企业商标图片大全南宁seo网络推广
文章目录
- 版权声明
- 一 分布式计算概述
- 1.1 分布式计算
- 1.2 分布式(数据)计算模式
- 1.3 小结
- 二 MapReduce概述
- 2.1 分布式计算框架 - MapReduce
- 2.2 MapReduce执行原理
- 2.3 小结
- 三 YARN概述
- 3.1 YARN & MapReduce
- 3.2 资源调度
- 3.3 程序的资源调度
- 3.4 YARN的资源调度
- 3.5 小结
- 四 YARN架构
- 4.1 核心结构
- 4.2 小结
- 4.3 辅助结构
- 4.4 Web应用代理(Web Application Proxy)
- 4.5 JobHistoryServer历史服务器
- 4.6 YARN架构角色小结
- 五 MapReduce & YARN 的部署
- 5.1 部署说明
- 5.2 集群规划
- 5.3 MapReduce配置文件
- 5.4 分发配置文件
- 5.5 集群启动命令
- 5.6 开始启动YARN集群
- 六 MapReduce & YARN 初体验
- 6.1 集群启停命令
- 6.1.1 一键启动脚本
- 6.1.2 单进程启停
- 6.2 提交MapReduce任务到YARN执行
- 6.2.1 提交wordcount示例程序
- 6.2.2 查看运行日志
- 6.2.3 提交求圆周率示例程序
- 6.3 补充:蒙特卡罗算法求PI的基础原理
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
一 分布式计算概述
1.1 分布式计算
- 分布式计算:以分布式的形式完成数据的统计,得到需要的结果。

1.2 分布式(数据)计算模式
- 分散->汇总模式
- 将数据分片,多台服务器各自负责一部分数据处理
- 然后将各自的结果,进行汇总处理
- 最终得到想要的计算结果
- 生活中的“人口普查”就是典型的分散汇总的分布式统计模式

- 中心调度->步骤执行模式
- 由一个节点作为中心调度管理者
- 将任务划分为几个具体步骤
- 管理者安排每个机器执行任务
- 最终得到结果数据
- 生活中的各类项目的:项目经理 和 项目成员就是这种模式,一个管理分配任务,其余人员领取任务工作

1.3 小结
- 什么是计算、分布式计算?
- 计算:对数据进行处理,使用统计分析等手段得到需要的结果
- 分布式计算:多台服务器协同工作,共同完成一个计算任务
- 分布式计算常见的2种工作模式
- 分散->汇总 (MapReduce就是这种模式)
- 中心调度->步骤执行 (大数据体系的Spark、Flink等是这种模式)
二 MapReduce概述
2.1 分布式计算框架 - MapReduce
- MapReduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
- MapReduce提供了2个编程接口:Map、Reduce,其中
- Map功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
- Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
- 用户如需使用MapReduce框架完成自定义需求的程序开发,只需要使用Java、Python等编程语言,实现Map Reduce功能接口即可。
2.2 MapReduce执行原理
- 假设有如下文件,内部记录了许多的单词。且已经开发好了一个MapReduce程序,功能是统计每个单词出现的次数。
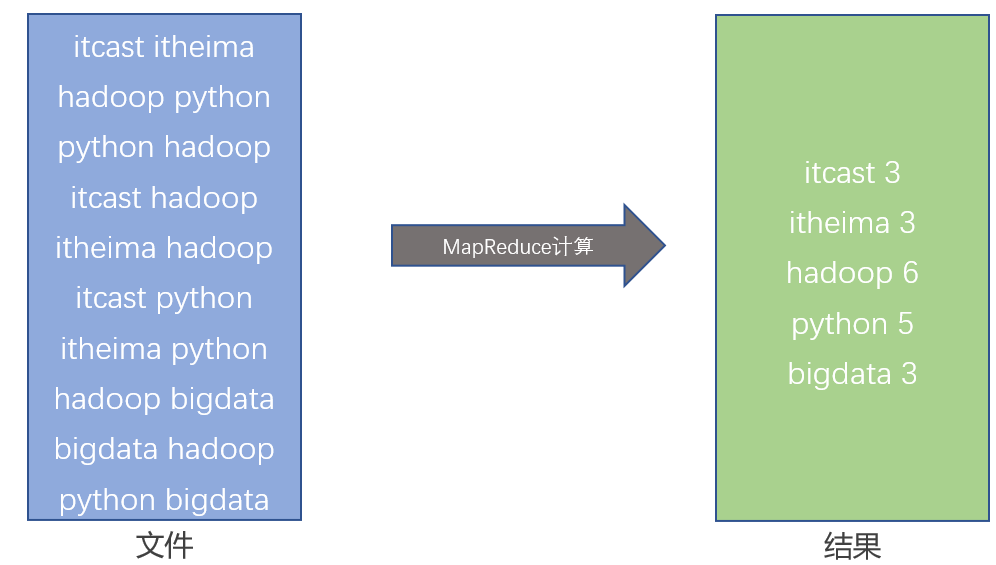
- 假定有4台服务器用以执行MapReduce任务,可以3台服务器执行Map,1台服务器执行Reduce
2.3 小结
- 什么是MapReduce
- MapReduce是Hadoop中的分布式计算组件
- MapReduce可以以分散->汇总(聚合)模式执行分布式计算任务
- MapReduce的主要编程接口
- map接口,主要提供“分散”功能,由服务器分布式处理数据
- reduce接口,主要提供“汇总”功能,进行数据汇总统计得到结果
- MapReduce可供Java、Python等语言开发计算程序
- 注:MapReduce尽管可以通过Java、Python等语言进行程序开发,但当下年代基本没人会写它的代码了,因为太过时了。 尽管MapReduce很老了,但现在仍旧活跃在一线,主要是Apache Hive框架非常火,而Hive底层就是使用的MapReduce。 所以对于MapReduce的代码开发,简单扩展一下,但不会深入讲解,对MapReduce的底层原理会放在Hive之后,基于Hive做深入分析。
- MapReduce的运行机制
- 将要执行的需求,分解为多个Map Task和Reduce Task
- 将Map Task 和 Reduce Task分配到对应的服务器去执行
三 YARN概述
3.1 YARN & MapReduce
- MapReduce是基于YARN运行的,即没有YARN”无法”运行MapReduce程序,所以,MapReduce和YARN要同时学习

3.2 资源调度

- 对于资源的利用,有规划、有管理的调度资源使用,是效率最高的方式,在程序中亦是如此
3.3 程序的资源调度
- 服务器会运行多个程序, 每个程序对资源(CPU内存等)的使用都不同。程序没有节省的概念,有多少就会用多少。所以,为了提高资源利用率,进行调度就非常有必要了。
- 将服务器上的资源进行划分,对程序实行申请制度,需要多少申请多少,提高资源使用率

3.4 YARN的资源调度
-
对于服务器集群亦可使用这种思路,调度整个集群的资源
-
这就是 Hadoop YARN框架的作用:调度整个服务器集群的资源统一管理
-
YARN 管控整个集群的资源进行调度, 那么应用程序在运行时,就是在YARN的监管(管理)下去运行的。
-
一个具体的MapReduce程序。 MapReduce程序会将任务分解为若干个Map任务和Reduce任务。
-
假设,有一个MapReduce程序, 分解了3个Map任务,和1个Reduce任务,那么如何在YARN的监管(管理)下运行呢?

