有趣的网站设计网络营销的职能有哪些
1.代码修改
源码是针对3D单通道图像的,只需要简单改写为2D就行,修改nnMamba4cls.py代码如下:
# -*- coding: utf-8 -*-
# 作者: Mr Cun
# 文件名: nnMamba4cls.py
# 创建时间: 2024-10-25
# 文件描述:修改nnmamba,使其适应3通道2分类DR分类任务import torch
import torch.nn as nn
import torch.nn.functional as F
from mamba_ssm import Mambadef conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):"""3x3 convolution with padding."""return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=dilation,groups=groups,bias=False,dilation=dilation,)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution."""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outdef make_res_layer(inplanes, planes, blocks, stride=1):downsample = nn.Sequential(conv1x1(inplanes, planes, stride),nn.BatchNorm2d(planes),)layers = []layers.append(BasicBlock(inplanes, planes, stride, downsample))for _ in range(1, blocks):layers.append(BasicBlock(planes, planes))return nn.Sequential(*layers)class MambaLayer(nn.Module):def __init__(self, dim, d_state=8, d_conv=4, expand=2):super().__init__()self.dim = dimself.nin = conv1x1(dim, dim)self.nin2 = conv1x1(dim, dim)self.norm2 = nn.BatchNorm2d(dim) # LayerNormself.relu2 = nn.ReLU(inplace=True)self.relu3 = nn.ReLU(inplace=True)self.norm = nn.BatchNorm2d(dim) # LayerNormself.relu = nn.ReLU(inplace=True)self.mamba = Mamba(d_model=dim, # Model dimension d_modeld_state=d_state, # SSM state expansion factord_conv=d_conv, # Local convolution widthexpand=expand # Block expansion factor)def forward(self, x):B, C = x.shape[:2]x = self.nin(x)x = self.norm(x)x = self.relu(x)act_x = xassert C == self.dimn_tokens = x.shape[2:].numel()img_dims = x.shape[2:]x_flat = x.reshape(B, C, n_tokens).transpose(-1, -2)x_mamba = self.mamba(x_flat)out = x_mamba.transpose(-1, -2).reshape(B, C, *img_dims)# act_x = self.relu3(x)out += act_xout = self.nin2(out)out = self.norm2(out)out = self.relu2(out)return outclass MambaSeq(nn.Module):def __init__(self, dim, d_state=16, d_conv=4, expand=2):super().__init__()self.dim = dimself.relu = nn.ReLU(inplace=True)self.mamba = Mamba(d_model=dim, # Model dimension d_modeld_state=d_state, # SSM state expansion factord_conv=d_conv, # Local convolution widthexpand=expand # Block expansion factor)def forward(self, x):B, C = x.shape[:2]x = self.relu(x)assert C == self.dimn_tokens = x.shape[2:].numel()img_dims = x.shape[2:]x_flat = x.reshape(B, C, n_tokens).transpose(-1, -2)x_mamba = self.mamba(x_flat)out = x_mamba.transpose(-1, -2).reshape(B, C, *img_dims)return outclass DoubleConv(nn.Module):def __init__(self, in_ch, out_ch, stride=1, kernel_size=3):super(DoubleConv, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_ch, out_ch, kernel_size=kernel_size, stride=stride, padding=int(kernel_size / 2)),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),nn.Conv2d(out_ch, out_ch, 3, padding=1, dilation=1),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),)def forward(self, input):return self.conv(input)class SingleConv(nn.Module):def __init__(self, in_ch, out_ch):super(SingleConv, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_ch, out_ch, 3, padding=1), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True))def forward(self, input):return self.conv(input)class nnMambaEncoder(nn.Module):def __init__(self, in_ch=3, channels=32, blocks=3, number_classes=2):super(nnMambaEncoder, self).