网站宣传流程附近电脑培训班零基础
提示:文章附有源码!!!
文章目录
- 前言
- 一、nn.embedding函数解释
- 二、nn.embedding函数使用方法
- 四、模型训练与预测的权重变化探讨
前言
最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函数,对points、boxes或learn query进行编码或解码。因此,我想写一篇文章作为记录,本想简单对其 介绍,但写着写着就想把所有与它相关东西作为记录。本文章探讨了nn.Embedding参数、使用方法、模型训练与预测的变化,并附有列子源码作为支撑 ,呈现一个较为完善的理解内容。
一、nn.embedding函数解释
Embedding实际是一个索引表或查找表,它是符合随机初始化生成的正太分布的表,将输入向量化,其结构如下:
nn.Embedding(num_embeddings, embedding_dim)
第1个参数 num_embeddings 就是生成num_embeddings个嵌入向量。
第2个参数 embedding_dim 就是嵌入向量的维度,即用embedding_dim值的维数来表示一个基本单位。
当然,该函数还有很多其它参数,解释如下:
参数源码注释如下:
num_embeddings (int): size of the dictionary of embeddings
embedding_dim (int): the size of each embedding vector
padding_idx (int, optional): If specified, the entries at :attr:`padding_idx` do not contribute to the gradient;therefore, the embedding vector at :attr:`padding_idx` is not updated during training,i.e. it remains as a fixed "pad". For a newly constructed Embedding,the embedding vector at :attr:`padding_idx` will default to all zeros,but can be updated to another value to be used as the padding vector.
max_norm (float, optional): If given, each embedding vector with norm larger than :attr:`max_norm`is renormalized to have norm :attr:`max_norm`.
norm_type (float, optional): The p of the p-norm to compute for the :attr:`max_norm` option. Default ``2``.
scale_grad_by_freq (boolean, optional): If given, this will scale gradients by the inverse of frequency ofthe words in the mini-batch. Default ``False``.
sparse (bool, optional): If ``True``, gradient w.r.t. :attr:`weight` matrix will be a sparse tensor.See Notes for more details regarding sparse gradients.参数中文解释:
num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量
注:该函数服从正太分布,该函数可参与训练,我将在后面做解释。
二、nn.embedding函数使用方法
该函数实际是对词的编码,假如你有2句话,每句话有四个词,那么你想对每个词使用6个维度表达,其代码如下:
import torch.nn as nn
import torch