3.5 小结
- YARN是做什么的?
- YARN是Hadoop的一个组件,用以做集群的资源(内存、CPU等)调度
- 为什么需要资源调度
- 将资源统一管控进行分配可以提高资源利用率
- 程序如何在YARN内运行
- 程序向YARN申请所需资源
- YARN为程序分配所需资源供程序使用
- MapReduce和YARN的关系
- YARN用来调度资源给MapReduce分配和管理运行资源,所以,MapReduce需要YARN才能执行(普遍情况)
四 YARN架构
4.1 核心结构
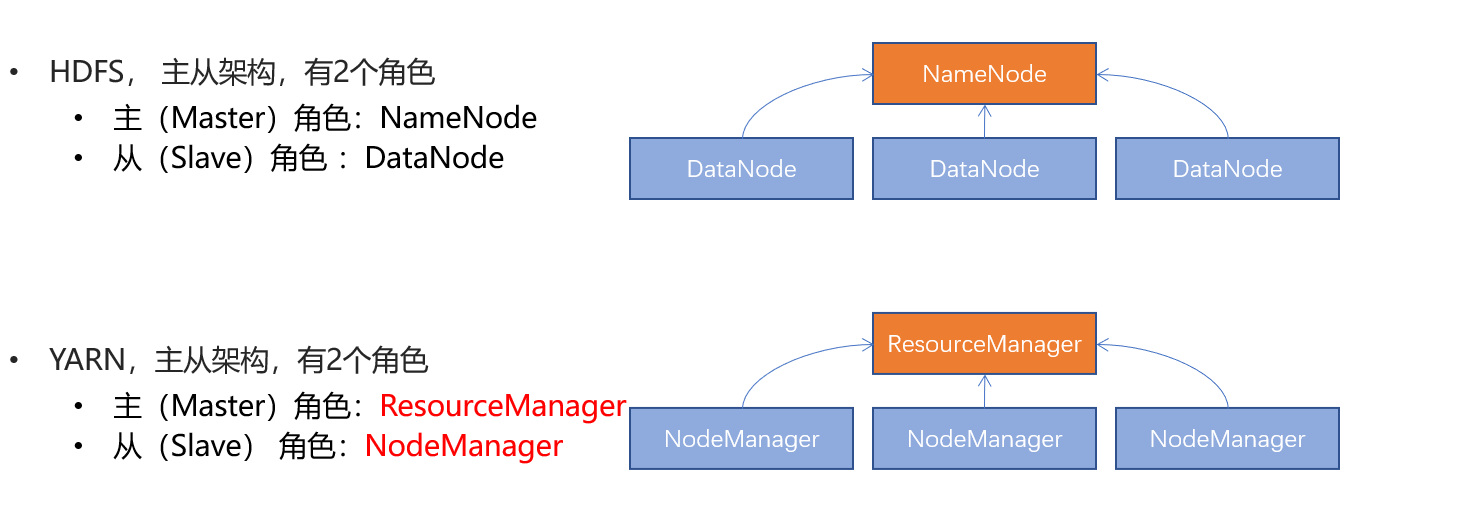
- ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
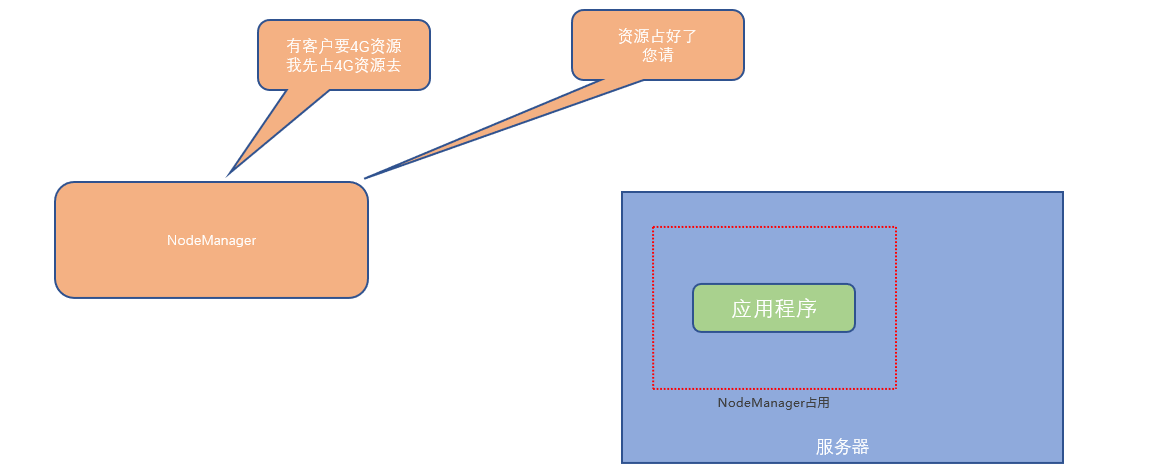
- NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。

- 如何实现服务器上精准分配如下的硬件资源呢?
