无货源网店哪个平台好东莞seo公司

Python异常处理:三种不同方法的探索与最佳实践
前言
本文旨在探讨
Python中三种不同的异常处理方法。通过深入理解各种异常处理策略,我们可以更好地应对不同的编程场景,选择最适合自己需求的方法。
异常处理在编程中扮演着至关重要的角色。合适的异常处理不仅可以提高代码的健壮性,还能增强程序的可读性和可维护性。在Python编程中,有效地管理异常是提高代码质量的关键一环。
在开始深入探讨之前,让我们先通过一个实际的编程难题来引入这个话题:
前天,一位朋友向我提出了一个问题。在处理一个循环遍历时,由于难以预见所有可能的错误,他需要为每个循环中的元素实现异常处理,以防某个元素的错误影响到整个程序的运行。
但这样做的结果是,代码因为过多的 try-except 块而变得冗长且难以维护。这种情况下,我们怎样才能优化代码,既处理异常又保持代码的清晰和简洁呢?
示例代码如下:
for item in html_xpath:try:try:url = item.xpath('//title/url-ellipsis/a/url()')except Exception as e:url = Nonetry:title = item.xpath('//title/text-ellipsis/a/text()')except Exception as e:title = None...except Exception as e:...
在本文中,我们将探讨三种不同的异常处理方法,并在最后回到这个问题,提供一个优化后的解决方案。
知识点📖📖
查阅这两篇文章,对食用本文更有帮助哦!!
-
深入浅出Python异常处理 - 你所不知道的Python异常
-
万字长文 - Python 日志记录器logging 百科全书 之 基础配置
在这里先总结下文中会介绍到的三种异常处理方法的优缺点以及应用场景:
| 方法 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
try-except 块 | 简单直接,易于理解。 针对不同类型的异常可以编写特定处理逻辑。 | 代码中频繁使用会导致代码冗长 | 适用于处理已知可能发生的错误。 用于具体函数或代码块中的错误处理。 |
sys.excepthook | 全局捕获未处理的异常。 使用相对简单。 | 不能阻止程序因异常而终止。 仅处理未被 try-except 块捕获的异常。在子线程中不适用。 | 适用于记录未捕获的异常。 错误报告和日志记录。 |
| 装饰器 | 提高代码复用性和清晰度。 可定制化异常处理逻辑。 | 使用和理解需要更高的Python技能水平。只适用于被装饰的函数。 | 适用于需要统一异常处理逻辑的函数。 用于减少代码重复,提高维护性。 |
异常处理方法总结✨✨
Python中有多种方式来处理异常,每种方法都适用于不同的情况和需求。
通过选择适当的异常处理方法,我们可以更好地管理和处理Python程序中的异常情况。
以下是三种常见的异常处理方法以及它们的优点和缺点:
1. 使用 try-except 块
优点:简单直接,易于理解;允许针对不同类型的异常编写特定的处理逻辑。
缺点:在代码中频繁重复使用可能导致代码冗长。
示例代码:
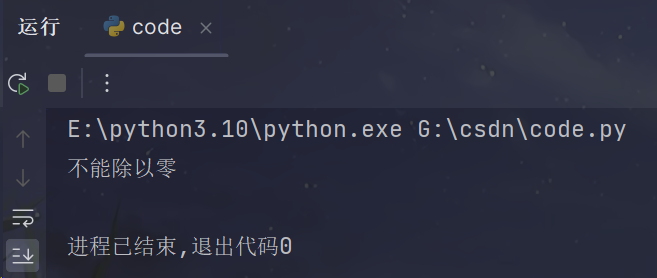
try:# 可能会引发异常的代码result = 1 / 0
except ZeroDivisionError:# 处理特定类型的异常print("不能除以零")代码释义:
代码使用了 try-except 块来捕获特定类型的异常(ZeroDivisionError),且打印了一条错误消息。
代码运行效果如下:
2. 使用 sys.excepthook
sys.excepthook 是Python中的一个全局函数,它在脚本遇到未捕获的异常时被调用。默认情况下,当一个异常没有被任何 try-except 块捕获时,Python会调用 sys.excepthook,打印出异常信息以及堆栈跟踪。
