牡丹江建设银行网站百度网站禁止访问怎么解除
文章目录
- 一、RNN简介
- 二、RNN关键结构
- 三、RNN的训练方式
- 四、时间序列预测
- 五、梯度弥散和梯度爆炸问题
一、RNN简介
RNN(Recurrent Neural Network)中文循环神经网络,用于处理序列数据。它与传统人工神经网络和卷积神经网络的输入和输出相互独立不同,依赖它独特的神经结构(循环核)获得“记忆能力”
注意与递归神经网络(Recursive Neural Network)RNN区分,同时循环神经网络为短期记忆,与(Long Short-Term Memory networks)LSTM的长期记忆不同
二、RNN关键结构
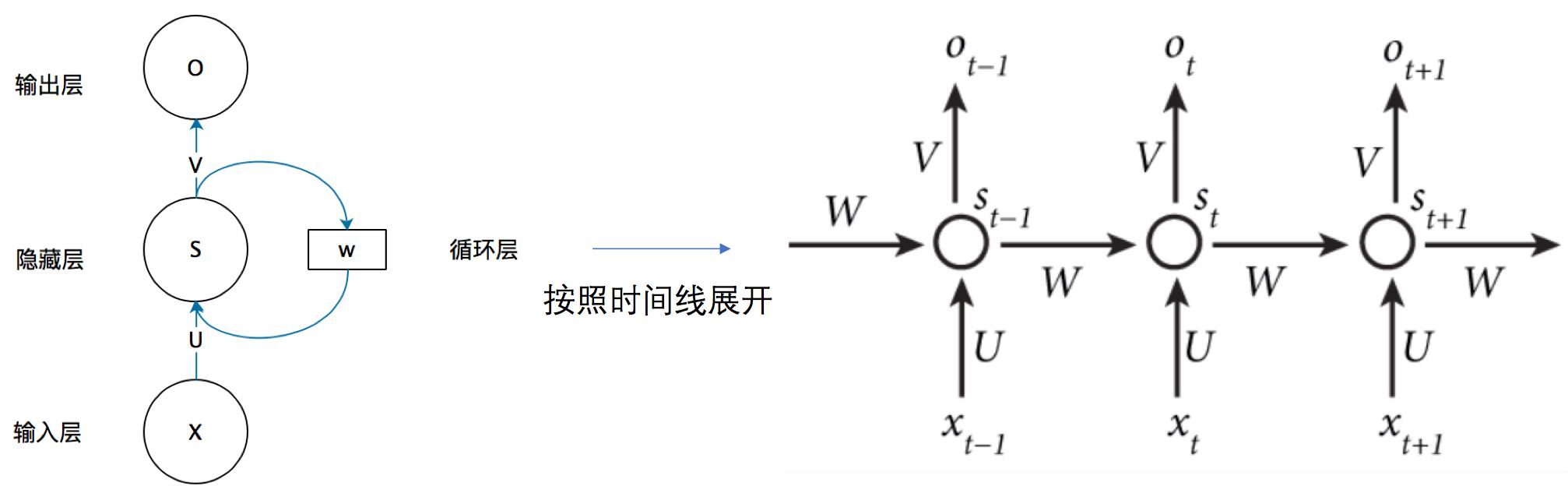
各参数含义:
- xtx_txt:序列t的输入层的值,sts_tst:序列t的隐藏层的值 ,oto_tot:序列t的输出层的值
- UUU:输入层到隐藏层的权重矩阵 ,VVV:隐藏层到输出层的权重矩阵
- WWW:隐藏层上一次的值作为这一次输入的权重
注意事项:
- 同不同序列t时的W,V,U相同,即RNN的Weight sharing
- 结构图中每一步都会有输出,但实际中很可能只需最后一步的输出
- 为了降低网络复杂度,sts_tst只包含前面若干隐藏层的状态
三、RNN的训练方式
本质还是梯度下降的反向传播,由前向传播得到的预测值与真实值构建损失函数,更新W、U、V求解最小值:
St=f(U⋅Xt+W⋅St−1+b)Ot=g(V⋅St)Lt=12(Yt−Ot)2S_t=f(U\cdot X_t+W\cdot S_{t-1}+b) \\O_t = g(V\cdot S_t) \\ L_t=\frac{1}{2}(Y_t-O_t)^2St=f(U⋅Xt+W⋅St−1+b)Ot=g(V⋅St)Lt=21(Yt−Ot)2
如果对t3t_3t3的U、V、W求偏导如下:
∂L3∂V=∂L3∂O3∂O3∂V∂L3∂U=∂L3∂O3∂O3∂S3∂S3∂U+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂U+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂S1∂S1∂U∂L3∂W=∂L3∂O3∂O3∂S3∂S3∂W+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂W+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂S1∂S1∂W因为有:O3=VS3+b2S3=UX3+WS2+b1S2=UX2+WS1+b1S1=UX1+WS0+b1\begin{aligned} &\frac{\partial L_3}{\partial V}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial V} \\ &\frac{\partial L_3}{\partial U}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial U}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial U}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial S_1}\frac{\partial S_1}{\partial U} \\&\frac{\partial L_3}{\partial W}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial W}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial W}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial S_1}\frac{\partial S_1}{\partial W} \\ &因为有:\\&O_3 = VS_3 + b_2\\&S_3 =UX_3+WS_2+b_1\\&S_2 =UX_2+WS_1+b_1\\&S_1=UX_1+WS_0+b_1 \end{aligned}∂V∂L3=∂O3∂L3∂V∂O3∂U∂L3=∂O3∂L3∂S3∂O3∂U∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂U∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂U∂S1∂W∂L3=∂O3∂L3∂S3∂O3∂W∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂W∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂W∂S1因为有:O3=VS3+b2S3=UX3+WS2+b1S2=UX2+WS1+b1S1=UX1+WS0+b1
