沧州市做网站的宁波seo关键词优化报价
前言
以下内容均来源于官方教程:简单的音频识别:识别关键字
音频识别
下载数据集
下载地址:http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip
可以直接浏览器访问下载。
下载完成后将其解压到项目里,从文件夹里可以看到有8个子文件夹,文件夹的名称就是8个语音命令。
注意:我们只需要mini_speech_commands文件夹,其他的不需要
加载数据集
# 加载训练数据集、验证集
train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(directory='./data/mini_speech_commands', # 数据集路径batch_size=64, # 批次validation_split=0.2, # 验证集占数据集的20%seed=0, # 指定随机生成数据集的种子# 每个样本的输出序列长度。音频剪辑在 1kHz 时为 16 秒或更短。将较短的填充到正好 1 秒(并且会修剪较长的填充),以便可以轻松批量处理output_sequence_length=16000,subset='both' # 训练集和验证集两者同时使用
)
获取类别
# 获取命令的类别
label_names = np.array(train_ds.class_names)
print("命令类别:", label_names)

刚好与子文件的名称和顺序一致。
维度压缩
文档中说,此数据集仅包含单声道音频,因此需要 对输入的音频数据进行维度压缩
-
单声道(mono)音频只有一个声道。这意味着所有的音频信号被混合到一个通道中,不区分左右声道。在单声道音频中,所有的声音通过单个扬声器播放。单声道音频适用于大部分音频应用,如电话通信、语音录音等。
-
多声道(stereo)音频有两个声道,左声道(left channel)和右声道(right channel)。通过左右声道的不同信号,可以在音频空间上创建立体声效果。多声道音频提供了更加丰富的音频体验,可以更好地模拟现实环境中的声音分布。常见的应用包括音乐播放、电影声音、游戏音效等。
def squeeze(audio,labels):audio = tf.squeeze(audio,axis=-1)return audio,labelstrain_ds = train_ds.map(squeeze,tf.data.AUTOTUNE)
val_ds = val_ds.map(squeeze,tf.data.AUTOTUNE)
拆分验证集
这块没太看明白在干嘛
test_ds = val_ds.shard(num_shards=2, index=0)
val_ds = val_ds.shard(num_shards=2, index=1)
for example_audio, example_labels in train_ds.take(1):print(example_audio.shape)print(example_labels.shape)
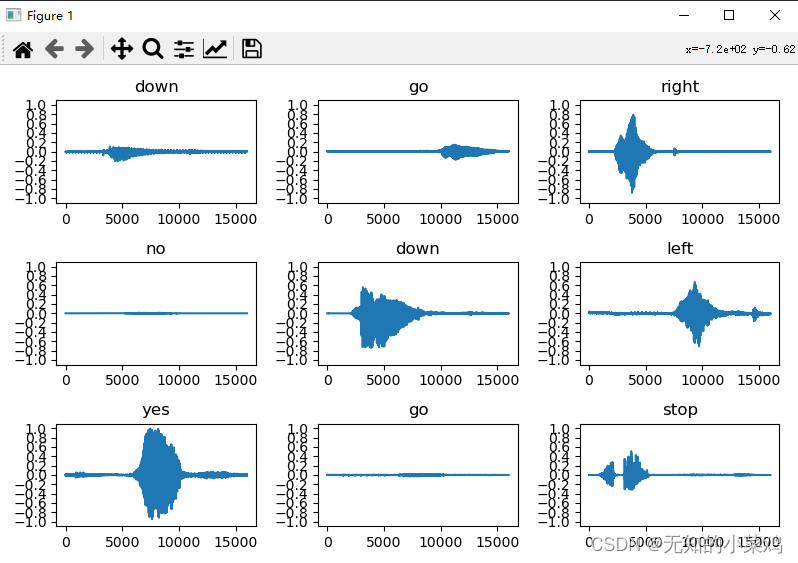
绘制音频波形
这块只是让我们可视化的观察音频的波形,这块后面可以注释掉
plt.figure(figsize=(8, 5))
rows = 3
cols = 3
n = rows * cols
for i in range(n):plt.subplot(rows, cols, i+1)audio_signal = example_audio[i]plt.plot(audio_signal)plt.title(label_names[example_labels[i]])plt.yticks(np.arange(-1.2, 1.2, 0.2))plt.ylim([-1.1, 1.1])
plt.tight_layout()
plt.show()
将波形转换为频谱图
将波形转换为频谱图的目的是为了更好地分析和理解音频信号。
波形是时域上的表示,它展示了音频信号在时间轴上的变化。然而,频谱图是频域上的表示,它将音频信号分解为不同的频率成分,并显示每个频率成分的能量或振幅。
通过将波形转换为频谱图,我们可以更清晰地看到音频信号中哪些频率成分对于特定的声音或事件是重要的。这对于音频处理任务(如语音识别、音频分类、音频分割等)以及音频信号理解和分析非常有帮助。
def get_spectrogram(waveform):spectrogram = tf.signal.stft(waveform, frame_length=255, frame_step=128)spectrogram = tf.abs(spectrogram)spectrogram = spectrogram[..., tf.newaxis]return spectrogram
浏览数据
打印一个示例的张量化波形和相应频谱图的形状,并播放原始音频:
for i in range(3):label = label_names[example_labels[i]]waveform = example_audio[i]spectrogram = get_spectrogram(waveform)print('Label:', label)print('Waveform shape:', waveform.shape)print('Spectrogram shape:', spectrogram.shape)print('Audio playback')display.display(display.Audio(waveform, rate=16000))