- NodeManager在服务器上构建一个容器(提前占用资源),然后将容器的资源提供给程序使用,程序运行在容器(集装箱)内,无法突破容器的资源限制。
4.2 小结
- YARN的架构有哪2个角色?
- 主(Master):ResourceManager
- 从(Slave):NodeManager
- 两个角色各自的功能是什么?
- ResourceManager: 管理、统筹并分配整个集群的资源
- NodeManager:管理、分配单个服务器的资源,即创建管理容器,由容器提供资源供程序使用
- 什么是YARN的容器?
- 容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
- 创建一个资源容器,即由NodeManager占用这部分资源
- 然后应用程序运行在NodeManager创建的这个容器内
- 应用程序无法突破容器的资源限制
4.3 辅助结构
- YARN的架构中除了核心角色,即:
- ResourceManager:集群资源总管家
- NodeManager:单机资源管家
- 还可以搭配2个辅助角色使得YARN集群运行更加稳定
- 代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
- 历史服务器(JobHistoryServer): 应用程序历史信息记录服务
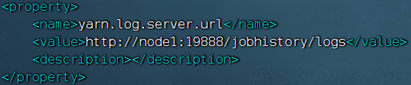
4.4 Web应用代理(Web Application Proxy)
- 代理服务器,即Web应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。
- 因为, YARN在运行时会提供一个WEB UI站点(同HDFS的WEB UI站点一样)可供用户在浏览器内查看YARN的运行信息
- 对外提供WEB 站点会有安全性问题, 而代理服务器的功能就是最大限度保障对WEB UI的访问是安全的。 比如:警告用户正在访问一个不受信任的站点、剥离用户访问的Cookie等
- 开启代理服务器,可以提高YARN在开放网络中的安全性 (但不是绝对安全只能是辅助提高一些)
- 代理服务器默认集成在了ResourceManager中也可以将其分离出来单独启动,如果要分离代理服务器
- 在
yarn-site.xml中配置yarn.web-proxy.address参数即可
<property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description>s/property>
</property>
- 并通过命令启动它即可
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh start proxyserver
4.5 JobHistoryServer历史服务器
- 历史服务器的功能:记录历史运行的程序的信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看

