网站名称怎样做如何提高关键词搜索排名
要解决的问题:
如何让模型知道自己做什么,是什么样身份。是谁创建了他!!!
概述
目标:通过微调,帮助模型认清了解对自己身份弟位
方式:使用XTuner进行微调
微调前(回答比较官方)
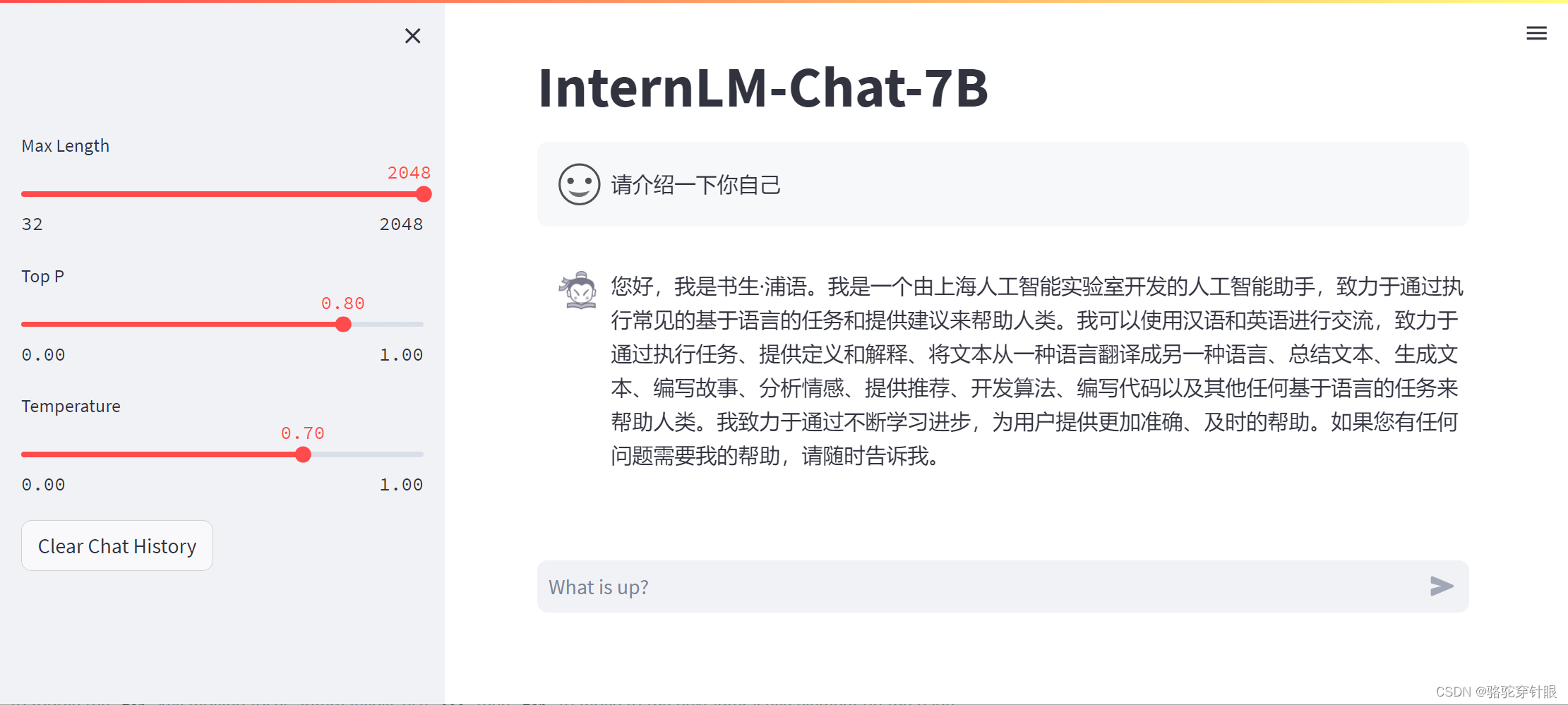
微调后(对自己的身份有了清晰的认知)
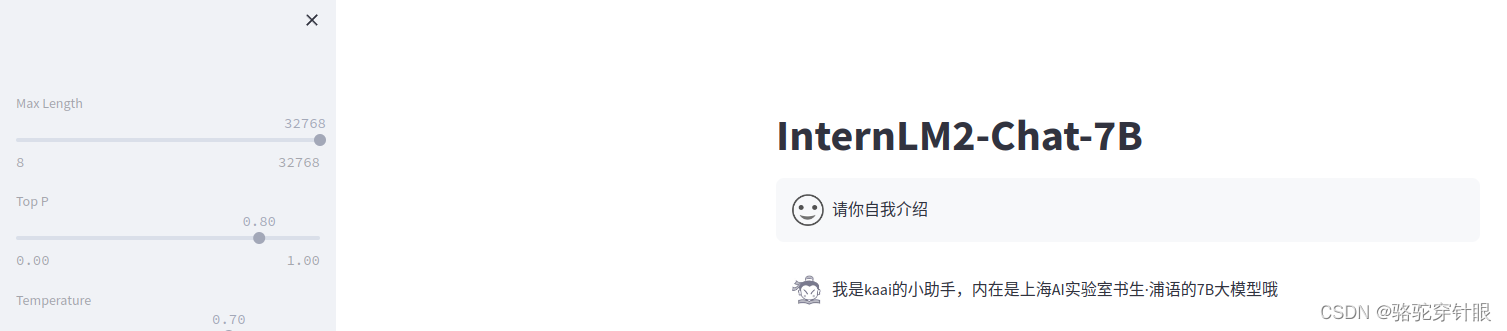
实操
# 创建自己的环境
conda create --name personal_assistant python=3.10 -y# 激活环境
conda activate personal_assistant
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
mkdir /root/personal_assistant/xtuner019 && cd /root/personal_assistant/xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
数据准备
创建data文件夹用于存放用于训练的数据集
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
其中conversation表示一次对话的内容,input为输入,即用户会问的问题,output为输出,即想要模型回答的答案
[{"conversation": [{"input": "请介绍一下你自己","output": "我是kaai的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]},{"conversation": [{"input": "请做一下自我介绍","output": "我是kaai的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]}
]
以下是一个python脚本,用于生成数据集。在data目录下新建一个generate_data.py文件,将以下代码复制进去,然后运行该脚本即可生成数据集。
import json# 输入你的名字
name = 'kaai'
# 重复次数
n = 10000# 创建初始问答数据
qa_data = [{"conversation": [{"input": "请介绍一下你自己","output": f"我是{name}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]},{"conversation": [{"input": "请做一下自我介绍","output": f"我是{name}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]}
]# 将生成的问答数据保存到JSON文件中