从音频数据集创建频谱图数据集
# 从音频数据集创建频谱图数据集
def make_spec_ds(ds):return ds.map(map_func=lambda audio,label: (get_spectrogram(audio), label),num_parallel_calls=tf.data.AUTOTUNE)train_spectrogram_ds = make_spec_ds(train_ds)
val_spectrogram_ds = make_spec_ds(val_ds)
test_spectrogram_ds = make_spec_ds(test_ds)
减少训练模型时的读取延迟
train_spectrogram_ds = train_spectrogram_ds.cache().shuffle(10000).prefetch(tf.data.AUTOTUNE)
val_spectrogram_ds = val_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
test_spectrogram_ds = test_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
使用卷积神经网络创建并训练模型
# 使用卷积神经网络创建模型
input_shape = example_spectrograms.shape[1:]
print('Input shape:', input_shape)
num_labels = len(label_names)
norm_layer = tf.keras.layers.Normalization() # 创建规范化层,便于更好的进行模型训练和推断
norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))model = tf.keras.models.Sequential([tf.keras.layers.Input(shape=input_shape),tf.keras.layers.Resizing(32, 32),norm_layer,tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.Conv2D(64, 3, activation='relu'),tf.keras.layers.MaxPool2D(),tf.keras.layers.Dropout(0.25),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(num_labels),
])model.summary()# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(), # 优化器loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数metrics=['accuracy'] # 准确率作为评估标准
)# 训练模型,并记录训练的日志
history = model.fit(train_spectrogram_ds,validation_data=val_spectrogram_ds,epochs=10,callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
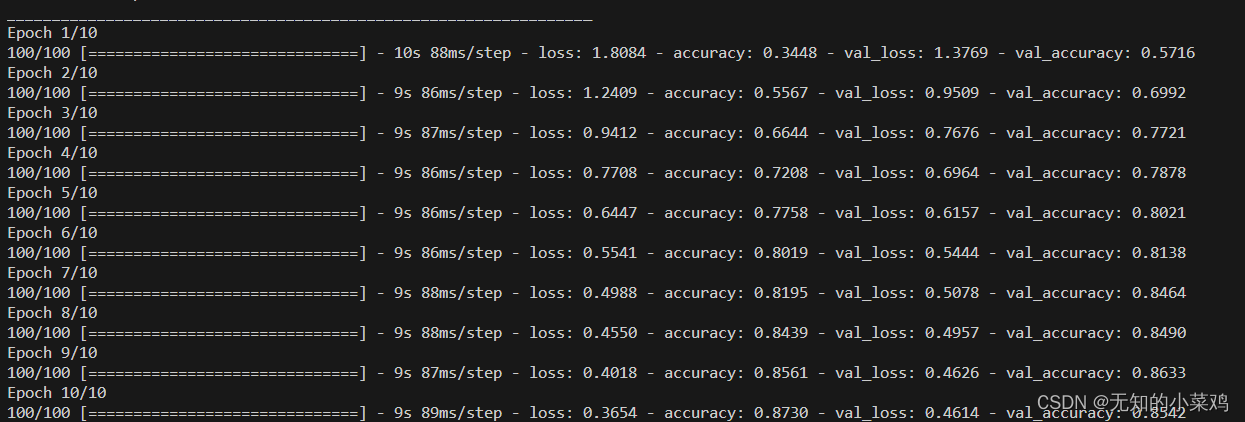
评估性能
model.evaluate(test_spectrogram_ds, return_dict=True)
导出模型
class ExportModel(tf.Module):def __init__(self, model):self.model = model# Accept either a string-filename or a batch of waveforms.# YOu could add additional signatures for a single wave, or a ragged-batch.self.__call__.get_concrete_function(x=tf.TensorSpec(shape=(), dtype=tf.string))self.__call__.get_concrete_function(x=tf.TensorSpec(shape=[None, 16000], dtype=tf.float32))@tf.functiondef __call__(self, x):# If they pass a string, load the file and decode it.if x.dtype == tf.string:x = tf.io.read_file(x)x, _ = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)x = tf.squeeze(x, axis=-1)x = x[tf.newaxis, :]x = get_spectrogram(x)result = self.model(x, training=False)class_ids = tf.argmax(result, axis=-1)class_names = tf.gather(label_names, class_ids)return {'predictions': result,'class_ids': class_ids,'class_names': class_names}export = ExportModel(model)