JobHistoryServer历史服务器功能:- 提供WEB UI站点,供用户在浏览器上查看程序日志
- 可以保留历史数据,随时查看历史运行程序信息
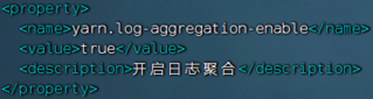
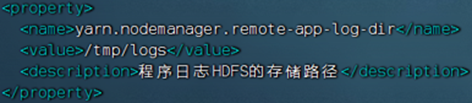
JobHistoryServer需要配置:
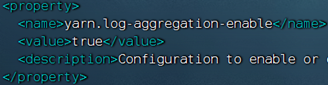
- 开启日志聚合,即从容器中抓取日志到HDFS集中存储
- 配置历史服务器端口和主机

4.6 YARN架构角色小结
- 核心角色:ResourceManager和NodeManager
- 辅助角色:ProxyServer,保障WEB UI访问的安全性
- 辅助角色:JobHistoryServer,记录历史程序运行信息和日志
五 MapReduce & YARN 的部署
5.1 部署说明
Hadoop HDFS分布式文件系统,会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNamenode作为辅助
Hadoop YARN分布式资源调度,会启动: - ResourceManager进程作为管理节点
- NodeManager进程作为工作节点
- ProxyServer、JobHistoryServer两个辅助节点
MapReduce运行在YARN容器内,无需启动独立进程
关于MapReduce和YARN的部署,其实就是2件事情:
- 关于MapReduce: 修改相关配置文件,但是没有进程可以启动
- 关于YARN: 修改相关配置文件, 并启动ResourceManager、NodeManager进程以及辅助进程(代理服务器、历史服务器)
- 表格汇总

5.2 集群规划

5.3 MapReduce配置文件
在$HADOOP_HOME/etc/hadoop文件夹内,修改:
-
mapred-env.sh文件,添加如下环境变量# 设置JDK路径 export JAVA_HOME=/export/server/jdk8 # 设置JobHistoryServer进程内存为1G export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000 # 设置日志级别为INFO export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA -
mapred-site.xml文件,添加如下配置信息:<property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce的运行框架设置为YARN</description></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description>历史服务器通讯端口为node1:10020</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description