优点:允许在程序的任何地方捕获未被处理的异常;使用起来相对简单。
缺点:不能阻止程序因未处理的异常而终止;只能用于处理未被 try-except 块捕获的异常。
示例代码:
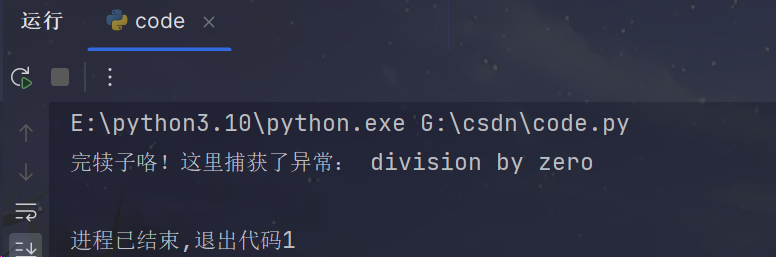
import sysdef global_exception_handler(exc_type, exc_value, exc_traceback):print("完犊子咯!这里捕获了异常:", exc_value)sys.excepthook = global_exception_handler# 示例:故意制造一个除以零的错误
result = 1 / 0
print('没运行到这里哦!')代码释义:
代码配置了 sys.excepthook,使其在未捕获的异常发生时,会调用 global_exception_handler 函数来处理异常。
它允许在程序的任何地方捕获未被处理的异常,但在捕获了未经处理的异常后程序会终止(优雅的退出。)
代码运行效果如下:
- 可以看到,代码并没有运行到
print('没运行到这里哦!')这一行~
3. 使用装饰器
优点:提高代码的复用性和清晰度,减少重复代码;可以定制化异常处理逻辑,应用于特定的函数。
缺点:相较于直接的 try-except 块,装饰器的使用和理解需要更高的Python技能水平;只适用于被装饰的函数。
示例代码:
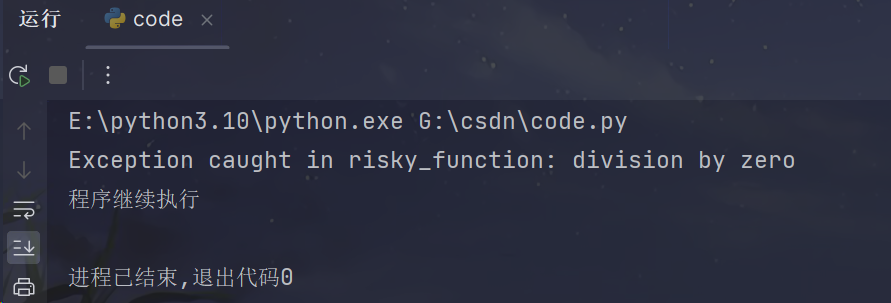
def catch_exceptions(func):def wrapper(*args, **kwargs):try:return func(*args, **kwargs)except Exception as e:print(f"Exception caught in {func.__name__}: {e}")return Nonereturn wrapper@catch_exceptions
def risky_function(x, y):return x / yresult = risky_function(1, 0)
print("程序继续执行")代码释义:
代码定义了一个装饰器 catch_exceptions,它可以应用于所有需要处理的函数。当被装饰的函数抛出异常时,装饰器会捕获异常并打印错误消息。
代码运行效果如下:
- 可以看到,程序在捕获了异常后,还可以正常向下执行~
4. 更健壮的代码
这份代码在
使用装饰器的基础上添加了堆栈打印和日志记录,而日志记录的作用,想必大家都很清楚了。
关于日志记录的使用,可以查阅俺前面的文章。
import logging
import traceback
import sys# 配置日志记录器
logging.basicConfig(filename='app.log',level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s',encoding='utf-8',filemode='w'
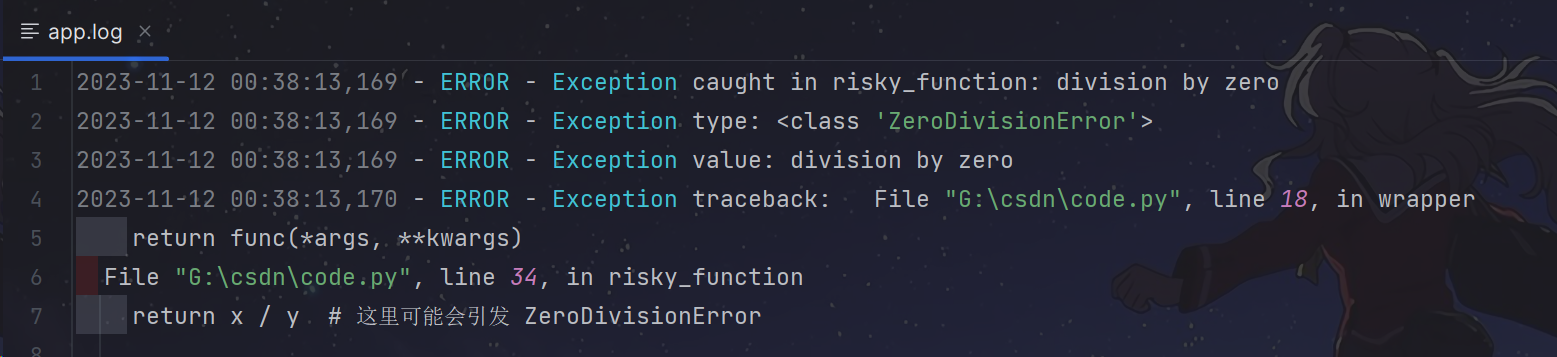
)def catch_exceptions(func):def wrapper(*args, **kwargs):try:return func(*args, **kwargs)except Exception as e:exc_type, exc_value, exc_traceback = sys.exc_info()# 将异常信息记录到日志logging.error(f"Exception caught in {func.__name__}: {e}")logging.error(f"Exception type: {exc_type}")logging.error(f"Exception value: {exc_value}")log_traceback = ''.join(traceback.format_tb(exc_traceback))logging.error(f"Exception traceback: {log_traceback}")return Nonereturn wrapper@catch_exceptions
