互联网站备案登记表seoul是啥意思
本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6&share_source=copy_web&vd_source=404581381724503685cb98601d6706fb
上节课学习了字符串的编码和解码,数据验证的方法,字符串的处理(字符串的拼接操作和字符串的去重操作),本节课学习正则表达式的简介以及相关符号,re模块中match函数的使用,re模块中search函数和findall函数的使用,re模块中sub函数和split函数的使用。
1.正则表达式的简介以及相关符号
正则表达式,就是特殊的字符序列,它能帮助用户便捷地检查一个字符串是否符合某种模式。
那么正则表示式也有很多类型。
1)元字符
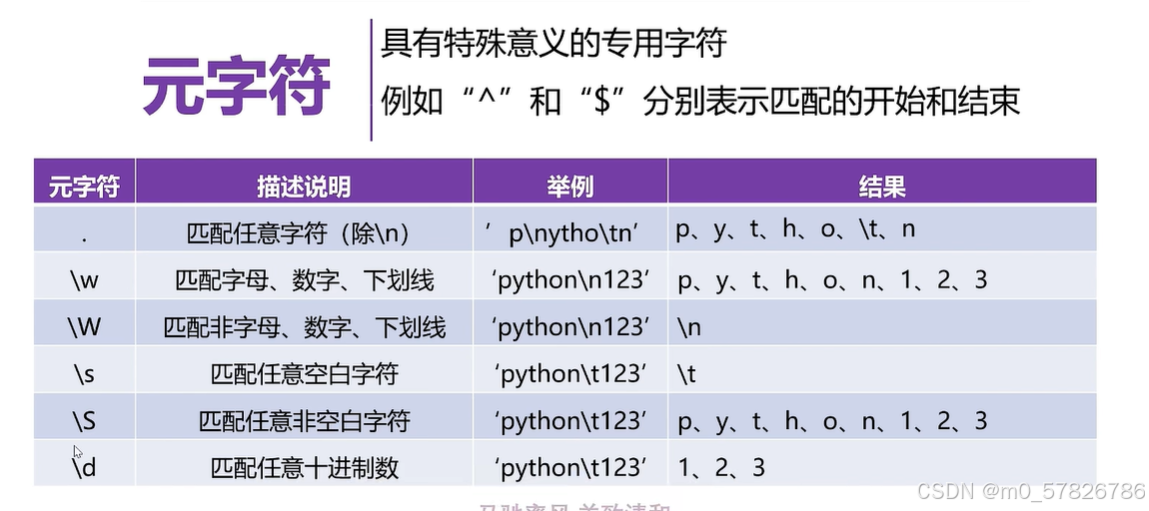
上图只是元字符的部分字符,这里学习部分。
2)限定符
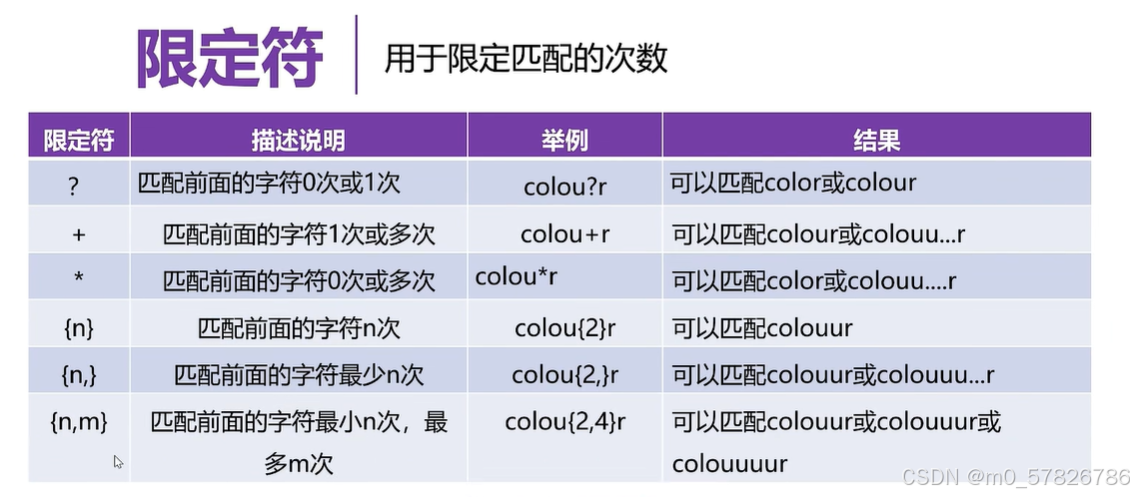
限定符就是用于限定匹配的次数,也就是限定查找到的个数。
3)其他字符
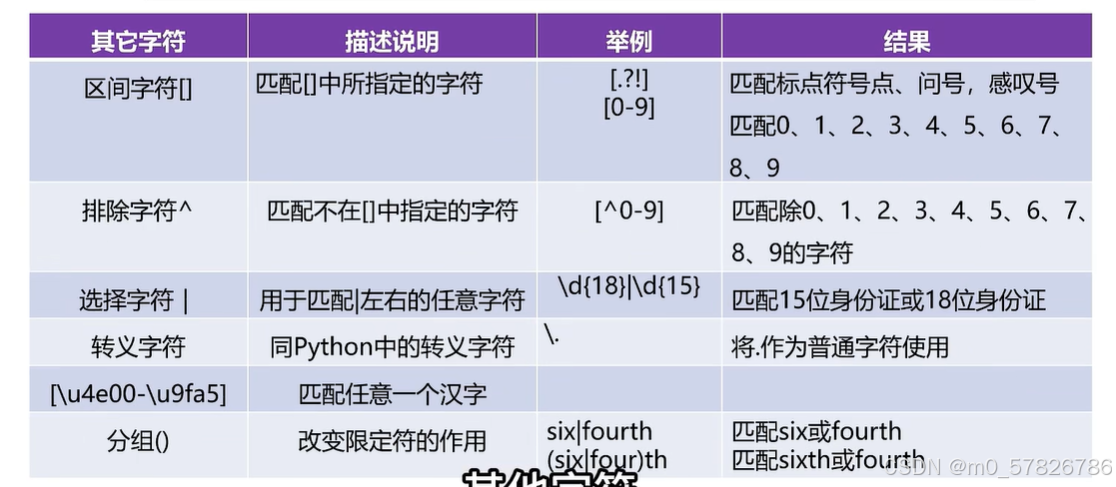
其他类型的正则表达式。
2.re模块中match函数的使用
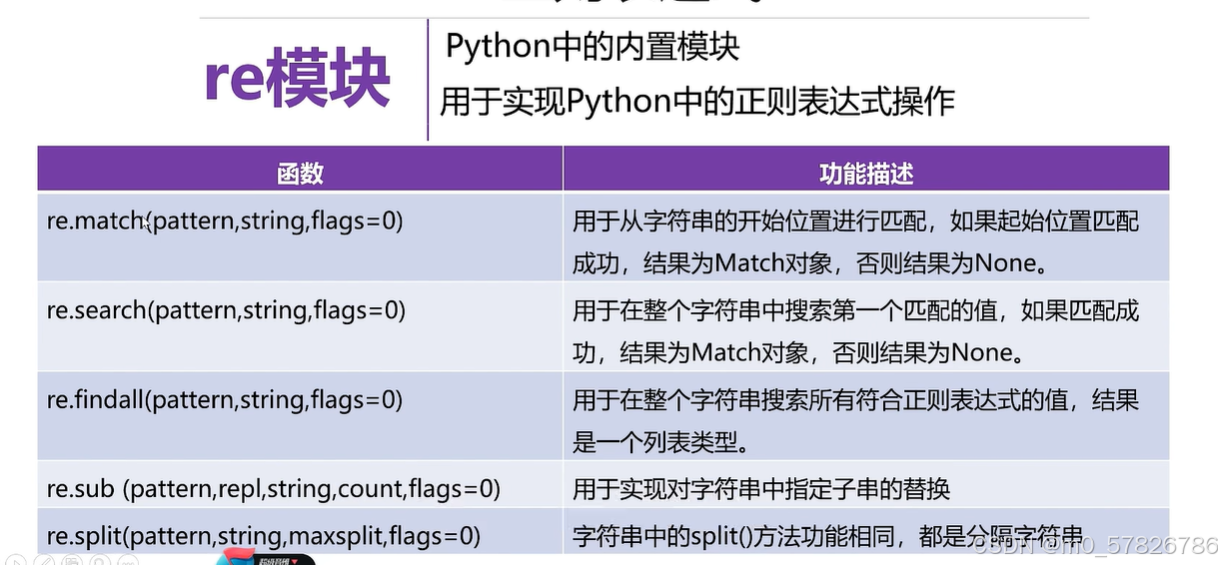
对于上述的正则表达式需要有专门的函数去用,python中有模块叫re模块,是python中正则表达式的一个操作,而且这是一个内置模块,不需要单独安装。上图中五个函数是本节要学的。下为对代码实现实例:
import re #导入
#这里需要写一个"模式字符串",就是规则,根据前面学习的,\d表示0-9的整数,\是转义符,也就是说这里将“.”变成一个普通的点
pattern='\d\.\d+'#+表示出现的次数,其前面的数字表示重复几次,“\d+"表示出现0-9次,所以这规则意思就是“0-9的数字.出现0-9的字符串可以被匹配”
s='I study Python 3.11 day' #待匹配字符串
#下面执行match函数来查找s里有没有满足“0-9的数字.出现0-9的字符串可以被匹配”的字符串
match=re.match(pattern,s,re.I) #模块re的match方法,这里re.I表示调用re中的ignore也就是忽略大小写