>历史服务器web端口为nodel的19888</description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息在HDFS的记录临时路径</description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息在HDFS的记录路径</description></property> <property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description> </property> <property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description> </property> <property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description> </property> -
yarn-env.sh文件,添加如下4行环境变量内容:#设置JDK路径的环境变量 export JAVA_HOME=/export/server/jdk8 #设置HADOOPHOME的环境变量 export HADOOP_HOME=/export/server/hadoop #设置配置文件路径的环境变量 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #设置日志文件路径的环境变量 export HADOOP_LOG_DIR=$HADOOP_HOME/logs -
yarn-site.xml文件,修改内容<configuration><!-- 核心配置 --><property><name>yarn.resourcemanager.hostname</name><value>node1</value><description>>ResourceManager设置在nodel节点</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>NodeManager中间数据本地存储路径</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>NodeManager中间数据本地存储路径</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce程序开启Shuf fle服务</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description></property><!-- 额外配置 --> <property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description>历史服务器URL</description> </property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚合</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志HDFS的存储路径</description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度器</description></property> </configuration>
5.4 分发配置文件
- MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/ scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/ - 分发完成配置文件,就可以启动YARN的相关进程
5.5 集群启动命令
常用的进程启动命令如下:
- 一键启动YARN集群:
$HADOOP_HOME/sbin/start-yarn.sh- 会基于
yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager - 会基于
workers文件配置的主机启动NodeManager
- 会基于
- 一键停止YARN集群:
$HADOOP_HOME/sbin/stop-yarn.sh - 在当前机器,单独启动或停止进程
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver- start和stop决定启动和停止
- 可控制resourcemanager、nodemanager、proxyserver三种进程
- 历史服务器启动和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
5.6 开始启动YARN集群
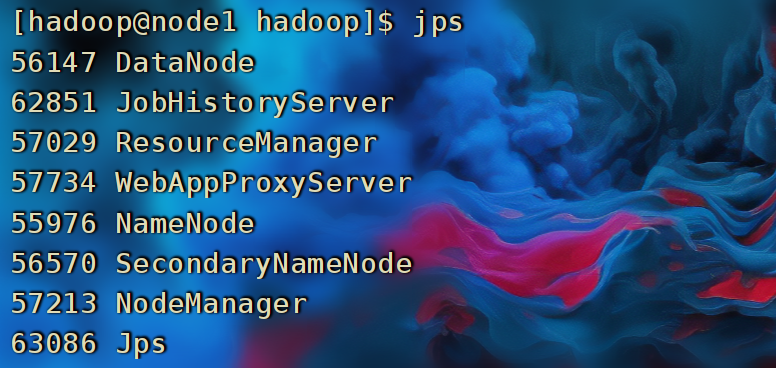
在node1服务器,以hadoop用户执行
- 首先执行:
$HADOOP_HOME/sbin/start-yarn.sh,一键启动所需的:ResourceManager、NodeManager、ProxyServer(代理服务器) - 其次执行:
$HADOOP_HOME/bin/mapred --daemon start historyserver启动:HistoryServer(历史服务器)
- 查看YARN的WEB UI页面
- 打开 http://node1:8088 即可看到YARN集群的监控页面(ResourceManager的WEB UI)
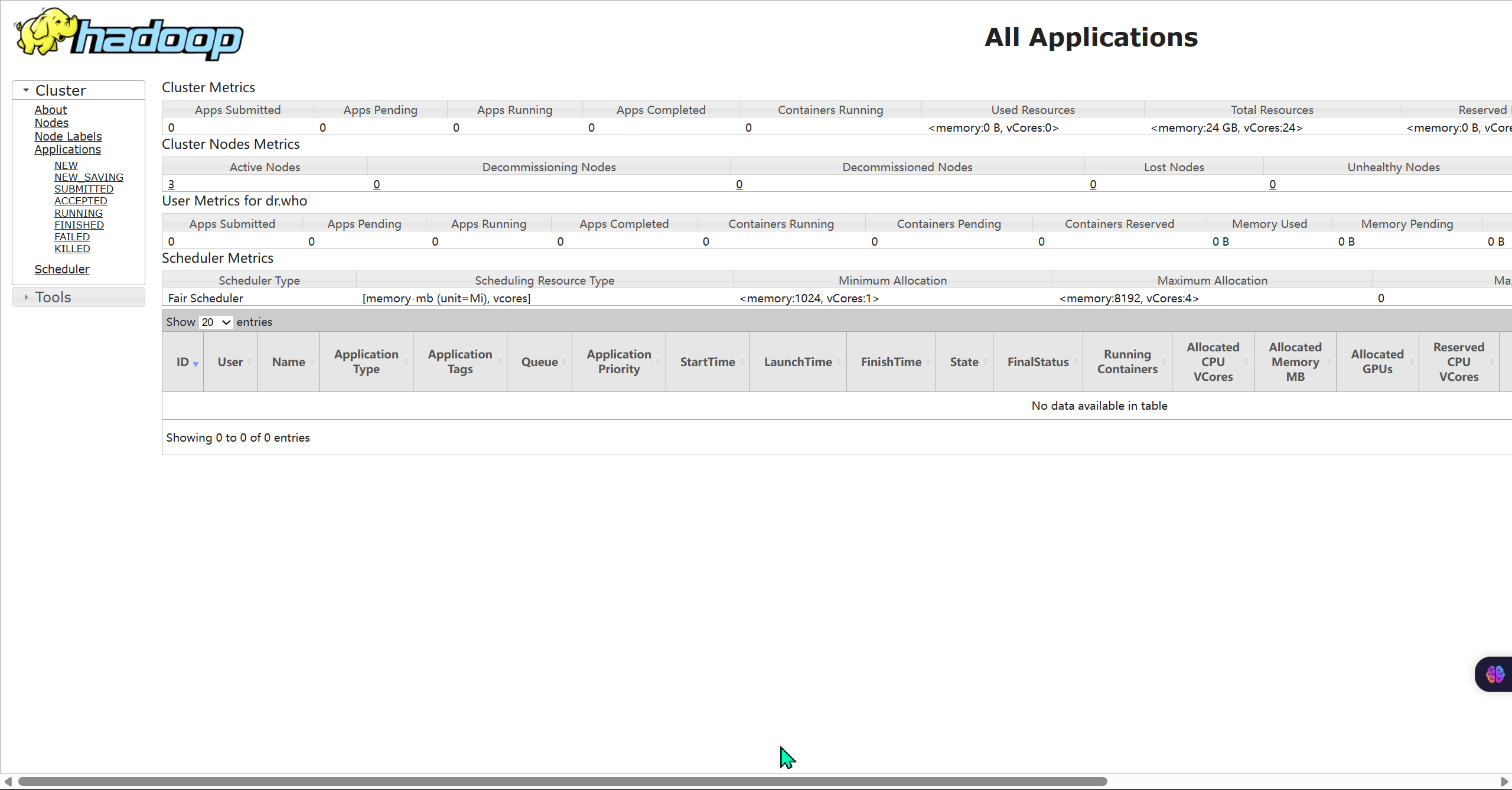
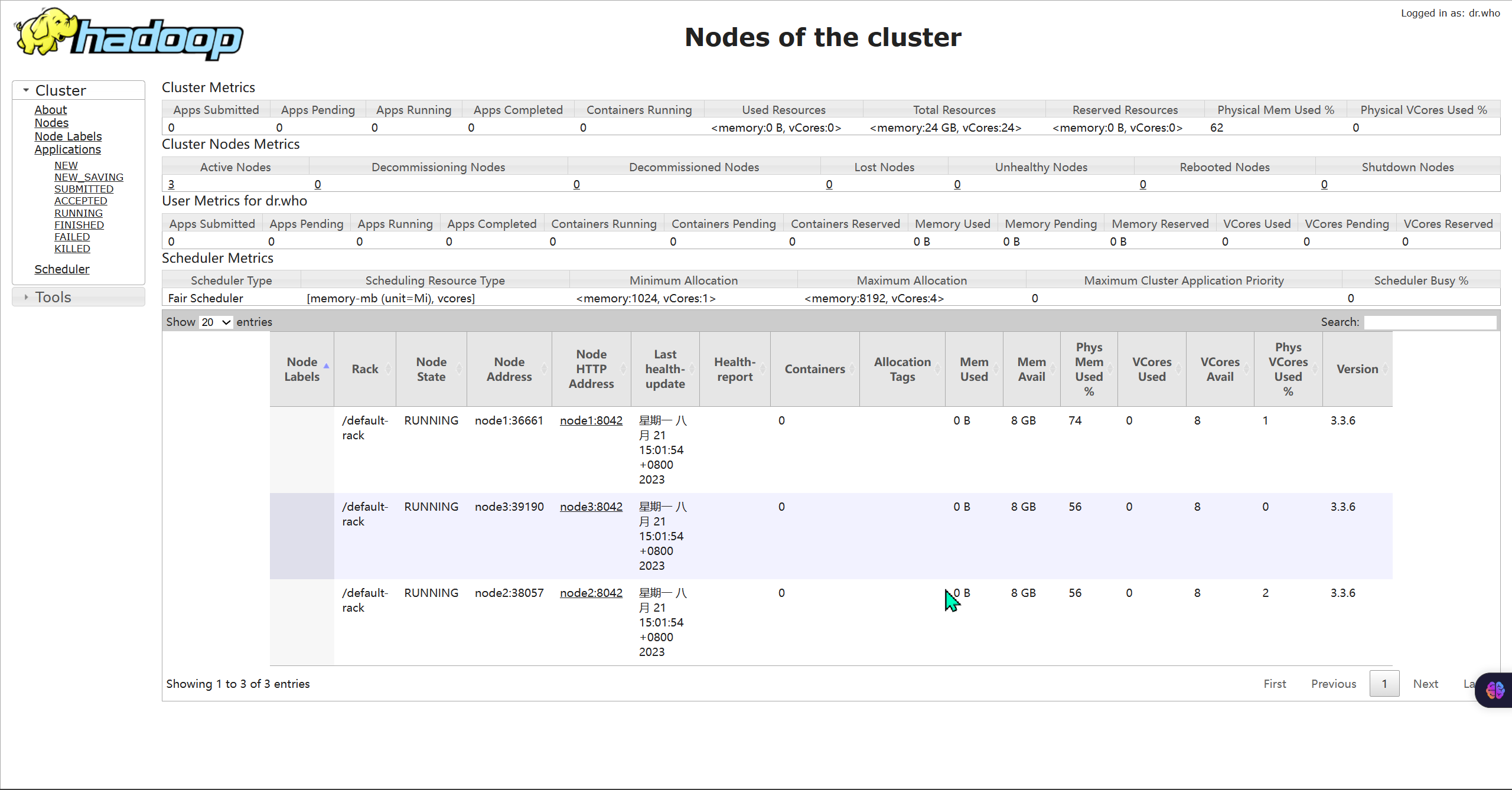
- 打开 http://node1:8088 即可看到YARN集群的监控页面(ResourceManager的WEB UI)
- 最后,可以给虚拟机打上快照,保存安装状态
六 MapReduce & YARN 初体验
6.1 集群启停命令
6.1.1 一键启动脚本
- 启动:
$HADOOP_HOME/sbin/start-yarn.sh- 从yarn-site.xml中读取配置,确定ResourceManager所在机器,并启动它
- 读取workers文件,确定机器,启动全部的NodeManager
- 在当前机器启动ProxyServer(代理服务器)
- 关闭:
$HADOOP_HOME/sbin/stop-yarn.sh
6.1.2 单进程启停
- 控制单独控制进程的启停。
$HADOOP_HOME/bin/yarn单独控制所在机器的进程的启停- 用法:
yarn --daemon (start|stop) (resourcemanager|nodemanager|proxyserver)$HADOOP_HOME/bin/mapred,单独控制所在机器的历史服务器的启停- 用法:
mapred --daemon (start|stop) historyserver
6.2 提交MapReduce任务到YARN执行
-
在部署并成功启动YARN集群后,就可以在YARN上运行各类应用程序了。
-
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:MapReduce程序、Spark程序、Flink程序
-
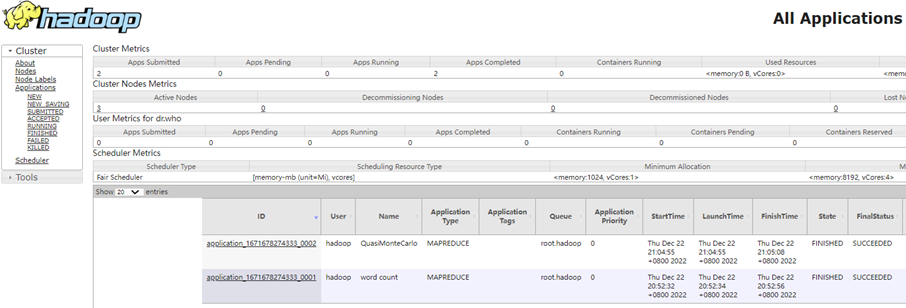
Hadoop官方内置了一些预置的MapReduce程序代码,无需编程,只需要通过命令即可使用。
常用的有2个MapReduce内置程序: -
wordcount:单词计数程序。 【统计指定文件内各个单词出现的次数】
-
pi:求圆周率【通过蒙特卡罗算法(统计模拟法)求圆周率】
- 这些内置的示例MapReduce程序代码,都在:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar这个文件内。
- 可以通过
hadoop jar命令来运行它,提交MapReduce程序到YARN中。
语法:hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
6.2.1 提交wordcount示例程序
- 单词计数示例程序的功能很简单:
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
- 准备一份数据文件,并上传到HDFS中。
- 将以下内容保存到Linux中为words.txt文件,并上传到HDFS
itheima itcast itheima itcast hadoop hdfs hadoop hdfs hadoop mapreduce hadoop yarn itheima hadoop itcast hadoop itheima itcast hadoop yarn mapreduce
hadoop fs -mkdir -p /input/wordcount
hadoop fs -mkdir /output
hadoop fs -put words.txt /input/wordcount/
