南京做网站牛杭州网站免费制作
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
西宫南内多秋草,落叶满阶红不扫。
大家好,我是Python进阶者。
一、前言
前几天在Python最强王者交流群【🇿 🇽 🇸】问了一个Python正则表达式处理的问题,问题如下:各位大佬午好,我在使用爬虫时遇到了一个问题,就是在爬取数据时,爬取了多页 但是数据保存时只有最后一页的,请问这个问题该怎么解决啊 下面分别是截图与代码文件。
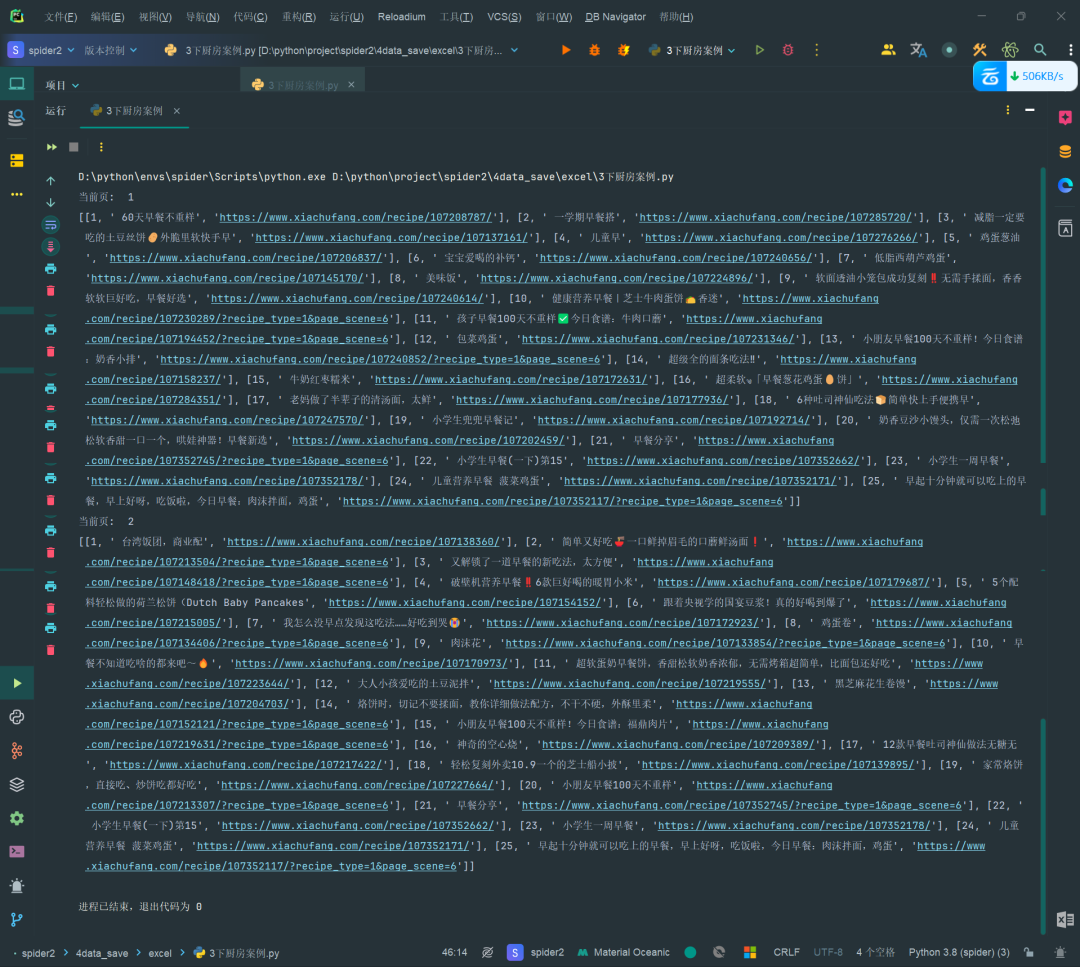
这种问题其实我遇到多次,但是不知道如何解决这种问题。
二、实现过程
这里【东哥】给了个思路和代码,如下:
# encoding: UTF-8
# create time: 2024/05/30/0030 16:26:03# ################### 导入模块 #################### 分隔的开始
import time
from urllib.parse import urljoinimport openpyxl
import requests
import parsel
from fake_useragent import UserAgent
# ################### 导入模块 #################### 分隔的结束# TODO 列表下载
def get_page(pages: int):"""发送请求,获取页面数据:param pages: 翻页参数:return: 请求到的数据"""url = f"https://www.xiachufang.com/category/40071/?page={pages}"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'}try:response = requests.get(url, headers=headers)if response.status_code == 200:parse_page(response)else:return "请求失败,状态响应码:\t" + str(response.status_code)except requests.ReadTimeout as e:print("请求超时", e.args[0])time.sleep(2)def parse_page(response):"""解析页面数据:param response: 响应的内容:return: 返回一个列表,并交给存储的函数"""items = []lst = []base_url = 'https://www.xiachufang.com'html = parsel.Selector(response.text)foods_list = html.css('div.info p.name')count = 0for li in range(0, len(foods_list)):count += 1lst.append([count, # 计数器foods_list[li].css('a::text').extract()[0][16:-14].strip(), # 获取标题urljoin(base_url, foods_list[li].css('a::attr(href)').extract()[0]) # 获取连接并对连接做处理])print(lst)items.append(lst)save1(items)save_data(items, current_page)def save1(items):with open('data.txt', 'w', encoding='utf-8') as f:for item in items:for item in item:f.write(str(item) + '\n')def save_data(items):"""存储数据:param lst: 解析数据得到的列表:return: 无返回"""# wb = openpyxl.Workbook()# sheet = wb.active# for item in lst:# sheet.append(item)# wb.save('下厨房早餐.xlsx')wb = openpyxl.Workbook()# 选择默认的工作表ws = wb.active# 给工作表添加标题行ws.append(['ID', '菜名', '链接'])# 遍历列表数据并添加到工作表中for item in items:for item in item:ws.append(item)# 保存工作簿为Excel文件wb.save(f'下厨房早餐{current_page}.xlsx')def main() -> None:total_pages = 3for i in range(total_pages):current_page = i + 1get_page(current_page)print("当前页:\t" + str(current_page))time.sleep(2)if __name__ == '__main__':main()不过修改后的代码,还是没能解决粉丝的问题。后来【隔壁😼山楂】给了两个思路,顺利地解决了粉丝的问题。

如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python正则表达式的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【🇿 🇽 🇸】提出的问题,感谢【东哥】、【隔壁😼山楂】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~