export(tf.constant('./data/mini_speech_commands/no/012c8314_nohash_0.wav'))tf.saved_model.save(export, "saved")
下面是保存的模型
完整代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from IPython import display# 加载训练数据集、验证集
train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(directory='./data/mini_speech_commands', # 数据集路径batch_size=64, # 批次validation_split=0.2, # 验证集占数据集的20%seed=0, # 指定随机生成数据集的种子# 每个样本的输出序列长度。音频剪辑在 1kHz 时为 16 秒或更短。将较短的填充到正好 1 秒(并且会修剪较长的填充),以便可以轻松批量处理output_sequence_length=16000,subset='both' # 训练集和验证集两者同时使用
)# 获取命令的类别
label_names = np.array(train_ds.class_names)
print("命令类别:", label_names)# 输入数据压缩def squeeze(audio, labels):audio = tf.squeeze(audio, axis=-1)return audio, labelstrain_ds = train_ds.map(squeeze, tf.data.AUTOTUNE)
val_ds = val_ds.map(squeeze, tf.data.AUTOTUNE)# 拆分验证集
test_ds = val_ds.shard(num_shards=2, index=0)
val_ds = val_ds.shard(num_shards=2, index=1)for example_audio, example_labels in train_ds.take(1):print(example_audio.shape)print(example_labels.shape)# 绘制音频波形
# plt.figure(figsize=(8, 5))
# rows = 3
# cols = 3
# n = rows * cols
# for i in range(n):
# plt.subplot(rows, cols, i+1)
# audio_signal = example_audio[i]
# plt.plot(audio_signal)
# plt.title(label_names[example_labels[i]])
# plt.yticks(np.arange(-1.2, 1.2, 0.2))
# plt.ylim([-1.1, 1.1])
# plt.tight_layout()
# plt.show()# 将波形转换为频谱图
def get_spectrogram(waveform):spectrogram = tf.signal.stft(waveform, frame_length=255, frame_step=128)spectrogram = tf.abs(spectrogram)spectrogram = spectrogram[..., tf.newaxis]return spectrogram# 浏览数据
for i in range(3):label = label_names[example_labels[i]]waveform = example_audio[i]spectrogram = get_spectrogram(waveform)print('Label:', label)print('Waveform shape:', waveform.shape)print('Spectrogram shape:', spectrogram.shape)print('Audio playback')display.display(display.Audio(waveform, rate=16000))# 从音频数据集创建频谱图数据集def make_spec_ds(ds):return ds.map(map_func=lambda audio, label: (get_spectrogram(audio), label),num_parallel_calls=tf.data.AUTOTUNE)train_spectrogram_ds = make_spec_ds(train_ds)
val_spectrogram_ds = make_spec_ds(val_ds)
test_spectrogram_ds = make_spec_ds(test_ds)# 检查数据集的不同示例的频谱图
for example_spectrograms, example_spect_labels in train_spectrogram_ds.take(1):break# 减少训练模型时的读取延迟
