福建微网站建设公司2021百度最新收录方法
写在前面:
首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
在https://blog.csdn.net/AugustMe/article/details/128969138文章中,我们使用了基于PyTorch搭建LSTM实现MNIST手写数字体识别,LSTM是单向的,现在我们使用双向LSTM试一试效果,和之前的单向LSTM模型稍微有差别,请注意查看代码的变化。
1.导入依赖库
这些依赖库是必须导入的,用于后续代码的构建:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
依赖库的版本信息:
torch: 1.8.0+cpu
numpy: 1.19.3
matplotlib: 3.2.1
pillow: 7.2.0
2.数据集
训练模型肯定少不了数据集,本教程使用我们以比较熟悉的 mnist 数据集,该数据集是手写数字数据集,每一张图片得大小为28×28,训练集60000张,测试集10000张,mnist数据集下载代码如下:
# 训练集
train_data = datasets.MNIST(root="./", # 存放位置train = True, # 载入训练集transform=transforms.ToTensor(), # 把数据变成tensor类型download = True # 下载)
# 测试集
test_data = datasets.MNIST(root="./",train = False,transform=transforms.ToTensor(),download = True)
这个mnist下载成功与否,还和你的网络有关系,有时候网络不好,可能会导致下载失败。如果你下载不下来,可以联系我,我将数据集打包发给你。
下载得到的数据集存放如下:

3.数据导入
数据下载成功后,加载下载得到的数据集,核心代码如下:
# 批次大小
batch_size = 32
# 装载训练集
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
# 装载测试集
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
我们查看一下数据集中的图片,核心代码为:
# batch_size设为 1 时查看
for i, data in enumerate(train_loader):inputs, labels = dataprint(inputs.shape)print(labels.shape)img = inputs.view((28,28))print(img.shape)# plt.imshow(img)plt.imshow(img, cmap='gray')break
plt.imshow(img, cmap=‘gray’)

plt.imshow(img):
4.双向LSTM网络
Long Short-Term Memory (LSTM) 是一种特殊的循环神经网络,它能够处理较长的序列,并且能够记忆长期的依赖关系。LSTM 的结构包括输入门、输出门、遗忘门和记忆细胞,它们共同组成了一个“门控循环单元”,可以控制信息的流动,从而实现长期依赖关系的学习。LSTM 在自然语言处理、语音识别、机器翻译等领域有着广泛的应用。
基于pytorch深度学习框架搭建LSTM网络模型,使用了双向LSTM,一层:
这里面模型和之前的文章稍有不同,注意 output,(h_n,c_n)三个值的输出。