可以看到U和W对于序列产生了依赖,并且可以得到:
∂Lt∂U=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂U∂Lt∂W=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂W\begin{aligned} &\frac{\partial L_t}{\partial U}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial U}\\&\frac{\partial L_t}{\partial W}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial W} \end{aligned} ∂U∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂U∂Sk∂W∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂W∂Sk
最后将结果放入激活函数即可
四、时间序列预测
预测一个正弦函数的走势
第一部分:构建样本数据
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
第二部分:构建循环神经网络结构
class Net(nn.Module):def __init__(self, ):super(Net, self).__init__()self.rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=1,batch_first=True,)for p in self.rnn.parameters():nn.init.normal_(p, mean=0.0, std=0.001)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x, hidden_prev):out, hidden_prev = self.rnn(x, hidden_prev)# [b, seq, h]out = out.view(-1, hidden_size)out = self.linear(out) # [seq,h] => [seq,1]out = out.unsqueeze(dim=0)# [1,seq,1]return out, hidden_prev
第三部分:迭代训练并计算loss
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)hidden_prev = torch.zeros(1, 1, hidden_size)for iter in range(6000):start = np.random.randint(10, size=1)[0]time_steps = np.linspace(start, start + 10, num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps, 1)x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)output, hidden_prev = model(x, hidden_prev)hidden_prev = hidden_prev.detach() #不会具有梯度loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter % 100 == 0:print("Iteration: {} loss {}".format(iter, loss.item()))
第四部分:绘制预测值并比较