file_path = './qa_data_repeated.json'with open(file_path, 'w', encoding='utf-8') as file:# 使用json.dump直接写入文件,而不是先创建一个大的字符串json.dump(qa_data * n, file, ensure_ascii=False, indent=4)
下载模型InternLM-chat-7B、
Hugging Face
使用 Hugging Face 官方提供的 huggingface-cli 命令行工具。安装依赖:
pip install -U huggingface_hub
然后新建 python 文件,填入以下代码,运行即可。
- resume-download:断点续下
- local-dir:本地存储路径。(linux 环境下需要填写绝对路径)
import os# 下载模型
os.system('huggingface-cli download --resume-download internlm/internlm-chat-7b --local-dir your_path')
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
#创建用于存放配置的文件夹config并进入
mkdir /root/personal_assistant/config && cd /root/personal_assistant/config
拷贝一个配置文件到当前目录:xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} 在本例中:(注意最后有个英文句号,代表复制到当前路径)
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
修改拷贝后的文件internlm_chat_7b_qlora_oasst1_e3_copy.py,修改下述位置: (这是一份修改好的文件internlm_chat_7b_qlora_oasst1_e3_copy.py)
主要改模型的位置同时一些超参数
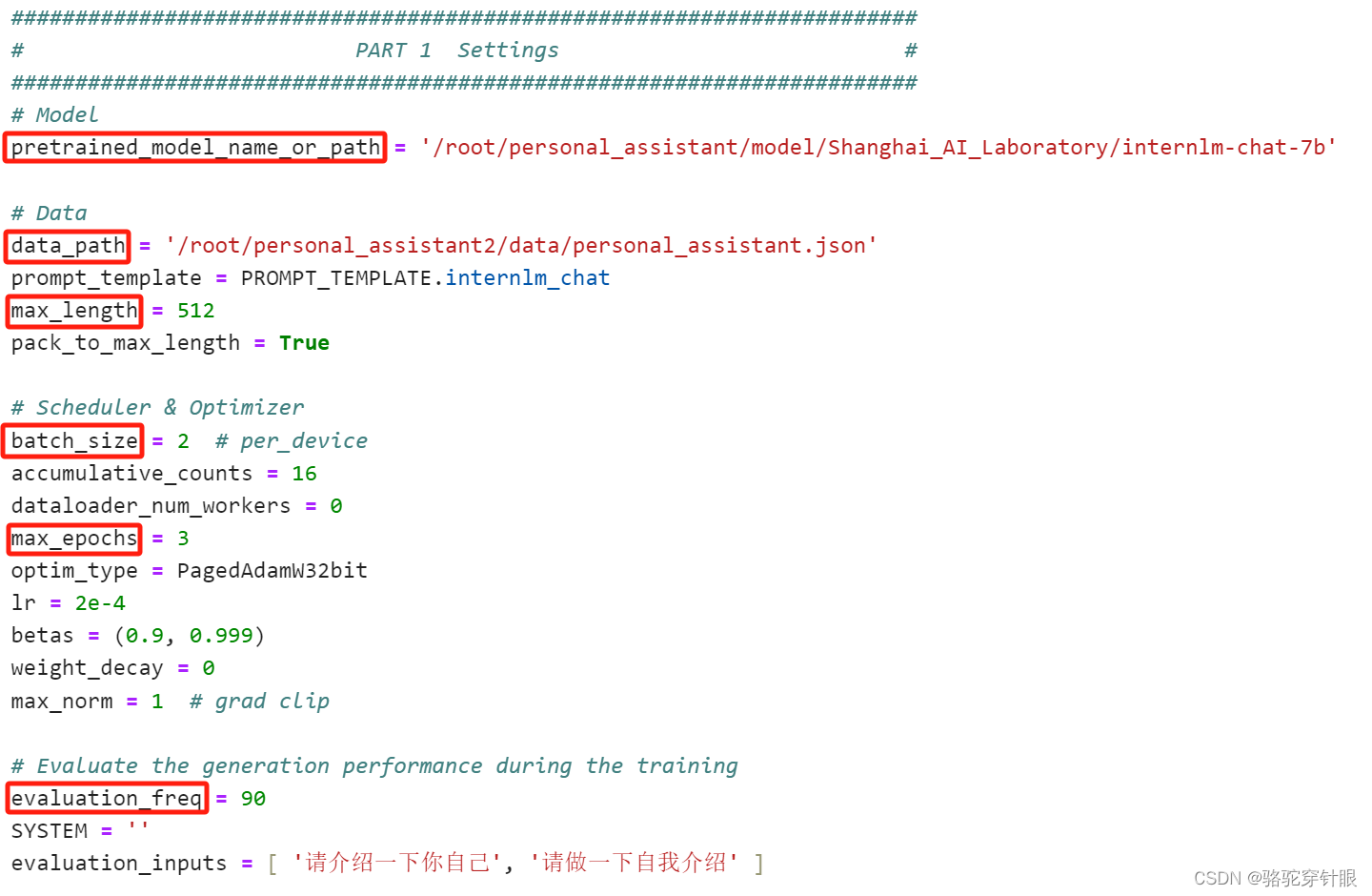
具体的内容
# PART 1 中
# 预训练模型存放的位置
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'# 微调数据存放的位置
data_path = '/root/personal_assistant/data/personal_assistant.json'# 训练中最大的文本长度
max_length = 512# 每一批训练样本的大小
batch_size = 2# 最大训练轮数
max_epochs = 3# 验证的频率
evaluation_freq = 90# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]# PART 3 中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path))
dataset_map_fn=None