# 定义网络结构
class LSTM(nn.Module):def __init__(self):super(LSTM,self).__init__() # 初始化self.lstm = nn.LSTM(input_size = 28, # 表示输入特征的大小hidden_size = 64, # 隐藏层的特征维度num_layers = 1, # 表示lstm隐藏层的层数batch_first = True, # lstm默认格式input(seq_len,batch,feature)# 等于True表示input和output变成(batch,seq_len,feature)bidirectional = True # True则为双向lstm默认为False)self.out = torch.nn.Linear(in_features=64*2, out_features=10)self.softmax = torch.nn.Softmax(dim=1) # 映射到0-1之间def forward(self,x):# (batch, seq_len, feature)x = x.view(-1, 28, 28)# output:(batch,seq_len,hidden_size)包含每个序列的输出结果# 虽然lstm的batch_first为True,但是h_n,c_n的第0个维度还是num_layers# h_n :[num_layers,batch,hidden_size]只包含最后一个序列的输出结果# c_n:[num_layers,batch,hidden_size]只包含最后一个序列的输出结果output,(h_n,c_n) = self.lstm(x) # x输入到lstmoutput_in_last_timestep = output[:,-1,:] # 获取下一个输入x = self.out(output_in_last_timestep) # 输入到outx = self.softmax(x) # 输入到softmaxreturn x
特别说明:
LSTM中存在维度的变化,一定要注意,下面以实例进行讲解,请看下面的代码和注释。
h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。output[:,-1,:]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息,output与h_n的关系。
实验代码,仅供参考:
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 10 15:25:40 2023@author: augustqi维度变化:
https://blog.csdn.net/qq_54867493/article/details/128790652
"""import torch
import torch.nn as nninput_x = torch.randn(1, 28, 28)
print(input_x.shape)input_x_ = input_x.view(-1, 28, 28)
print(input_x_.shape)lstm = nn.LSTM(input_size = 28, # 输入数据的特征维数,通常就是embedding_dim(词向量的维度)hidden_size = 64, # 隐藏层的特征维度num_layers = 1, # 表示lstm循环神经网络的层数batch_first = True, # lstm默认格式input(seq_len,batch,feature)# 等于True表示input和output变成(batch,seq_len,feature)bidirectional = True # True则为双向lstm默认为False)linear = torch.nn.Linear(in_features=64*2, out_features=10)softmax = torch.nn.Softmax(dim=1)output, (h_n, c_n) = lstm(input_x_)'''
