如果索引数据量过大,则可能出现健康问题,并导致整个集群核心业务停摆。
❑大型索引恢复所需时间远远超过小型索引。
❑大型索引检索单位速度较慢,并影响写入和更新操作。
❑在某些业务场景中用户更关注最近3天或7天的业务数据;而大型索引会将所有历史数据汇聚在一起,不利于查询特定需求的数据。
索引生命周期管理的历史演变
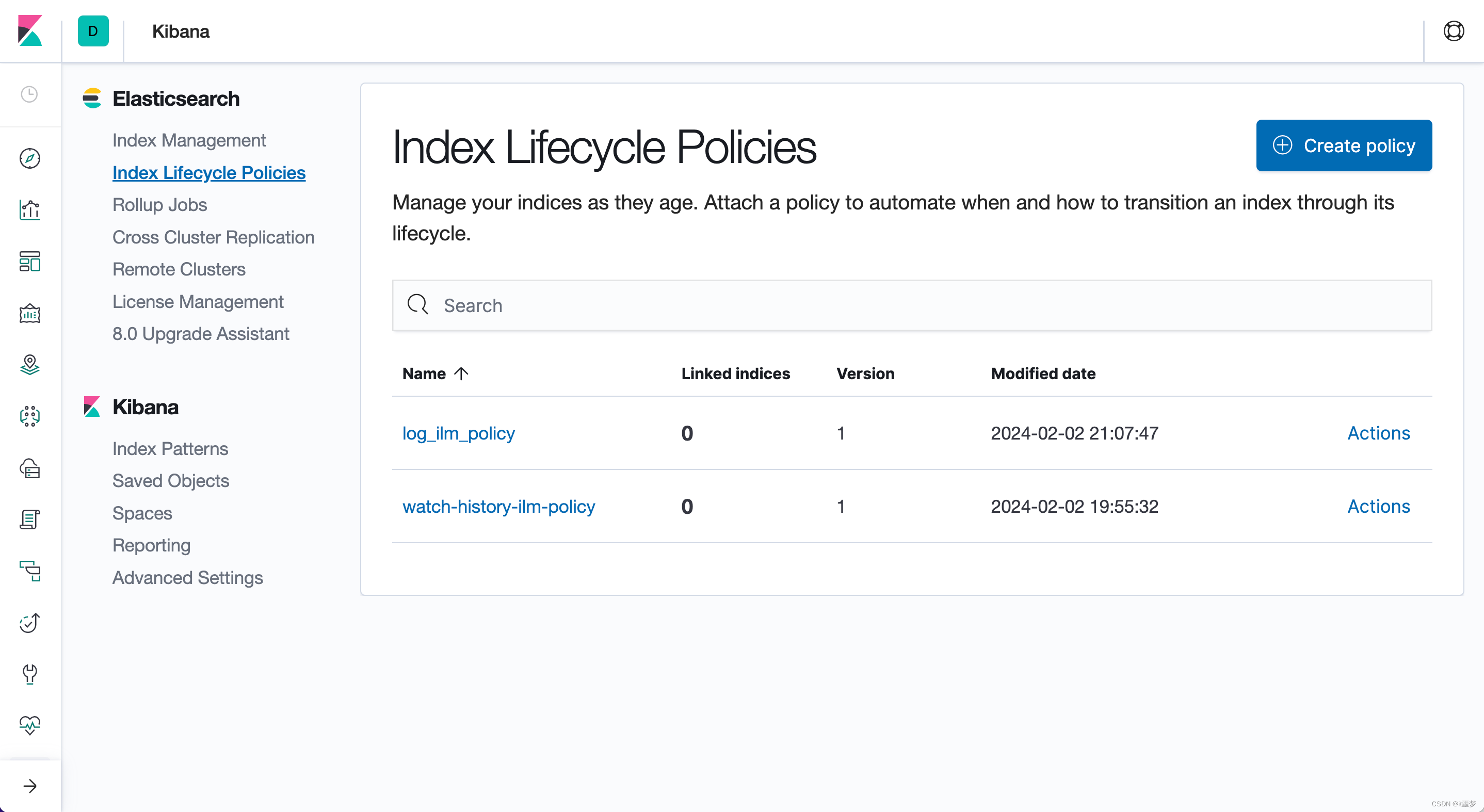
ILM(索引生命周期管理)是Elasticsearch 6.6(公测版)首次引入的功能,并于6.7版本正式推出。它是Elasticsearch的一部分,主要用于帮助用户管理索引。在没有ILM之前,索引生命周期的管理基于Rollover和Curator工具实现。Kibana 7.X版本提供了一个配置界面来进行索引生命周期管理,如图所示。
索引生命周期管理的基础知识
在3个节点的集群中,节点角色的设置分别如下。
❑节点node-1:主节点+数据节点+热节点。
❑节点node-2:主节点+数据节点+温节点。
❑节点node-3:主节点+数据节点+冷节点。
为了演示如何应用ILM,首先需要配置冷热架构,在上文中已经讲解了配置细节。如果磁盘数量不足,则待删除的冷数据在处理时具有最高优先级;如果硬件资源相对受限,则应将SSD作为热节点的首选配置。检索优先级最高的是热节点数据,因此检索热节点数据比检索全量数据的响应速度更快。
Rollover:滚动索引
自从Elasticsearch 5.X版本推出Rollover API以来,该API解决了使用日期作为索引名称的索引所具有的大小不均衡的问题。对于日志类数据而言,Rollover非常有用。通常情况下,我们按天对索引进行分割(如果数据量更大,则可以进一步拆分)。在没有Rollover之前,我们需要在程序中设置一个自动生成索引的模板。
以下讲解如何实践Rollover操作。
1)创建符合正则表达式规范(即中间是“-”字符并且后面是数字字符)的索引,并批量导入数据。否则会出现以下报错。

创建索引和导入数据操作如下。
###创建基于日期的索引
PUT my-index-20250709-0000001
{"aliases": {"my-alias": {"is_write_index": true}}
}
####批量导入数据
PUT my-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