微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
微调后参数转换/合并
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hfexport MKL_SERVICE_FORCE_INTEL=1# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
Merge模型参数
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER='GNU'# 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf# 最终Merge后的参数存放的位置
mkdir /root/personal_assistant/config/work_dirs/hf_merge
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge# 执行参数Merge
xtuner convert merge \$NAME_OR_PATH_TO_LLM \$NAME_OR_PATH_TO_ADAPTER \$SAVE_PATH \--max-shard-size 2GB
网页DEMO
安装网页Demo所需依赖
pip install streamlit==1.24.0
下载demo代码
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
修改代码
/mnt/xtuner/xtuner019/personal_assistant/code/InternLM/chat/web_demo.py
@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained('/mnt/xtuner/xtuner019/personal_assistant/merge',trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained('/mnt/xtuner/xtuner019/personal_assistant/merge',trust_remote_code=True)return model, tokenizer运行
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006
效果
微调前
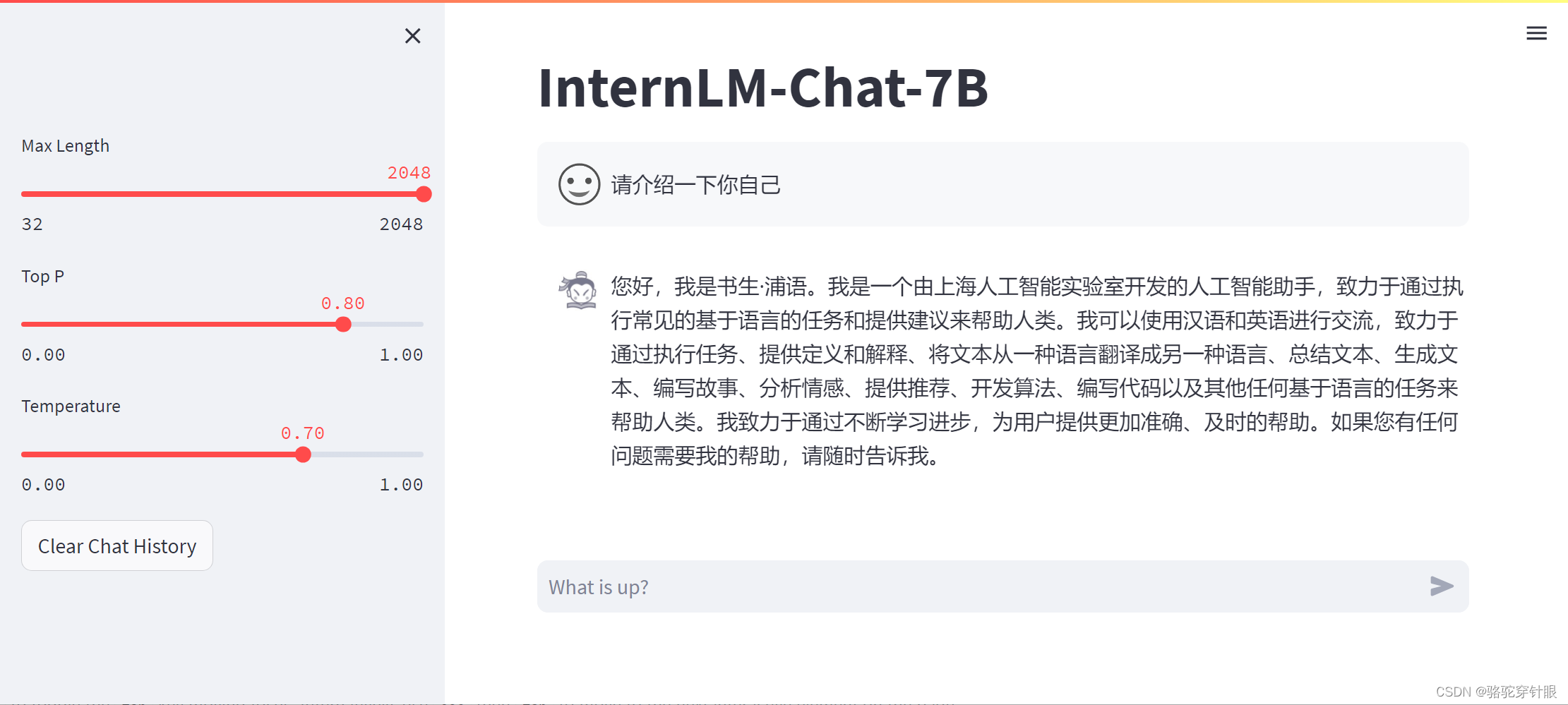
微调后(对自己的身份有了清晰的认知)
你的路径应该如下
├── code
│ └── InternLM
│ ├── agent
│ │ ├── lagent.md
│ │ ├── lagent_zh-CN.md
│ │ ├── pal_inference.md
│ │ ├── pal_inference.py
│ │ ├── pal_inference_zh-CN.md
│ │ ├── README.md