output的维度:(batch, seq_len, num_directions*hidden_size)
hn的维度:(num_directions*num_layer, batch_size, hidden_size)
cn的维度:同hn
'''print(output)
# 如果bidirectional=True, num_directions=2; 如果bidirectional=False, num_directions=1
print(output.shape) # [seq_length, batch_size, num_directions * hidden_size]print(output[:,-1,:])
print(output[:,-1,:].shape)print(h_n)
print(h_n.shape) # [num_directions * num_layers, batch, hidden_size]print(c_n)
print(c_n.shape) # c_n.shape = h_n.shapeprint(h_n[-1,:,:])
print(h_n[-1,:,:].shape) linear_out = linear(h_n[-1,:,:])softmax_out = softmax(linear_out)linear_out_2 = linear(output[:,-1,:])
softmax_out_2 = softmax(linear_out_2)"""
h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,
所以它们都与句子的长度seq_length无关。
output[:,-1,:]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,
注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息,output与h_n的关系。"""
5.模型训练
训练代码如下,主要包括定义模型、定义损失函数、定义优化器,训练时的超参数,详情如下:
# 定义模型
model = LSTM()
# 定义代价函数
mse_loss = nn.CrossEntropyLoss() # 交叉熵
# 定义优化器
optimizer = optim.Adam(model.parameters(),lr=0.001) # AdamEpoch = 30
loss_train_list = []
loss_test_list = []
# 训练
for epoch in range(Epoch):# 模型的训练状态model.train()correct_train = 0loss_train = 0for i, data in enumerate(train_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# 获得最大值,以及最大值所在的位置_, predicted = torch.max(out, 1)# 预测正确的数量correct_train += (predicted==labels).sum()# 交叉熵代价函数out(batch,C:类别的数量),labels(batch)loss = mse_loss(out, labels)loss_train += loss.item() # loss.data, tensor(1.4612)# 梯度清零optimizer.zero_grad()# 计算梯度loss.backward()# 修改权值optimizer.step() loss_train_list.append(loss_train/len(train_data))print("Epoch:{}/{}, Train acc:{:.4f}, Loss:{:.6f}".format(epoch+1, Epoch, (correct_train.item()/len(train_data)), (loss_train/len(train_data))))