__init__()self.in_conv = DoubleConv(in_ch, channels, stride=2, kernel_size=3)self.mamba_layer_stem = MambaLayer(dim=channels, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=4, # Local convolution widthexpand=2 # Block expansion factor)self.layer1 = make_res_layer(channels, channels * 2, blocks, stride=2)self.layer2 = make_res_layer(channels * 2, channels * 4, blocks, stride=2)self.layer3 = make_res_layer(channels * 4, channels * 8, blocks, stride=2)self.pooling = nn.AdaptiveAvgPool2d((1, 1))self.mamba_seq = MambaSeq(dim=channels*2, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=2, # Local convolution widthexpand=2 # Block expansion factor)self.mlp = nn.Sequential(nn.Linear(channels*14, channels), nn.ReLU(), nn.Dropout(0.5), nn.Linear(channels, number_classes))def forward(self, x):c1 = self.in_conv(x)c1_s = self.mamba_layer_stem(c1) + c1c2 = self.layer1(c1_s)c3 = self.layer2(c2)c4 = self.layer3(c3)pooled_c2_s = self.pooling(c2)pooled_c3_s = self.pooling(c3)pooled_c4_s = self.pooling(c4)h_feature = torch.cat((pooled_c2_s.reshape(c1.shape[0], c1.shape[1]*2, 1), pooled_c3_s.reshape(c1.shape[0], c1.shape[1]*2, 2), pooled_c4_s.reshape(c1.shape[0], c1.shape[1]*2, 4)), dim=2)h_feature_att = self.mamba_seq(h_feature) + h_featureh_feature = h_feature_att.reshape(c1.shape[0], -1)return self.mlp(h_feature)if __name__ == "__main__":model = nnMambaEncoder().cuda()input = torch.zeros((8, 3, 224,224)).cuda()output = model(input)print(output.shape)2.增加训练代码和数据集代码
- dr_dataset.py
# -*- coding: utf-8 -*-
# 作者: Mr.Cun
# 文件名: dr_dataset.py
# 创建时间: 2024-10-25
# 文件描述:视网膜数据处理import torch
import numpy as np
import os
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms, datasetsroot_path = '/home/aic/deep_learning_data/retino_data'
batch_size = 64 # 根据自己电脑量力而行
class_labels = {0: 'Diabetic Retinopathy', 1: 'No Diabetic Retinopathy'}
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)class RetinaDataset:def __init__(self, root_path, batch_size,class_labels):self.root_path = root_pathself.batch_size = batch_sizeself.class_labels = class_labelsself.transform = self._set_transforms()self.train_dataset = self._load_dataset('train')self.val_dataset = self._load_dataset('valid')self.test_dataset = self._load_dataset('test')self.train_loader = DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)self.valid_loader = DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False)self.test_loader = DataLoader(self.test_dataset, batch_size=self.batch_size, shuffle=False)def _set_transforms(self):return transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomRotation(30),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])def _load_dataset(self, split):root = os.path.join(self.root_path, split)return datasets.ImageFolder(root=root, transform=self.transform)def visualize_samples(self, loader):figure = plt.figure(figsize=(12, 12))cols, rows = 4, 4for i in range(1, cols * rows + 1):sample_idx = np.random.randint(len(loader.dataset))img, label = loader.dataset[sample_idx]figure.add_subplot(rows, cols, i)plt.title(self.class_labels[label])plt.axis("off")img_np = img.numpy().transpose((1, 2, 0))img_valid_range = np.clip(img_np, 0, 1)plt.imshow(img_valid_range)plt.show()if __name__ == '__main__':processor = RetinaDataset(root_path, batch_size,class_labels)processor.visualize_samples(processor.train_loader)