#总结:xx=re.match(模式字符串名,匹配字符串名,其他参数)
print(match)s2='3.11 I study Python day' #第二个待匹配字符串
match2=re.match(pattern,s2,re.I) #模块re的match方法,这里re.I表示调用re中的ignore也就是忽略大小写
print(match2)print('匹配值的起始位置:',match2.start()) #输出匹配值的起始位置
print('匹配值的结束位置:',match2.end())#输出匹配值的终止位置(注意结束位置是不包括的位置)
print('匹配区间的位置元素:',match2.span())#输出开始结束区间位置的元素(注意结束位置是不包括的位置)
print('待匹配的字符串:',match2.string)#输出待匹配的字符串
print('匹配的数据:',match2.group())#输出匹配到的数据输出结果:

3.re模块中search函数和findall函数的使用
对于前面那个模块罗列的re模块里面的函数,除了第一种的match,还有其他的函数可以使用。match的功能是从字符串的开始位置开始匹配,除非是在第一个就能匹配到,否则的话就会输出None。为了解决这种弊端,我们选择search函数。
search函数式在整个字符串中去查找,找到就行不一定在开始位置(0这个适用范围显然优于match),下为实例:
import re #导入
#这里需要写一个"模式字符串",就是规则,根据前面学习的,\d表示0-9的整数,\是转义符,也就是说这里将“.”变成一个普通的点
pattern='\d\.\d+'#+表示出现的次数,其前面的数字表示重复几次,“\d+"表示出现0-9次,所以这规则意思就是“0-9的数字.出现0-9的字符串可以被匹配”
s='I study Python3.11 every day Python2.7' #待匹配字符串
#下面执行match函数来查找s里有没有满足“0-9的数字.出现0-9的字符串可以被匹配”的字符串
match=re.search(pattern,s) #模块re的search方法,默认忽略大小写
#xx=re.search(模式字符串名,匹配字符串名,其他参数)s2='4.10 Python I study every day' #第二个待匹配字符串