2)基于滚动的3个条件实现索引的滚动。
❑滚动条件1:数据写入时间超过7天。
❑滚动条件2:最大文档数超过5条。
❑滚动条件3:最大的主分片数大于50gb(这里的gb代表Gigabytes,可理解为GB)。
注意:
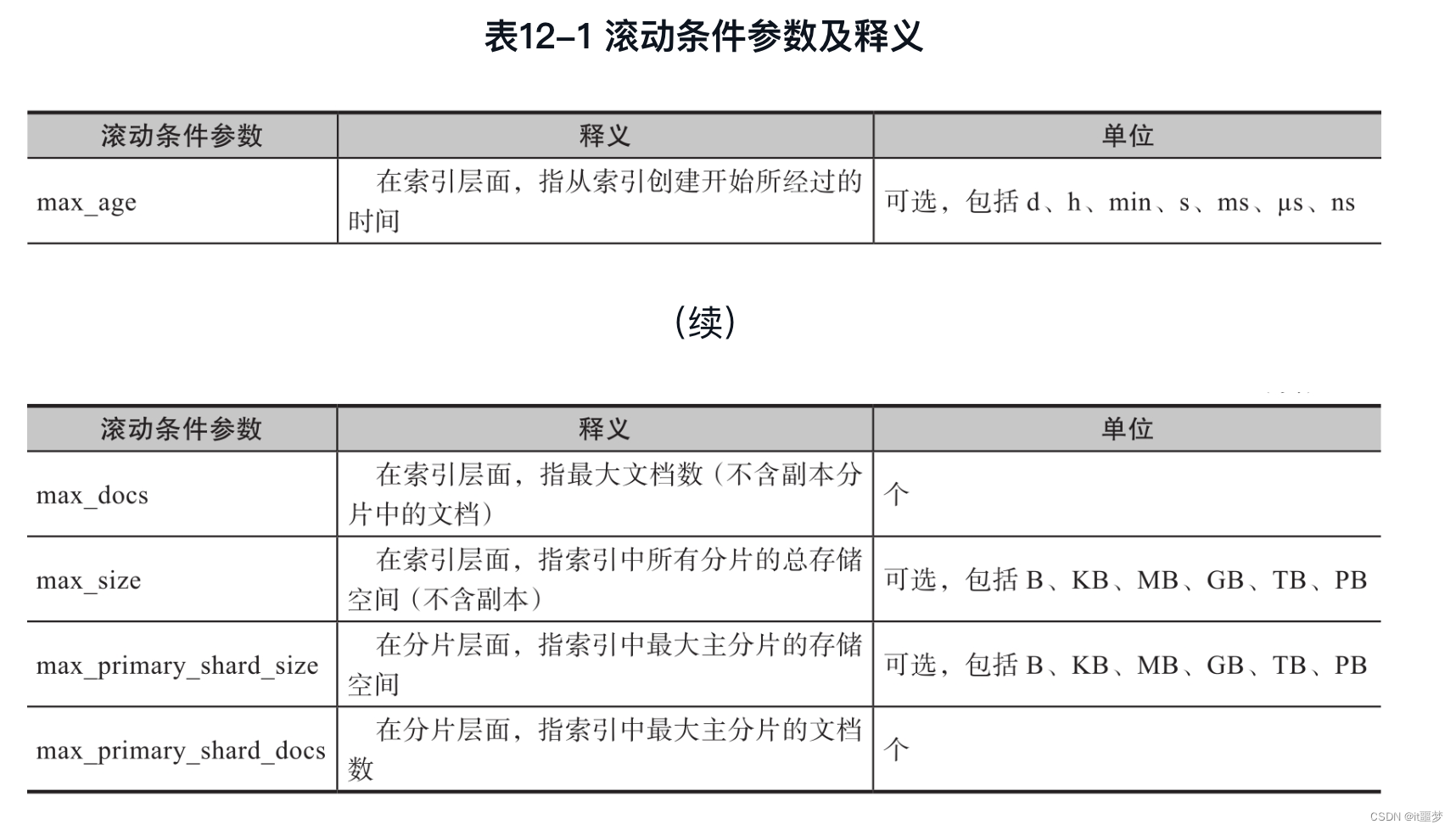
当3个条件是“或”的关系时,只要满足其中一个,索引就会滚动。在Elasticsearch 7.X版本中,可以设置的滚动条件如表12-1所示。
查看索引中所有主分片(pri.store.size)的总存储空间,命令如下。
GET _cat/indices?v&s=pri.store.size:desc
查看分片大小,且按照分片大小由大到小进行排序,命令行如下。其中p代表主分片,r代表副本分片。
GET /_cat/shards?v=true&s=store:desc
滚动索引操作如下。
# rollover滚动索引
POST my-alias/_rollover
{"conditions": {"max age": "7d","max docs": 5,"max_primary_shard_size": "50gb"}
}GET my-alias/ _count
#在满足滚动条件的前提下滚动索引
PUT my-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
#检索数据,验证滚动是否生效
GET my-alias/_search
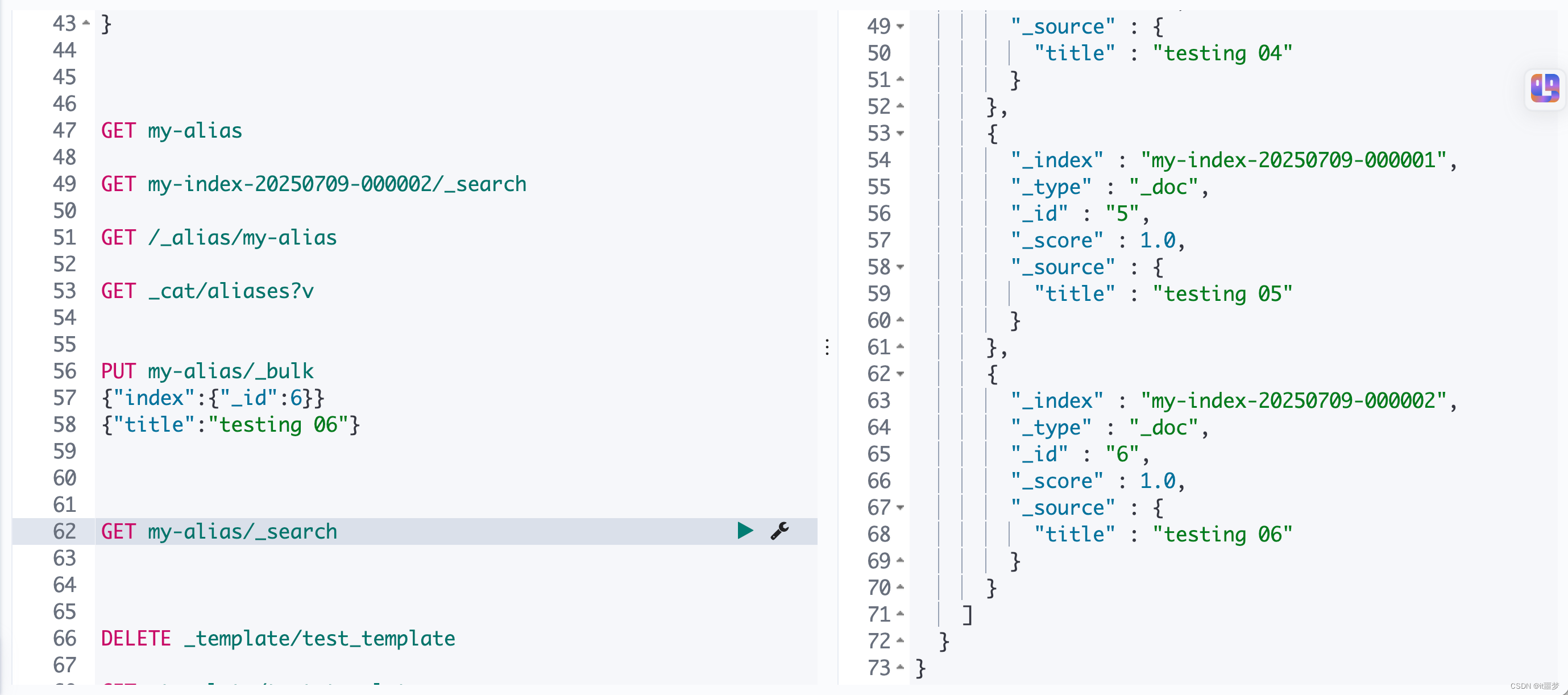
执行结果如下所示。我们可以清晰看到,插入第6条数据会触发max_docs:5的条件,原来的索引my-index-20250709-000001会继续保留,而新写入的第6条数据滚动到了新索引my-index-20250709-000002中。滚动索引操作的效果如图所示。
es 7.17.1
DELETE _template/test_templateGET _template/test_templatePUT _ilm/policy/my_policy
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_docs": 3 }}},"delete": {"min_age": "30d","actions": {"delete": {}}}}}