- train.py
# -*- coding: utf-8 -*-
# 作者: Mr Cun
# 文件名: train.py
# 创建时间: 2024-10-25
# 文件描述:模型训练
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from nnMamba4cls import *
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
from dr_dataset import RetinaDatasetwarnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0"# 设置随机因子
def seed_everything(seed=42):os.environ['PYHTONHASHSEED'] = str(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.deterministic = True# 设置全局参数
model_lr = 3e-4
BATCH_SIZE = 64
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
use_amp = False # 是否使用混合精度
use_dp = False # 是否开启dp方式的多卡训练
classes = 2
resume = None
CLIP_GRAD = 5.0
Best_ACC = 0 # 记录最高得分
use_ema = False
use_mixup = False
model_ema_decay = 0.9998
start_epoch = 1
seed = 1
seed_everything(seed)# 数据预处理
transform = transforms.Compose([transforms.RandomRotation(10),transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])])
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])
])mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)# 加载数据集
root_path = '/home/aic/deep_learning_data/retino_data'
train_path = os.path.join(root_path, 'train')
valid_path = os.path.join(root_path, 'valid')
test_path = os.path.join(root_path, 'test')
dataset_train = datasets.ImageFolder(train_path, transform=transform)
dataset_test = datasets.ImageFolder(test_path, transform=transform_test)
class_labels = {0: 'Diabetic Retinopathy', 1: 'No Diabetic Retinopathy'}
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, num_workers=8, shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)# 设置loss
# 实例化模型并且移动到GPU
# criterion_train = SoftTargetCrossEntropy() #mixup_fn
criterion_train = torch.nn.CrossEntropyLoss()
criterion_val = torch.nn.CrossEntropyLoss()# 设置模型
# 设置模型
model_ft = nnMambaEncoder()print(model_ft)if resume:model = torch.load(resume)print(model['state_dict'].keys())model_ft.load_state_dict(model['state_dict'])Best_ACC = model['Best_ACC']start_epoch = model['epoch'] + 1
model_ft.to(DEVICE)
print(model_ft)# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)# 设置混合精度,EMA
if use_amp:scaler = torch.cuda.amp.GradScaler()
if torch.cuda.device_count() > 1 and use_dp:print("Let's use", torch.cuda.device_count(), "GPUs!")model_ft = torch.nn.DataParallel(model_ft)
if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device=DEVICE,resume=resume)
else:model_ema = None# 定义训练过程
def train(model, device, train_loader, optimizer, epoch, model_ema):model.train()loss_meter = AverageMeter()acc1_meter = AverageMeter()total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)if use_mixup:samples, targets = mixup_fn(data, target)else:samples, targets = data, targetoutput = model(samples)optimizer.zero_grad()if use_amp:with torch.cuda.amp.autocast():loss = torch.nan_to_num(criterion_train(output, targets))scaler.scale(loss).backward()torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()else:loss = criterion_train(output, targets)loss.backward()# torch.nn.utils.clip_grad_norm_(models.parameters(), CLIP_GRAD)optimizer.step()if