枸杞网站的建设方案深圳网络营销
前言:
本片文章主要对爬虫爬取网页数据来进行一个简单的解答,对与其中的数据来进行一个爬取。
一:环境配置
Python版本:3.7.3
IDE:PyCharm
所需库:requests ,parsel
二:网站页面
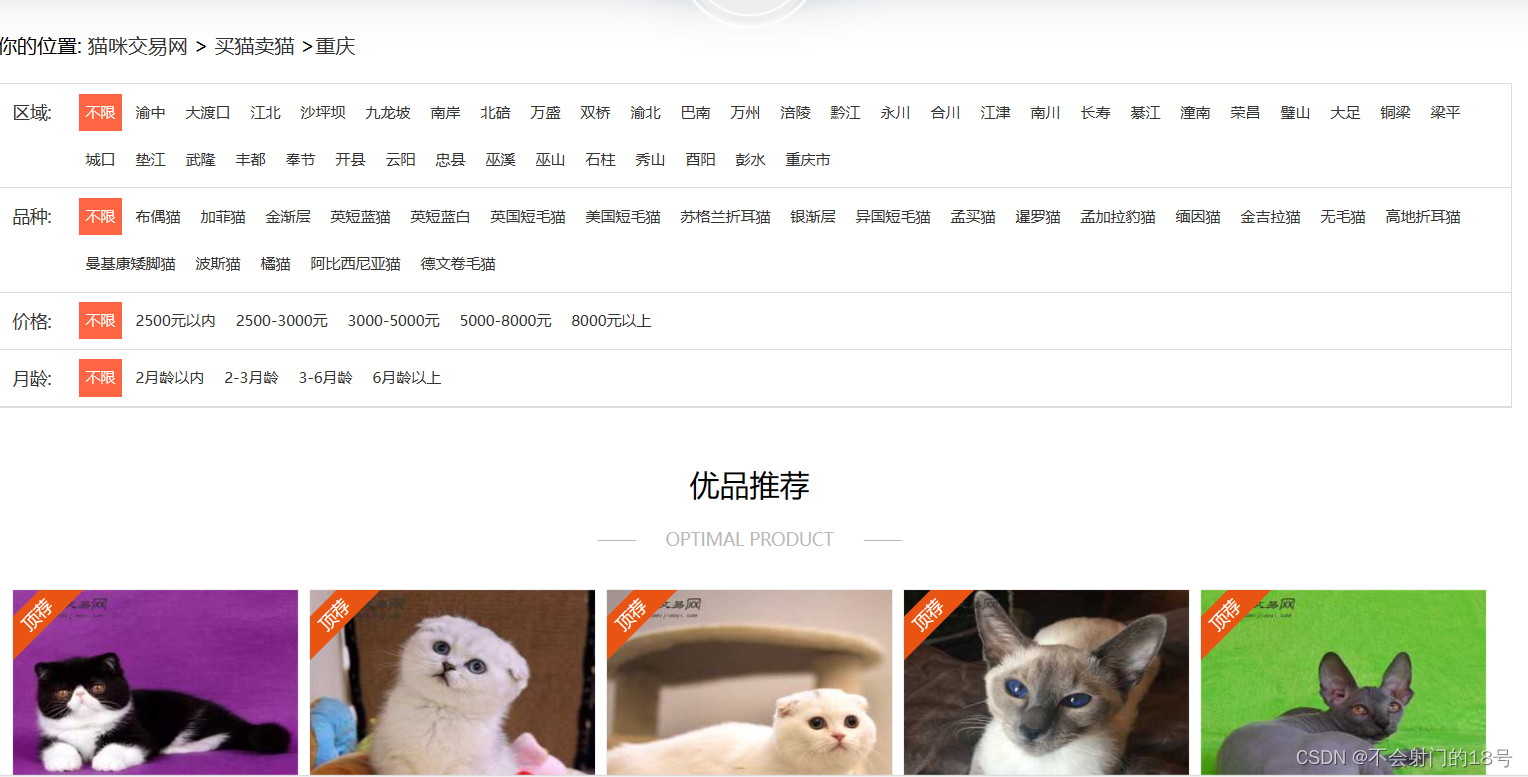
我们需要获取以下数据:
'地区', '店名', '标题', '价格', '浏览次数', '卖家承诺', '在售只数',
'年龄', '品种', '预防', '联系人', '联系方式', '异地运费', '是否纯种',
'猫咪性别', '驱虫情况', '能否视频', '详情页'
三:具体代码实现
# _*_ coding : utf-8 _*_
# @Time : 2023/9/3 23:03
# @Author : HYT
# @File : 猫
# @Project : 爬虫教程
import requests
import parsel
import csv
url ='http://www.maomijiaoyi.com/index.php?/list_0_78_0_0_0_0.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
href = selector.css('div.content:nth-child(1) a::attr(href)').getall()
areas = selector.css('div.content:nth-child(1) a .area span.color_333::text').getall()
areas = [i.strip() for i in areas]
zip_data = zip(href, areas)
for index in zip_data:# http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_546549.htmlindex_url = 'http://www.maomijiaoyi.com' + index[0]response_1 = requests.get(url=index_url, headers=headers)selector_1 = parsel.Selector(response_1.text)area = index[1] # 地区shop = selector_1.css('.dinming::text').get().strip() # 店名title = selector_1.css('.detail_text .title::text').get().strip() # 标题price = selector_1.css('span.red.size_24::text').get() # 价格views = selector_1.css('.info1 span:nth-child(4)::text').get() # 浏览次数promise = selector_1.css('.info1 div:nth-child(2) span::text').get().replace('卖家承诺: ', '') # 卖家承诺sale = selector_1.css('.info2 div:nth-child(1) div.red::text').get() # 在售age = selector_1.css('.info2 div:nth-child(2) div.red::text').get() # 年龄breed = selector_1.css('.info2 div:nth-child(3) div.red::text').get() # 品种safe = selector_1.css('.info2 div:nth-child(4) div.red::text').get() # 预防people = selector_1.css('div.detail_text .user_info div:nth-child(1) .c333::text').get() # 联系人phone = selector_1.css('div.detail_text .user_info div:nth-child(2) .c333::text').get() # 联系方式fare = selector_1.css('div.detail_text .user_info div:nth-child(3) .c333::text').get().strip() # 异地运费purebred = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(1) .c333::text').get().strip() # 是否纯种sex = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(4) .c333::text').get().strip() # 猫咪性别worming = selector_1.css('.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(2) .c333::text').get().strip() # 驱虫情况video = selector_1.css('.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(4) .c333::text').get().strip() # 能否视频dit = {'地区': area,'店名': shop,'标题': title,'价格': price,'浏览次数': views,'卖家承诺': promise,'在售只数': sale,'年龄': age,'品种': breed,'预防': safe,'联系人': people,'联系方式': phone,'异地运费': fare,'是否纯种': purebred,'猫咪性别': sex,'驱虫情况': worming,'能否视频': video,'详情页': index_url,}print(area, shop, title, price, views, promise, sale, age, breed,safe, people, phone, fare, purebred, sex, worming, video, index_url, sep=' | ')四:结果展示