}PUT _template/test_template
{"order": 0,"index_patterns": ["test_*"],"settings": {"index": {"number_of_shards": "6","refresh_interval": "10s"},"lifecycle": {"name": "my_policy","rollover_alias" : "test_rollover"}},"mappings": {"properties": {"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"requestId": {"type": "keyword"},"title": {"type": "text","analyzer": "standard","fields": {"keyword": {"type": "keyword"}}}}},"aliases": {}
}PUT %3Ctest_%7Bnow%2Fd%7D-000001%3E
{"aliases": {"test_rollover": {"is_write_index": true}}
}GET %3Ctest_%7Bnow%2Fd%7D-000001%3EPOST /test_rollover/_rollover
{"conditions": {"max_docs": 3 }
}POST /test_rollover/_doc
{"businessInfo":"078"
}GET /test_rollover/_doc/_search## indices.lifecycle.poll_interval 索引生命周期策略默认是10分钟检查一次符合策略的索引GET _cluster/settings?include_defaults&flat_settingsGET _cat/nodeattrs?v&h=host,attr,value参考
https://juejin.cn/post/7217399337989488695#heading-3
https://help.aliyun.com/document_detail/178307.html
## 运行三个节点,分片 将box_type设置成 hot,warm和coldPUT _cluster/settings
{"persistent": {"indices.lifecycle.poll_interval":"1s"}
}PUT /_ilm/policy/log_ilm_policy
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_docs": 5}}},"warm": {"min_age": "10s","actions": {"allocate": {"include": {"box_type": "warm"}}}},"cold": {"min_age": "15s","actions": {"allocate": {"include": {"box_type": "cold"}}}},"delete": {"min_age": "20s","actions": {"delete": {}}}}}
}PUT /_template/log_ilm_template
{"index_patterns" : ["app_log-*"],"settings" : {"index" : {"lifecycle" : {"name" : "log_ilm_policy","rollover_alias" : "app_log"},"routing" : {"allocation" : {"include" : {"box_type" : "hot"}}},"number_of_shards" : "1","number_of_replicas" : "0"}},"mappings" : { },"aliases" : {}
}GET /_template/DELETE /_template/log_ilm_templatePUT %3Capp_log-%7Bnow%2Fs%7Byyyy.MM.dd-HHmm%7D%7D-000001%3E
{"aliases":{"app_log":{"is_write_index":true}}
}POST app_log/_doc
{"dfd":"qweqwe"
}DELETE app_log-2024.01.06-0749-000001GET app_log-2024.01.06-0800-000001/_settings- 安装 https://github.com/onebirdrocks/geektime-ELK