def risky_function(x, y):return x / y # 这里可能会引发 ZeroDivisionErrorresult = risky_function(1, 0)
print("程序继续执行")代码运行效果如下:
- 可以看到,日志记录的信息非常清晰。
解决前面的问题
这份代码解决了前面的问题,nice~
在这份代码中,我特地模拟了一段html文本,然后在 xpath_expression中特地使用了错误的表达式。
因代码只用作于演示,所以这里不添加日志记录和对战堆栈了~~
from lxml import html# 定义异常处理装饰器
def catch_exceptions(func):def wrapper(*args, **kwargs):try:return func(*args, **kwargs)except Exception as e:print(f"Exception caught in {func.__name__}: {e}")return '空'return wrapper# 使用装饰器来解析HTML元素
@catch_exceptions
def parse_element(sub_element, xpath_expression):return sub_element.xpath(xpath_expression)# 示例HTML元素
item_html = """
<div><a href="https://frica.blog.csdn.net/?type=blog">frica Link</a><span>是小菜欸</span>...
</div>
"""# 定义HTML元素与XPath的映射
html_xpath_map = {'url': "//a/@href",'title': "//span/text()",'other': '//dd/dd/ddd/text()','age': '这不是xpath_expression表达式'
}if __name__ == '__main__':result_map = dict()# 创建HTML元素对象element = html.fromstring(item_html)# 遍历XPath映射,解析元素并将结果存入字典for key, value in html_xpath_map.items():result = parse_element(element, value)result_map[key] = result[0] if result else '空'# 海象运算符# result_map[key] = x[0] if (x := parse_element(element, value)) else '空'# 打印解析结果print(result_map)代码释义:
这份代码的主要目的是解决在循环遍历中处理异常的问题,
通过使用装饰器和Xpath来简化异常处理,并使代码更清晰和简洁。
总的来说,这份关于异常处理的代码已经很健壮了!!
看不懂的读者朋友们回去阅读我前面的文章~~
代码运行效果:

总结
在Python中,不同的异常处理方法适用于不同的场景。
- 使用
try-except块适用于处理已知可能发生的错误,适用于具体函数或代码块中的错误处理。 sys.excepthook适用于记录未捕获的异常,用于错误报告和日志记录,但不能阻止程序终止。- 装饰器适用于需要统一异常处理逻辑的函数,提高代码的复用性和清晰度。
在选择异常处理方法时,应根据具体需求和项目背景考虑使用哪种方法,并根据最佳实践和注意事项来编写异常处理代码,以确保代码的健壮性和可维护性。
后话
本次分享到此结束,
see you~🐱🏍🐱🏍