上海松江做网站公司南阳网站seo
数据入湖Hudi

Apache Hudi(简称:Hudi)使得您能在hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。这两种原语分别是:
- Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
- 变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。
配置
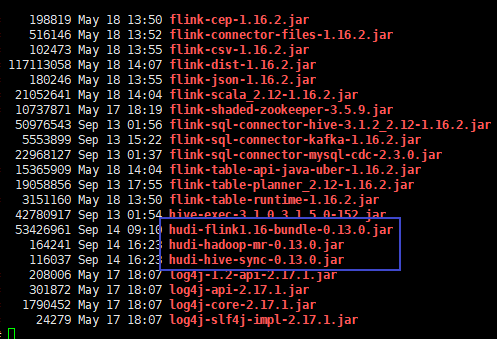
将hudi相关jar包放在flink安装目录的lib下
hudi-flink1.16-bundle-0.13.0.jar
hudi-hadoop-mr-0.13.0.jar
hudi-hive-sync-0.13.0.jar
确保/etc/profile配置了hadoop和hive的环境变量
#HADOOP_HOME
export HADOOP_HOME=/usr/hdp/3.1.5.0-152/hadoop
export HADOOP_CONF_DIR=/usr/hdp/3.1.5.0-152/hadoop/etc/hadoop
export HADOOP_COMMON_HOME=/usr/hdp/3.1.5.0-152/hadoop
export HADOOP_HDFS_HOME=/usr/hdp/3.1.5.0-152/hadoop
export HADOOP_YARN_HOME=/usr/hdp/3.1.5.0-152/hadoop
export HADOOP_MAPRED_HOME=/usr/hdp/3.1.5.0-152/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`hadoop classpath`#HIVE HOME
export HIVE_HOME=/usr/hdp/3.1.5.0-152/hive
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin测试插入hudi表
set sql-client.execution.result-mode = tableau;
set execution.checkpointing.interval=30sec;
SET table.sql-dialect=default;CREATE TABLE hudi_test(uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH ('connector' = 'hudi', -- 连接器指定hudi'path' = 'hdfs://bigdata101:8020/hudi/hudi_test', -- 数据存储地址'table.type' = 'MERGE_ON_READ' -- 表类型,默认COPY_ON_WRITE,可选MERGE_ON_READ
);INSERT INTO hudi_test VALUES('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');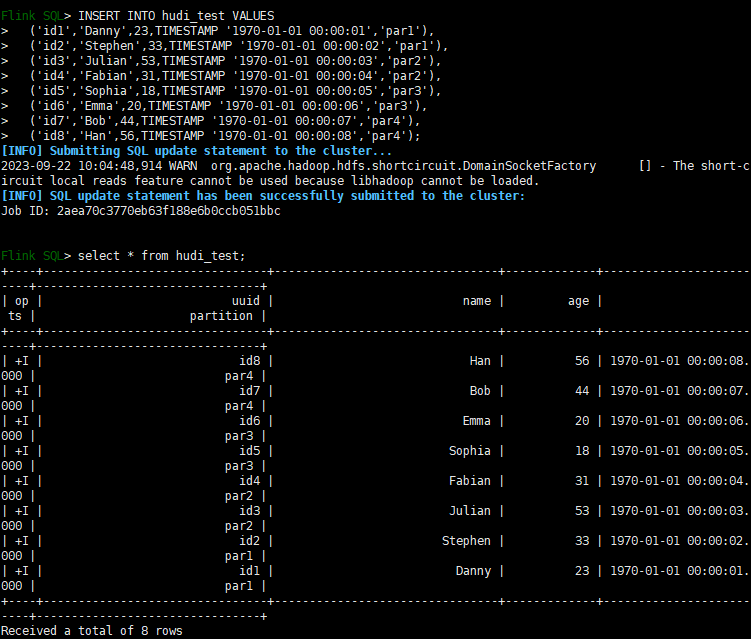
MySql数据写入Hudi表
建hudi表
create table hudi_user(id string not null,name string,birth string,gender string,primary key (id) not enforced
)
with ('connector' = 'hudi','path' = 'hdfs://bigdata101:8020/hudi/hudi_user','table.type' = 'MERGE_ON_READ','write.option' = 'bulk_insert','write.precombine.field' = 'id'
);将MySql映射表的数据插入hudi表,此时会生成一个flink任务
insert into ods.hudi_user select * from mysql_user;


流式查询
上面的查询方式是非流式查询,流式查询会生成一个flink作业,并且实时显示数据源变更的数据。
流式查询(Streaming Query)需要设置read.streaming.enabled = true。再设置read.start-commit,如果想消费所有数据,设置值为earliest。
使用参数如下:
| 参数名称 | 是否必填 | 默认值 | 备注 | ||
| read.streaming.enabled | FALSE | FALSE | 设置为true,开启stream query | ||
| read.start-commit | FALSE | the latest commit | Instant time的格式为:’yyyyMMddHHmmss’ | ||
| read.streaming_skip_compaction | FALSE | FALSE | 是否不消费compaction commit,消费compaction commit会出现重复数据 | ||
| clean.retain_commits | FALSE | 10 | 当开启change log mode,保留的最大commit数量。如果checkpoint interval为5分钟,则保留50分钟的change log | ||
建表:
create table hudi_user_read_streaming(id int not null ,name string,birth string,gender string,primary key (id) not enforced
)
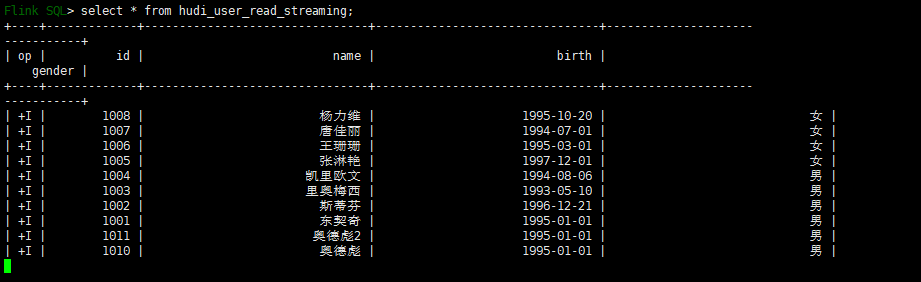
with ('connector' = 'hudi','path' = 'hdfs://bigdata101:8020/hudi/hudi_user','table.type' = 'MERGE_ON_READ','write.option' = 'bulk_insert','write.precombine.field' = 'id','read.streaming.enabled' = 'true', -- 默认值false,设置为true,开启stream query'read.start-commit' = '20231008134557', -- start-commit之前提交的数据不显示,'read.streaming.check-interval' = '4' -- 检查间隔,默认60s);insert into hudi_user_read_streaming select * from mysql_user;select * from hudi_user_read_streaming;此时,执行select 语句就会生成一个flink 作业

源端变更数据会实时展示出来
系列文章
Fink CDC数据同步(一)环境部署![]() https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
Fink CDC数据同步(二)MySQL数据同步![]() https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
Fink CDC数据同步(三)Flink集成Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
Fink CDC数据同步(四)Mysql数据同步到Kafka![]() https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
Fink CDC数据同步(五)Kafka数据同步Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
Fink CDC数据同步(六)数据入湖Hudi![]() https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502