model_ema is not None:model_ema.update(model)torch.cuda.synchronize()lr = optimizer.state_dict()['param_groups'][0]['lr']loss_meter.update(loss.item(), target.size(0))# acc1, acc5 = accuracy(output, target)acc1 = accuracy(output, target)[0]loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))if (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))ave_loss = loss_meter.avgacc = acc1_meter.avgprint('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))return ave_loss, acc# 验证过程
@torch.no_grad()
def val(model, device, test_loader):global Best_ACCmodel.eval()loss_meter = AverageMeter()acc1_meter = AverageMeter()# acc5_meter = AverageMeter()total_num = len(test_loader.dataset)print(total_num, len(test_loader))val_list = []pred_list = []for data, target in test_loader:for t in target:val_list.append(t.data.item())data, target = data.to(device,non_blocking=True), target.to(device,non_blocking=True)output = model(data)loss = criterion_val(output, target)_, pred = torch.max(output.data, 1)for p in pred:pred_list.append(p.data.item())acc1 = accuracy(output, target)[0]loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))acc = acc1_meter.avgprint('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\t'.format(loss_meter.avg, acc,))if acc > Best_ACC:if isinstance(model, torch.nn.DataParallel):torch.save(model.module, file_dir + '/' + 'best.pth')else:torch.save(model, file_dir + '/' + 'best.pth')Best_ACC = accif isinstance(model, torch.nn.DataParallel):state = {'epoch': epoch,'state_dict': model.module.state_dict(),'Best_ACC':Best_ACC}if use_ema:state['state_dict_ema']=model.module.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')else:state = {'epoch': epoch,'state_dict': model.state_dict(),'Best_ACC': Best_ACC}if use_ema:state['state_dict_ema']=model.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')return val_list, pred_list, loss_meter.avg, acc# 绘制训练和验证的损失和准确率曲线
def plot_training_curves(file_dir,epoch_list,train_loss_list,val_loss_list,train_acc_list,val_acc_list):fig = plt.figure(1)plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')# 显示图例plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')plt.legend(["Train Loss", "Val Loss"], loc="upper right")plt.xlabel(u'epoch')plt.ylabel(u'loss')plt.title('Model Loss ')plt.savefig(file_dir + "/loss.png")plt.close(1)fig2 = plt.figure(2)plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')plt.legend(["Train Acc", "Val Acc"], loc="lower right")plt.title("Model Acc")plt.ylabel("acc")plt.xlabel("epoch")plt.savefig(file_dir + "/acc.png")plt.close(2)if __name__ == '__main__':# 创建保存模型的文件夹file_dir = 'checkpoints/EfficientVMamba/'if os.path.exists(file_dir):print('true')os.makedirs(file_dir, exist_ok=True)else:os.makedirs(file_dir)# 训练与验证is_set_lr = Falselog_dir = {}train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []if resume and os.path.isfile(file_dir+"result.json"):with open(file_dir+'result.json', 'r', encoding='utf-8') as file:logs = json.load(file)train_acc_list = logs['train_acc']train_loss_list = logs['train_loss']val_acc_list = logs['val_acc']val_loss_list = logs['val_loss']epoch_list = logs['epoch_list']for epoch in