6.模型测试
每训练完一个epoch,就使用测试集测试一下模型,输出测试精度和损失情况:
# 模型的测试状态
model.eval()
correct_test = 0 # 测试集准确率
loss_test = 0
for i, data in enumerate(test_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# 获得最大值,以及最大值所在的位置_,predicted = torch.max(out, 1)# 预测正确的数量correct_test += (predicted==labels).sum()loss = mse_loss(out, labels)loss_test += loss.item() # loss.data, tensor(1.4612)loss_test_list.append(loss_test/len(test_data))
print("Test acc:{:.4f}, Loss:{:.6f}".format(correct_test.item()/len(test_data), loss_test/len(test_data)))
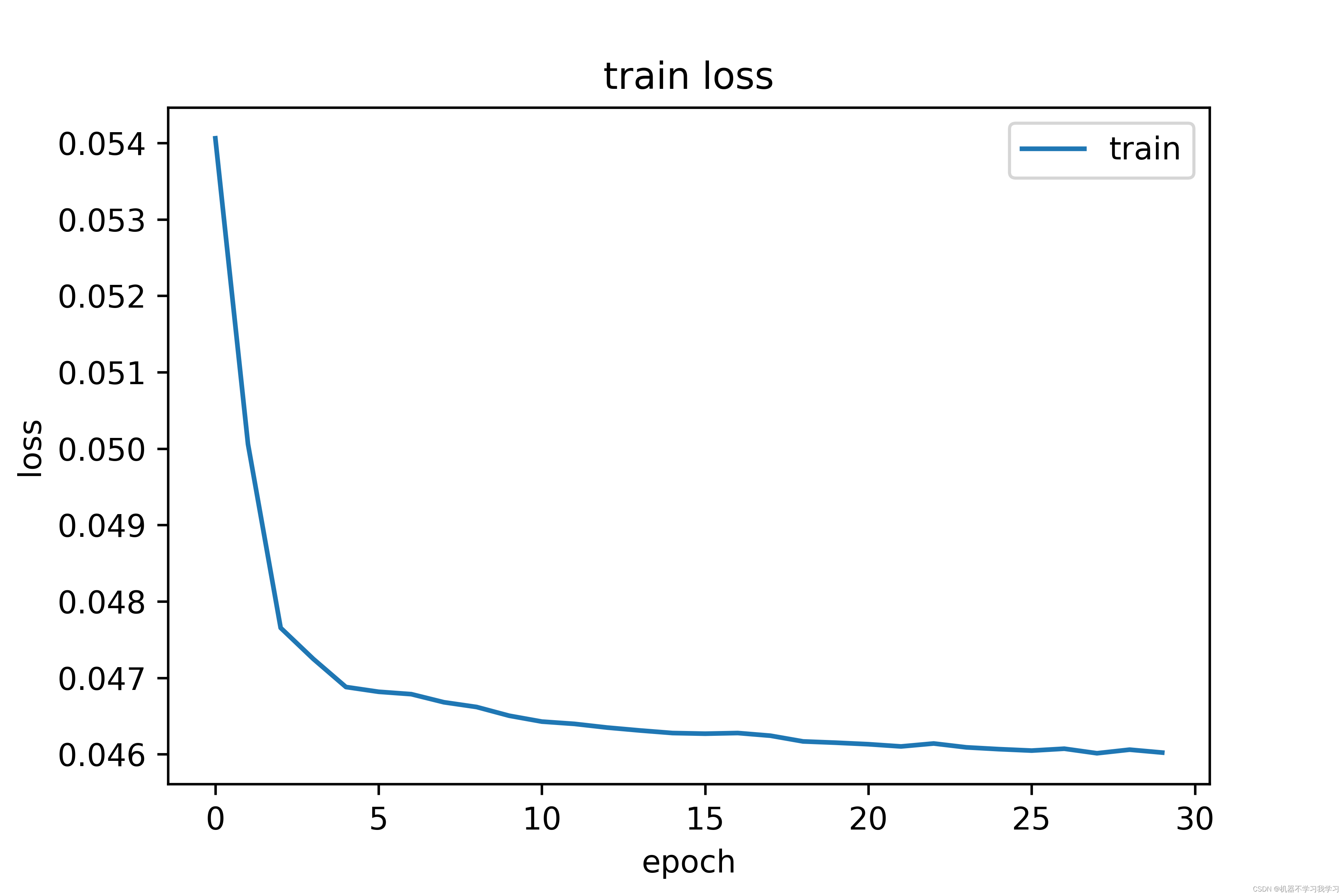
7.损失可视化
训练30个epoch,终端输出情况:
Epoch:1/30, Train acc:0.7438, Loss:0.054061
Test acc:0.8521, Loss:0.050427
Epoch:2/30, Train acc:0.8615, Loss:0.050059
Test acc:0.9322, Loss:0.047967
Epoch:3/30, Train acc:0.9387, Loss:0.047655
Test acc:0.9546, Loss:0.047182
Epoch:4/30, Train acc:0.9506, Loss:0.047248
Test acc:0.9618, Loss:0.046989
Epoch:5/30, Train acc:0.9620, Loss:0.046881
Test acc:0.9593, Loss:0.047013
Epoch:6/30, Train acc:0.9638, Loss:0.046818
Test acc:0.9630, Loss:0.046920
Epoch:7/30, Train acc:0.9647, Loss:0.046787
Test acc:0.9664, Loss:0.046818
Epoch:8/30, Train acc:0.9680, Loss:0.046681
Test acc:0.9700, Loss:0.046682
Epoch:9/30, Train acc:0.9698, Loss:0.046619
Test acc:0.9686, Loss:0.046729
Epoch:10/30, Train acc:0.9736, Loss:0.046505
Test acc:0.9710, Loss:0.046664
Epoch:11/30, Train acc:0.9761, Loss:0.046428
Test acc:0.9711, Loss:0.046657