- 执行如下命令,提交示例MapReduce程序WordCount到YARN中执行
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount hdfs://node1:8020/input hdfs://node1:8020/output/wc1
注意:
- 参数wordcount,表示运行jar包中的单词计数程序(Java Class)
- 参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
- 参数2是结果输出路径(hdfs://node1:8020/output/wc1), 需要确保输出的文件夹不存在
- 提交程序后,可以在YARN的WEB UI页面看到运行中的程序(http://node1:8088/cluster/apps)
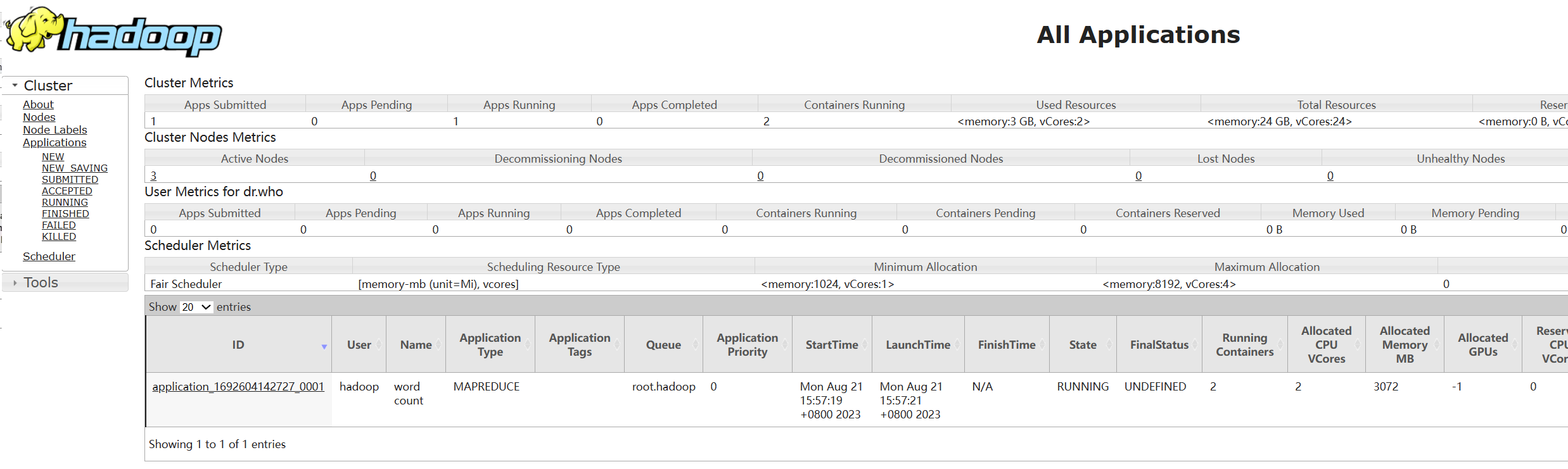
- 执行完成后,可以查看HDFS上的输出结果
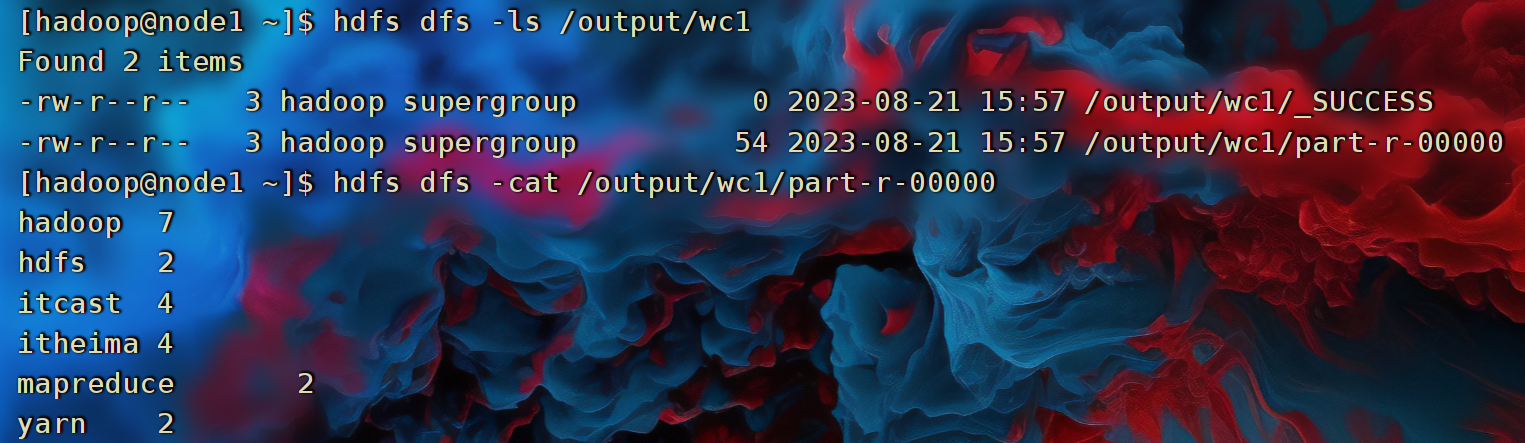
- _SUCCESS文件是标记文件,表示运行成功,本身是空文件
- part-r-00000,是结果文件,结果存储在以part开头的文件中
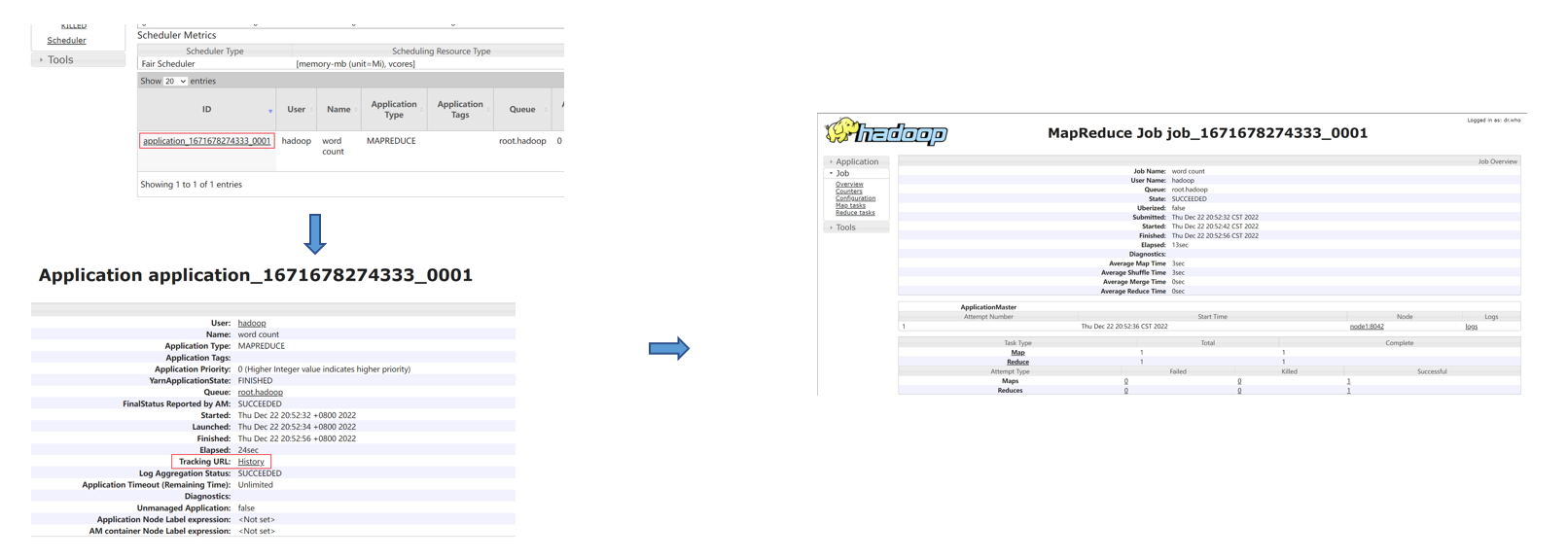
- 执行完成后,可以借助历史服务器查看到程序的历史运行信息
6.2.2 查看运行日志
点击logs链接,可以查看到详细的运行日志信息。
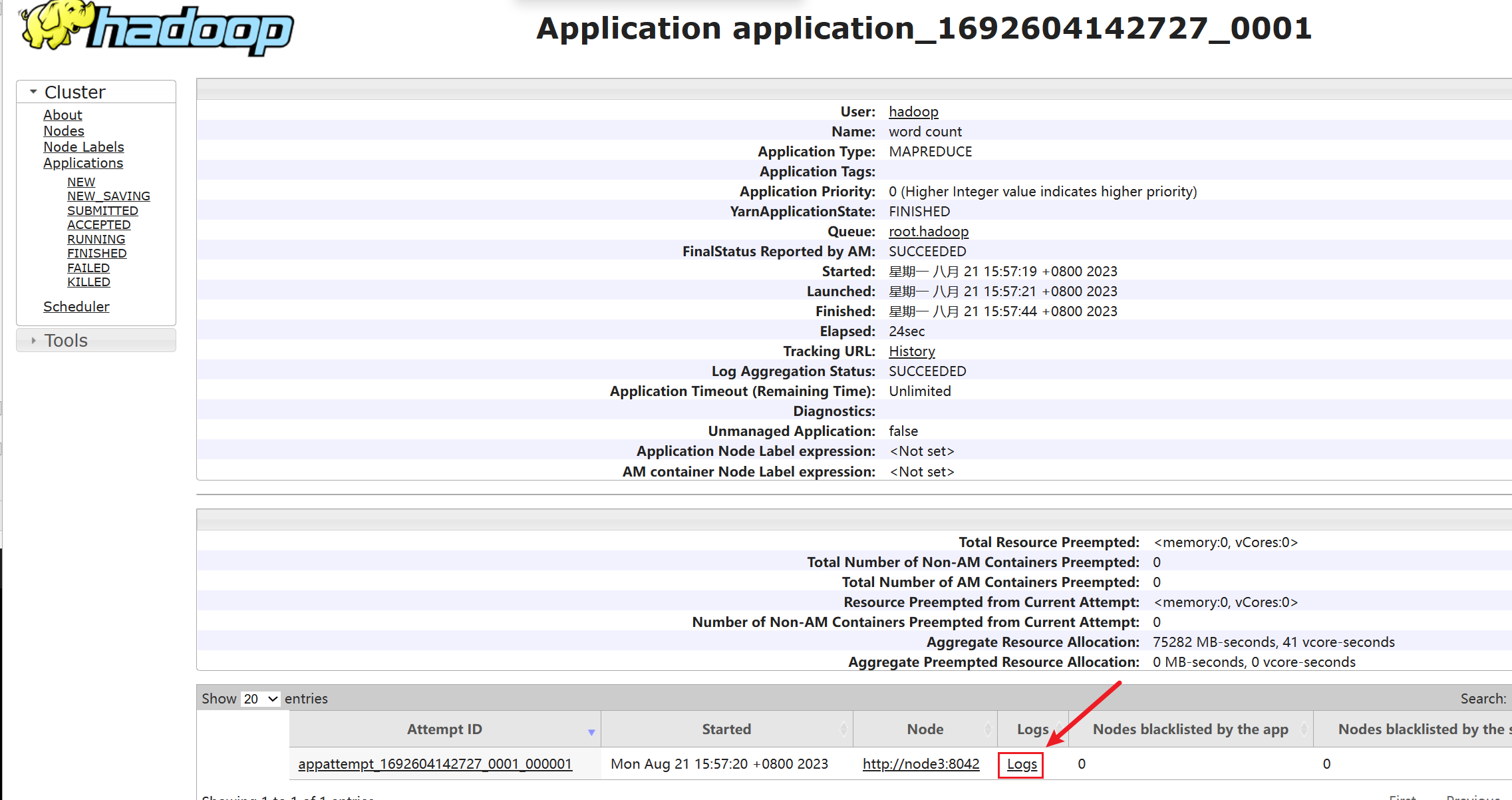
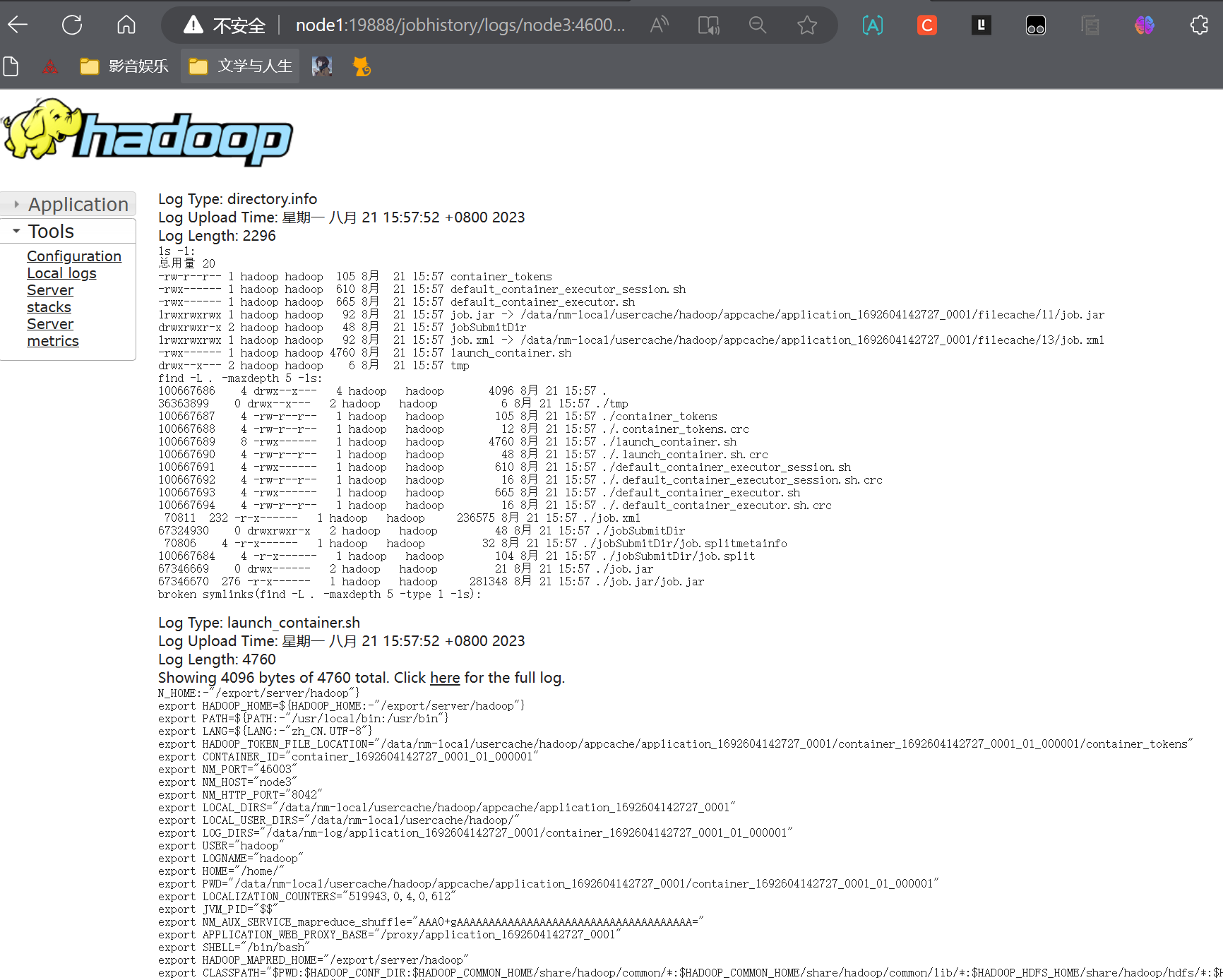
此功能基于:
- 配置文件中配置了日志聚合功能,并设置了历史服务器
- 启动了代理服务器和历史服务器
- 历史服务器进程会将日志收集整理,形成可以查看的网页内容供我们查看。
6.2.3 提交求圆周率示例程序
- 可以执行如下命令,使用蒙特卡罗算法模拟计算求PI(圆周率)
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 100000- 参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
- 参数3,表示设置几个map任务
- 参数1000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)

6.3 补充:蒙特卡罗算法求PI的基础原理
- Monte Carlo算法的基本思想是: 以模拟的”实验”形式、以大量随机样本的统计形式,来得到问题的求解。
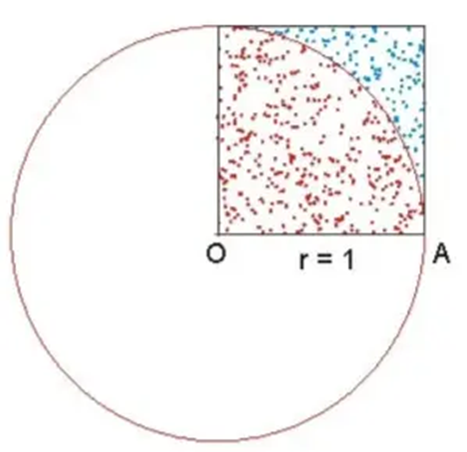
- 如图,我们在正方形内,随机落点统计落在1/4圆内的点和总点数量的比例即可得到1/4的PI,最终乘以4即可得到PI
- 比如,红色点的数量比全部点的数量,结果是0.765,那么乘以四可以得到3.06。3.06就是求得的PI所以,此方法,需要大量的样本(落点),样本越多越精准
- 以Python语言实现的蒙特卡罗求PI