s3='Python I study every day' #第三个待匹配字符串没有数字(输出结果是None)
match2=re.search(pattern,s2) #模块re的search方法,默认忽略大小写
match3=re.search(pattern,s3) #模块re的search方法,默认忽略大小写
print(match)
print(match2)
print(match3)#如果想输出匹配的数据,需要用到match.group()的方法
print(match.group()) #因为search找到的是第一个匹配的数据,因此match返回的是3.11
print(match2.group())#match返回的是4.10
print(match3.group())#没有数据,因此match返回的是None结果如下:
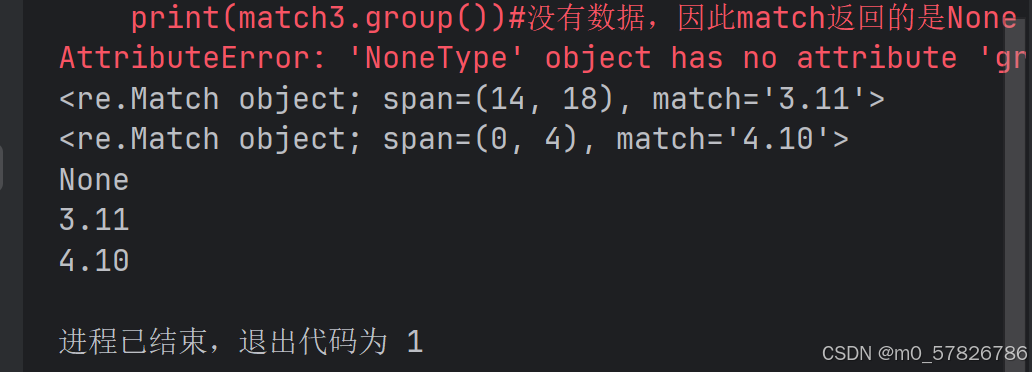
由于search只能返回第一个满足条件的数据,其他符合条件的都被忽略了。为了保证其他满足条件的也可以输出,使用另一个函数findall。
findall的功能是用于在整个字符串中搜索所有符合正则表达式的数据,结果是一个列表类型。下为实例;
#下为findall的实例
import re #导入
#这里需要写一个"模式字符串",就是规则,根据前面学习的,\d表示0-9的整数,\是转义符,也就是说这里将“.”变成一个普通的点
pattern='\d\.\d+'#+表示出现的次数,其前面的数字表示重复几次,“\d+"表示出现0-9次,所以这规则意思就是“0-9的数字.出现0-9的字符串可以被匹配”
s='I study Python3.11 every day Python2.7' #待匹配字符串
s2='4.10 Python I study every day' #第二个待匹配字符串
s3='Python I study every day' #第三个待匹配字符串没有数字(输出结果是None)
lst=re.findall(pattern,s)#可以看到findall函数将所有符合条件的都列出来了
lst2=re.findall(pattern,s2)
lst3=re.findall(pattern,s3)print(lst)
print(lst2)
print(lst3)结果如下所示

4.re模块中sub函数和split函数的使用