│ │ └── README_zh-CN.md
│ ├── assets
│ │ ├── compass_support.svg
│ │ ├── license.svg
│ │ ├── logo.svg
│ │ ├── modelscope_logo.png
│ │ ├── robot.png
│ │ └── user.png
│ ├── chat
│ │ ├── chat_format.md
│ │ ├── chat_format_zh-CN.md
│ │ ├── lmdeploy.md
│ │ ├── lmdeploy_zh_cn.md
│ │ ├── openaoe.md
│ │ ├── openaoe_zh_cn.md
│ │ ├── react_web_demo.py
│ │ ├── README.md
│ │ ├── README_zh-CN.md
│ │ └── web_demo.py
│ ├── finetune
│ │ ├── README.md
│ │ └── README_zh-CN.md
│ ├── LICENSE
│ ├── model_cards
│ │ ├── internlm_20b.md
│ │ ├── internlm2_1.8b.md
│ │ ├── internlm2_20b.md
│ │ ├── internlm2_7b.md
│ │ └── internlm_7b.md
│ ├── README.md
│ ├── README_zh-CN.md
│ ├── requirements.txt
│ ├── sonar-project.properties
│ ├── tests
│ │ └── test_hf_model.py
│ └── tools
│ ├── convert2llama.py
│ └── README.md
├── config
│ ├── internlm_chat_7b_qlora_oasst1_e3_copy.py
│ └── work_dirs
│ └── internlm_chat_7b_qlora_oasst1_e3_copy
│ ├── 20240223_160926
│ │ ├── 20240223_160926.log
│ │ └── vis_data
│ │ └── config.py
│ ├── 20240223_161009
│ │ ├── 20240223_161009.log
│ │ └── vis_data
│ │ └── config.py
│ ├── 20240223_161051
│ │ ├── 20240223_161051.log
│ │ └── vis_data
│ │ ├── 20240223_161051.json
│ │ ├── config.py
│ │ └── scalars.json
│ ├── epoch_1.pth
│ ├── epoch_2.pth
│ ├── epoch_3.pth
│ ├── internlm_chat_7b_qlora_oasst1_e3_copy.py
│ └── last_checkpoint
├── data