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):input = input.view(1, 1, 1)(pred, hidden_prev) = model(input, hidden_prev)input = predpredictions.append(pred.detach().numpy().ravel()[0])x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x, s=90)
plt.plot(time_steps[:-1], x)plt.scatter(time_steps[1:], predictions)
plt.show()
迭代200次的图像:
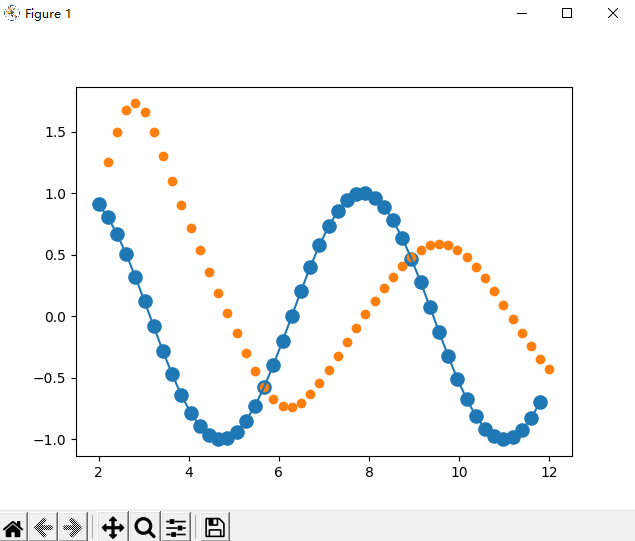
迭代6000次的图像:
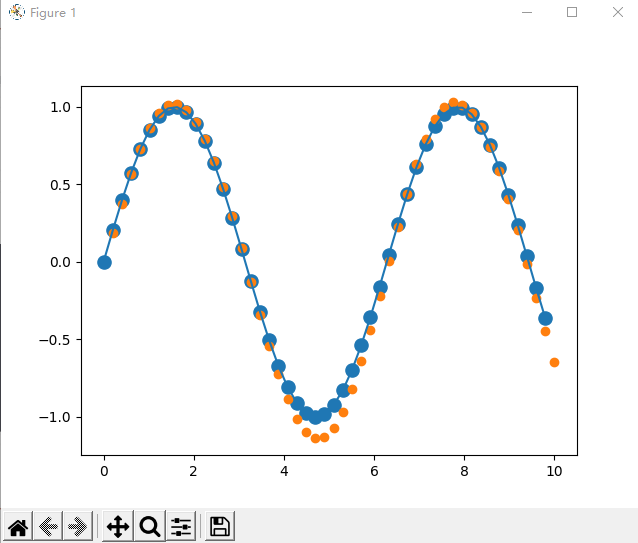
完整代码:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr=0.01class Net(nn.Module):def __init__(self, ):super(Net, self).__init__()self.rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=1,batch_first=True,)for p in self.rnn.parameters():nn.init.normal_(p, mean=0.0, std=0.001)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x, hidden_prev):out, hidden_prev = self.rnn(x, hidden_prev)# [b, seq, h]out = out.view(-1, hidden_size)out = self.linear(out) # [seq,h] => [seq,1]out = out.unsqueeze(dim=0)# [1,seq,1]return out, hidden_prevmodel = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)hidden_prev = torch.zeros(1, 1, hidden_size)for iter in range(200):start = np.random.randint(10, size=1)[0]time_steps = np.linspace(start, start + 10, num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps, 1)x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)output, hidden_prev = model(x, hidden_prev)hidden_prev = hidden_prev.detach() #不会具有梯度loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter % 100 == 0:print("Iteration: {} loss {}".format(iter, loss.item()))start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):input = input.view(1, 1, 1)(pred, hidden_prev) = model(input, hidden_prev)input = predpredictions.append(pred.detach().numpy().ravel()[0])x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x, s=90)
plt.plot(time_steps[:-1], x)plt.scatter(time_steps[1:], predictions)
plt.show()
五、梯度弥散和梯度爆炸问题
- 梯度弥散(消失):由于导数的链式法则,连续多层小于1的梯度相乘会使梯度越来越小,最终导致某层梯度为0。梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系
- 梯度爆炸:初始化权值过大,梯度更新量是会成指数级增长的,前面层会比后面层变化的更快,就会导致权值越来越大
上面两个问题都是RNN训练时的难题,解决它们需要不断的实操经验和更加升入的理解