train_spectrogram_ds = train_spectrogram_ds.cache().shuffle(10000).prefetch(tf.data.AUTOTUNE)
val_spectrogram_ds = val_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)
test_spectrogram_ds = test_spectrogram_ds.cache().prefetch(tf.data.AUTOTUNE)# 使用卷积神经网络创建模型
input_shape = example_spectrograms.shape[1:]
print('Input shape:', input_shape)
num_labels = len(label_names)
norm_layer = tf.keras.layers.Normalization() # 创建规范化层,便于更好的进行模型训练和推断
norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))model = tf.keras.models.Sequential([tf.keras.layers.Input(shape=input_shape),tf.keras.layers.Resizing(32, 32),norm_layer,tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.Conv2D(64, 3, activation='relu'),tf.keras.layers.MaxPool2D(),tf.keras.layers.Dropout(0.25),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(num_labels),
])model.summary()# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(), # 优化器loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数metrics=['accuracy'] # 准确率作为评估标准
)# 训练模型,并记录训练的日志
history = model.fit(train_spectrogram_ds,validation_data=val_spectrogram_ds,epochs=10,callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)# 评估性能
model.evaluate(test_spectrogram_ds, return_dict=True)# 导出模型class ExportModel(tf.Module):def __init__(self, model):self.model = modelself.__call__.get_concrete_function(x=tf.TensorSpec(shape=(), dtype=tf.string))self.__call__.get_concrete_function(x=tf.TensorSpec(shape=[None, 16000], dtype=tf.float32))@tf.functiondef __call__(self, x):if x.dtype == tf.string:x = tf.io.read_file(x)x, _ = tf.audio.decode_wav(x, desired_channels=1, desired_samples=16000,)x = tf.squeeze(x, axis=-1)x = x[tf.newaxis, :]x = get_spectrogram(x)result = self.model(x, training=False)class_ids = tf.argmax(result, axis=-1)class_names = tf.gather(label_names, class_ids)return {'predictions': result,'class_ids': class_ids,'class_names': class_names}export = ExportModel(model)
export(tf.constant('./data/mini_speech_commands/no/012c8314_nohash_0.wav'))tf.saved_model.save(export, "saved")
加载使用导出的模型
使用模型预测down的音频
import tensorflow as tf# 直接加载模型的目录
new_model = tf.saved_model.load("./saved")
res = new_model('./data/mini_speech_commands/down/004ae714_nohash_0.wav')
print("结果:",res)class_names = ['down', 'go', 'left', 'no', 'right', 'stop', 'up', 'yes']
class_index = res['class_ids'].numpy()[0]
class_name = class_names[class_index]
print("类别名称:", class_name)