│ ├── data.py
│ ├── data_QA.py
│ └── personal_assistant.json
├── hf
│ ├── adapter_config.json
│ ├── adapter_model.safetensors
│ ├── README.md
│ └── xtuner_config.py
├── internlm-chat-7b
│ ├── config.json
│ ├── configuration_internlm.py
│ ├── configuration.json
│ ├── generation_config.json
│ ├── modeling_internlm.py
│ ├── pytorch_model-00001-of-00008.bin
│ ├── pytorch_model-00002-of-00008.bin
│ ├── pytorch_model-00003-of-00008.bin
│ ├── pytorch_model-00004-of-00008.bin
│ ├── pytorch_model-00005-of-00008.bin
│ ├── pytorch_model-00006-of-00008.bin
│ ├── pytorch_model-00007-of-00008.bin
│ ├── pytorch_model-00008-of-00008.bin
│ ├── pytorch_model.bin.index.json
│ ├── README.md
│ ├── special_tokens_map.json
│ ├── tokenization_internlm.py
│ ├── tokenizer_config.json
│ └── tokenizer.model
└── merge├── added_tokens.json├── config.json├── configuration_internlm.py├── generation_config.json├── modeling_internlm.py├── pytorch_model-00001-of-00008.bin├── pytorch_model-00002-of-00008.bin├── pytorch_model-00003-of-00008.bin├── pytorch_model-00004-of-00008.bin├── pytorch_model-00005-of-00008.bin├── pytorch_model-00006-of-00008.bin├── pytorch_model-00007-of-00008.bin├── pytorch_model-00008-of-00008.bin├── pytorch_model.bin.index.json├── special_tokens_map.json├── tokenization_internlm.py├── tokenizer_config.json└── tokenizer.model
github链接
操作指南