if __name__ == '__main__':embedding = nn.Embedding(100, 6) # 我设置100个索引,每个使用6个维度表达。input = torch.LongTensor([[1, 2, 4, 5],[4, 3, 2, 3]]) # a batch of 2 samples of 4 indices eache = embedding(input)print('输出尺寸', e.shape)print('输出值:\n',e)weights=embedding.weightprint('embed权重输出值:\n', weights[:6])输出结果:
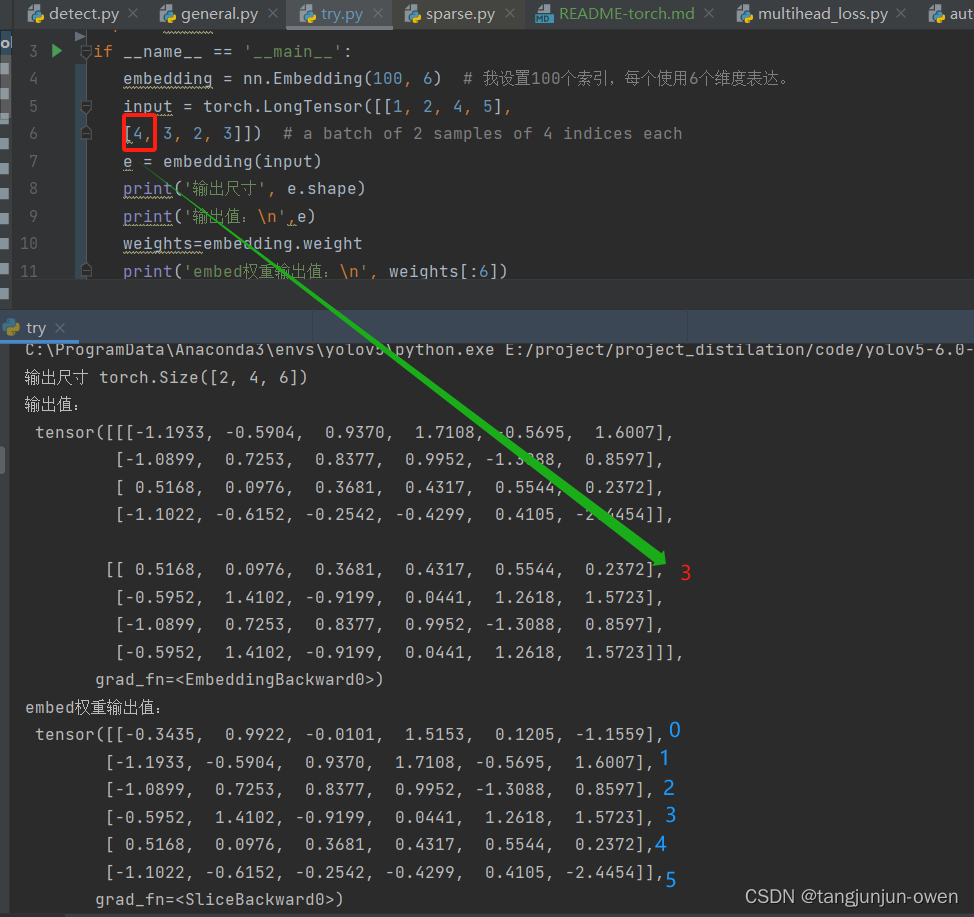
从图上可看出,输入编码是通过索引查找已编号embedding的权重,并将其赋值替换表达。换句话说,nn.Embedding(100, 6)生成正太分布100行6列数据,行必须超过输入句子词语长度,而句子每个词使用整数编码成索引,该索引对应之前embedding行寻找,得到对应行
维度,即可转为表达该词的特征向量。
四、模型训练与预测的权重变化探讨
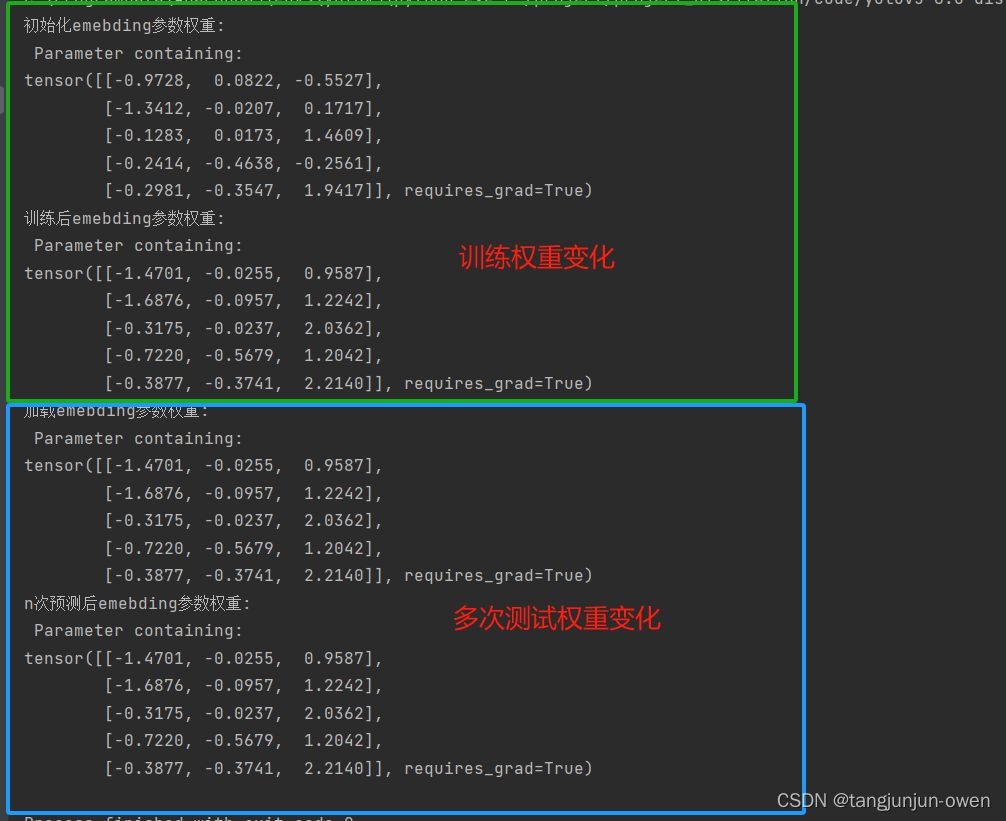
之前已说过nn.Embedding()在训练过程中会发生变化,但在预测中将不在变化,应该是被训练成最佳词的向量维度表达,也就是说每个词唯一对应索引,被Embedding特征表达训练成最佳特征表达,也可说训练词索引特征表达固定。为探讨此过程,我写了对应示列,如下:
import torch
from torch.nn import Embeddingclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.emb = Embedding(5, 3)def forward(self,vec):input = torch.tensor([0, 1, 2, 3, 4])emb_vec1 = self.emb(input)# print(emb_vec1) ### 输出对同一组词汇的编码output = torch.einsum('ik, kj -> ij', emb_vec1, vec)return output
def simple_train():model = Model()vec = torch.randn((3, 1))label = torch.Tensor(5, 1).fill_(3)loss_fun = torch.nn.MSELoss()opt = torch.optim.SGD(model.parameters(), lr=0.015)print('初始化emebding参数权重:\n',model.emb.weight)for iter_num in range(100):output = model(vec)loss = loss_fun(output, label)opt.zero_grad()loss.backward(retain_graph=True)opt.step()# print('第{}次迭代emebding参数权重{}:\n'.format(iter_num, model.emb.weight))print('训练后emebding参数权重:\n',model.emb.weight)torch.save(model.state_dict(),'./embeding.pth')return modeldef simple_test():model = Model()ckpt = torch.load('./embeding.pth')model.load_state_dict(ckpt)model=model.eval()vec = torch.randn((3, 1))print('加载emebding参数权重:\n', model.emb.weight)for iter_num in range(100):output = model(vec)print('n次预测后emebding参数权重:\n', model.emb.weight)if __name__ == '__main__':simple_train() # 训练与保存权重simple_test()
结果如下:
训练代码参考博客:点击这里