上面三个函数都是为了找到满足条件的数据,而下面这两个函数是用于找到并且替换目标数据的函数。sub函数的功能如上所示是“对字符串当中指定的子串进行替换”,可以用于将字符串中的不方便展示的关键字,或爬虫之类的字符替换掉。(这不禁让博主想到某某文学城的“口口文学”以及某黑暗降临的“**”违禁词替换)(审核这有什么不能过的?)
下为具体实例以及解释:
import re
#下为函数sub的实例
#这里需要写一个"模式字符串",这里的规则相当于不可以出现这些字眼,如果出现就需要用其他字符换掉
pattern='黑客|破解|反爬'
s='我想学习python,想破解一些VIP视频,python可以实现无底线反爬吗?'#假如这是我们发表的一段评论,那么这个“匹配字符串”中的违禁词需要替换掉
#语法格式:新的变量名=re.sub(pattern,想要替换的字符串(注意用''框柱哦),匹配字符串名)
new_s=re.sub(pattern,'xxx',s)
print(new_s)结果如下:(该说不说加上违禁词替换莫名让人浮想联翩)

第二个函数就是split函数,它和字符串的split是一样的分割。这里视频举的例子是打开百度网址搜索ysj,复制那个搜索结果页面的网址
https://www.baidu.com/s?wd=ysj&rsv_spt=1&rsv_iqid=0xedc9cb50000d9767&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=68018901_58_oem_dg&rsv_enter=1&rsv_dl=tb&rsv_sug3=4&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=2637&rsv_sug4=3928这里我们想要让其网址变短一点,观察这一长串,wd是这个搜索框的一个名字,第一个&后面都是这种参数的形式,只保留这些其他删掉,将其作为待匹配字符串:
https://www.baidu.com/s?wd=ysj&rsv_spt=1#下为函数split的实例
pattern2='[?|&]'#意思就是将待匹配字符串被?或者|拆分
s2='https://www.baidu.com/s?wd=ysj&rsv_spt=1'
lst=re.split(pattern2,s2)
print(lst)结果如下:

本节完