Epoch:12/30, Train acc:0.9768, Loss:0.046398
Test acc:0.9771, Loss:0.046465
Epoch:13/30, Train acc:0.9784, Loss:0.046350
Test acc:0.9783, Loss:0.046434
Epoch:14/30, Train acc:0.9796, Loss:0.046312
Test acc:0.9773, Loss:0.046442
Epoch:15/30, Train acc:0.9809, Loss:0.046278
Test acc:0.9794, Loss:0.046393
Epoch:16/30, Train acc:0.9808, Loss:0.046270
Test acc:0.9789, Loss:0.046409
Epoch:17/30, Train acc:0.9807, Loss:0.046278
Test acc:0.9766, Loss:0.046474
Epoch:18/30, Train acc:0.9816, Loss:0.046243
Test acc:0.9793, Loss:0.046388
Epoch:19/30, Train acc:0.9840, Loss:0.046169
Test acc:0.9799, Loss:0.046367
Epoch:20/30, Train acc:0.9846, Loss:0.046152
Test acc:0.9823, Loss:0.046316
Epoch:21/30, Train acc:0.9853, Loss:0.046132
Test acc:0.9833, Loss:0.046268
Epoch:22/30, Train acc:0.9862, Loss:0.046103
Test acc:0.9814, Loss:0.046317
Epoch:23/30, Train acc:0.9850, Loss:0.046141
Test acc:0.9804, Loss:0.046343
Epoch:24/30, Train acc:0.9865, Loss:0.046091
Test acc:0.9815, Loss:0.046316
Epoch:25/30, Train acc:0.9873, Loss:0.046067
Test acc:0.9833, Loss:0.046262
Epoch:26/30, Train acc:0.9879, Loss:0.046048
Test acc:0.9813, Loss:0.046331
Epoch:27/30, Train acc:0.9870, Loss:0.046073
Test acc:0.9837, Loss:0.046250
Epoch:28/30, Train acc:0.9891, Loss:0.046014
Test acc:0.9830, Loss:0.046271
Epoch:29/30, Train acc:0.9875, Loss:0.046061
Test acc:0.9821, Loss:0.046299
Epoch:30/30, Train acc:0.9888, Loss:0.046023
Test acc:0.9815, Loss:0.046324
训练集上损失曲线图:
测试集上损失曲线图:
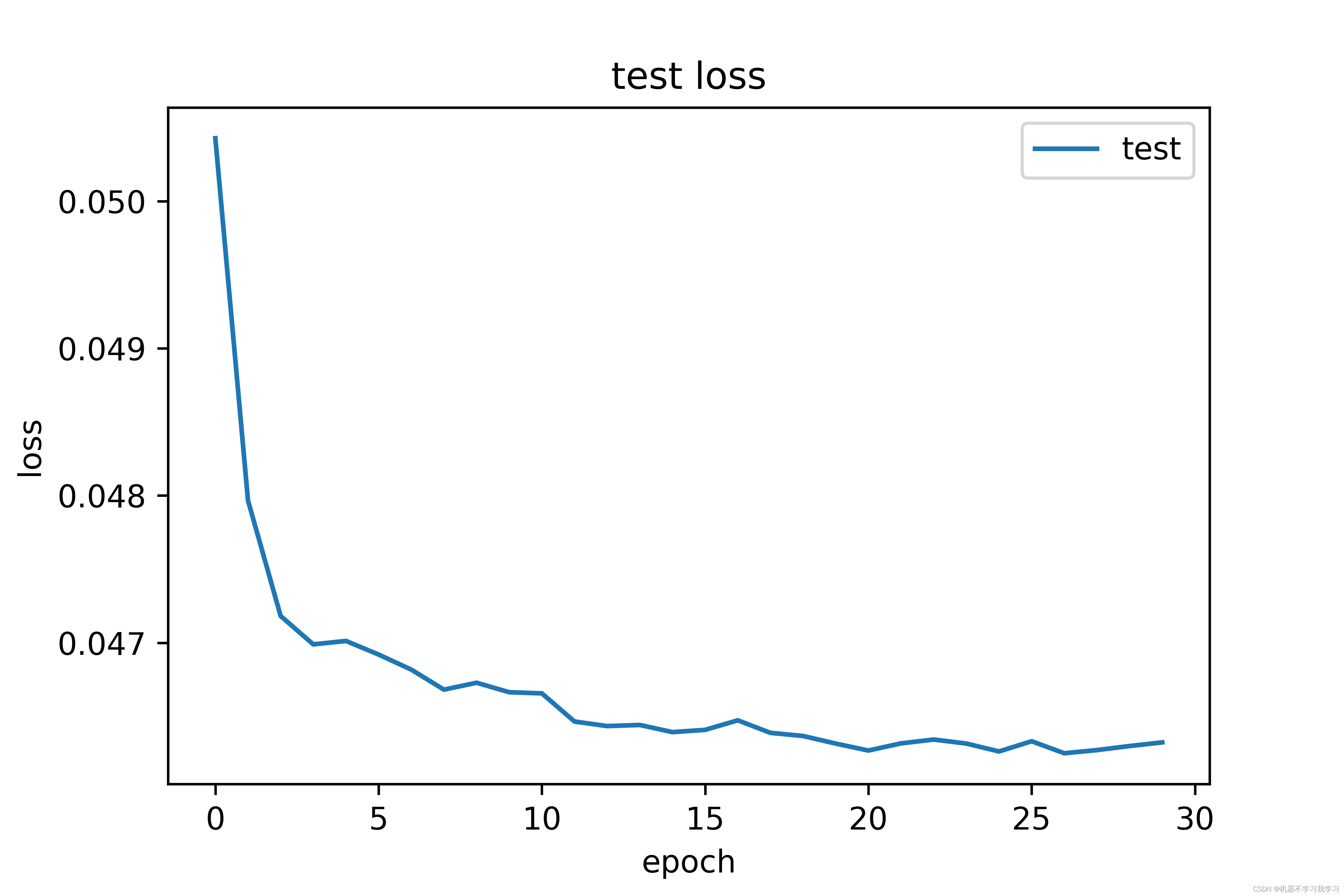
训练30个epoch后,模型在测试集上的精度达到98.15%,效果还不错。训练集上的损失和测试集上的损失都在下降并逐渐收敛。
参考资料
1.https://blog.csdn.net/AugustMe/article/details/128969138