range(start_epoch, EPOCHS + 1):epoch_list.append(epoch)log_dir['epoch_list'] = epoch_listtrain_loss, train_acc = train(model_ft,DEVICE,train_loader,optimizer,epoch,model_ema)train_loss_list.append(train_loss)train_acc_list.append(train_acc)log_dir['train_acc'] = train_acc_listlog_dir['train_loss'] = train_loss_listif use_ema:val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)else:val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)val_loss_list.append(val_loss)val_acc_list.append(val_acc)log_dir['val_acc'] = val_acc_listlog_dir['val_loss'] = val_loss_listlog_dir['best_acc'] = Best_ACCwith open(file_dir + '/result.json', 'w', encoding='utf-8') as file:file.write(json.dumps(log_dir))print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))if epoch < 600:cosine_schedule.step()else:if not is_set_lr:for param_group in optimizer.param_groups:param_group["lr"] = 1e-6is_set_lr = True# 绘制训练和验证的损失和准确率曲线plot_training_curves(file_dir,epoch_list,train_loss_list,val_loss_list,train_acc_list,val_acc_list)
3.效果
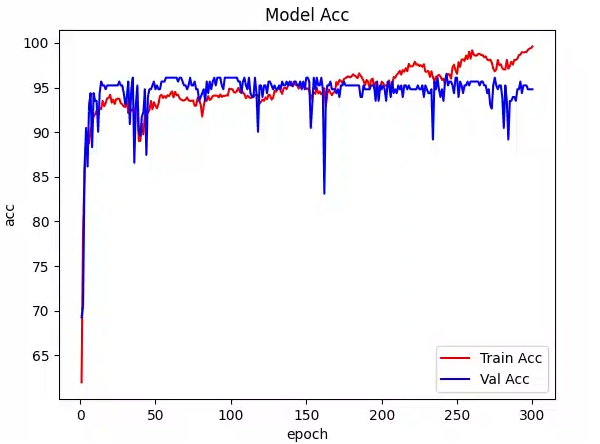
对比之前的几种mamba,针对糖尿病视网膜病变数据集,采用同样的训练参数:300 Epochs,32 Batch Size。
| 序号 | 模型 | 验证集最高准确率 | 显存占用 | 训练时间 |
|---|---|---|---|---|
| 1 | Vision Mamba | 94% | 约12GB | 约3小时 |
| 2 | VMamba | 98.12% | 约24GB | 约2小时 |
| 3 | EfficientVMamba | 95.23% | 约20GB | 约2小时 |
| 4 | MedMamba | 92.3% | 约20GB | 约2小时 |
| 5 | MambaVision | 95.4% | 约20GB | 约2小时 |
| 6 | nnMamba | 96.53% | 约6GB | 约30分钟 |
4.修改代码试试看
这里我只是在增加了一层Residual Block提取,验证集最好的ACC是96.53%
class nnMambaEncoder(nn.Module):def __init__(self, in_ch=3, channels=32, blocks=3, number_classes=2):super(nnMambaEncoder, self).__init__()self.in_conv = DoubleConv(in_ch, channels, stride=2, kernel_size=3)self.mamba_layer_stem = MambaLayer(dim=channels, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=4, # Local convolution widthexpand=2 # Block expansion factor)self.layer1 = make_res_layer(channels, channels * 2, blocks, stride=2)self.layer2 = make_res_layer(channels * 2, channels * 4, blocks, stride=2)self.layer3 = make_res_layer(channels * 4, channels * 8, blocks, stride=2)self.layer4 = make_res_layer(channels * 8, channels * 16, blocks, stride=2)self.pooling = nn.AdaptiveAvgPool2d((1, 1))self.mamba_seq = MambaSeq(dim=channels*2, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=2, # Local convolution widthexpand=2 # Block expansion factor)self.mlp = nn.Sequential(nn.Linear(channels*30, channels), nn.ReLU(), nn.Dropout(0.5), nn.Linear(channels, number_classes))def forward(self, x):c1 = self.in_conv(x)c1_s = self.mamba_layer_stem(c1) + c1c2 = self.layer1(c1_s)c3 = self.layer2(c2)c4 = self.layer3(c3)c5 = self.layer4(c4)pooled_c2_s = self.pooling(c2)pooled_c3_s = self.pooling(c3)pooled_c4_s = self.pooling(c4)pooled_c5_s = self.pooling(c5)h_feature = torch.cat((pooled_c2_s.reshape(c1.shape[0], c1.shape[1]*2, 1),pooled_c3_s.reshape(c1.shape[0], c1.shape[1]*2, 2),pooled_c4_s.reshape(c1.shape[0], c1.shape[1]*2, 4),pooled_c5_s.reshape(c1.shape[0], c1.shape[1]*2, 8)), dim=2)h_feature_att = self.mamba_seq(h_feature) + h_feature # B 64 15h_feature = h_feature_att.reshape(c1.shape[0], -1) # B 960return self.mlp(h_feature)
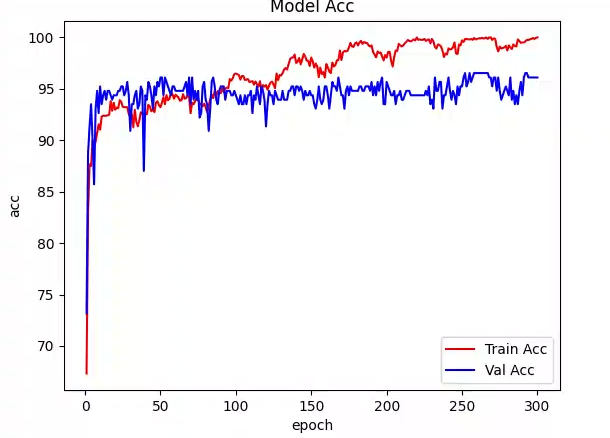
如果继续优化层的设置,应该会有更好的提升,这里就不继续做了