网站开发流程知乎seo快速收录快速排名
YOLOv5-第Y2周:训练自己的数据集
- YOLOv5-第Y2周:训练自己的数据集
- 一、前言
- 二、我的环境
- 三、准备数据集
- 四、运行 split_train_val.py 文件
- 五、生成 train.txt、test.txt、val.txt 文件
- 六、创建ab.yaml文件
- 七、开始使用自己的数据集训练
- 八、总结
YOLOv5-第Y2周:训练自己的数据集
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:PyTorch
三、准备数据集
文件夹目录结构:
🍦主目录:
paper_ data (创建个文件夹,将数据放到这里)
Annotations (放置我们的.xm文件)
images (放置图片文件)
ImageSets:
Main (会在该文件夹内自动生成train.txt、 val.txt、 test.txt和trainval.txt四个文件,
存放训练集、验证集、测试集图片的名字)

四、运行 split_train_val.py 文件
ImageSets文件夹下面有个Main子文件夹,其下面存放了 train.txt、val.txt、test.txt和 trainval.txt四个文件,它们是通过split_train_val.py文件来生成的。
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 14 19:08:01 2023@author: admin
"""import os
import random
import argparseparser = argparse.ArgumentParser()#xml文件的地址,根据自己的数据进行修改,xml一班存放在Annotation下
parser.add_argument('--xml_path', default = 'C:\YOLOv5\yolov5-master\paper_data\Annotations', type = str, help = 'input xml label path')#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default = 'C:\YOLOv5\yolov5-master\paper_data\ImageSets/Main', type = str, help = 'output txt label path')opt = parser.parse_args()trainval_percent = 0.9
train_percent = 8 / 9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)num = len(total_xml)
list_index = range(num)
tv = int(num * train_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')for i in list_index:name = total_xml[i][:-4] + '\n'if i in trainval:file_trainval.write(name)if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行 split_train_val.py 文件后你将得至train.txt、val.txt、test.txt 和 trainval.txt 四 个文件,结果如下:

五、生成 train.txt、test.txt、val.txt 文件
编写voc_label.py文件
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwdsets = ['train', 'val', 'test']
classes = ["pineapple"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('./annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('./labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('./labels/'):os.makedirs('./labels/')image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()list_file = open('./%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/images/%s.png\n' % (image_id)) # 注意你的图片格式,如果是.jpg记得修改convert_annotation(image_id)list_file.close()运行voc_label.py文件,你将会得到train.txt、test.txt、val.txt三个文件。
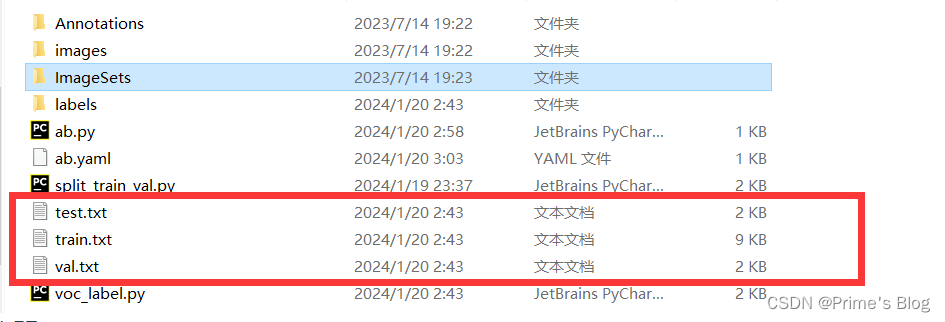
六、创建ab.yaml文件
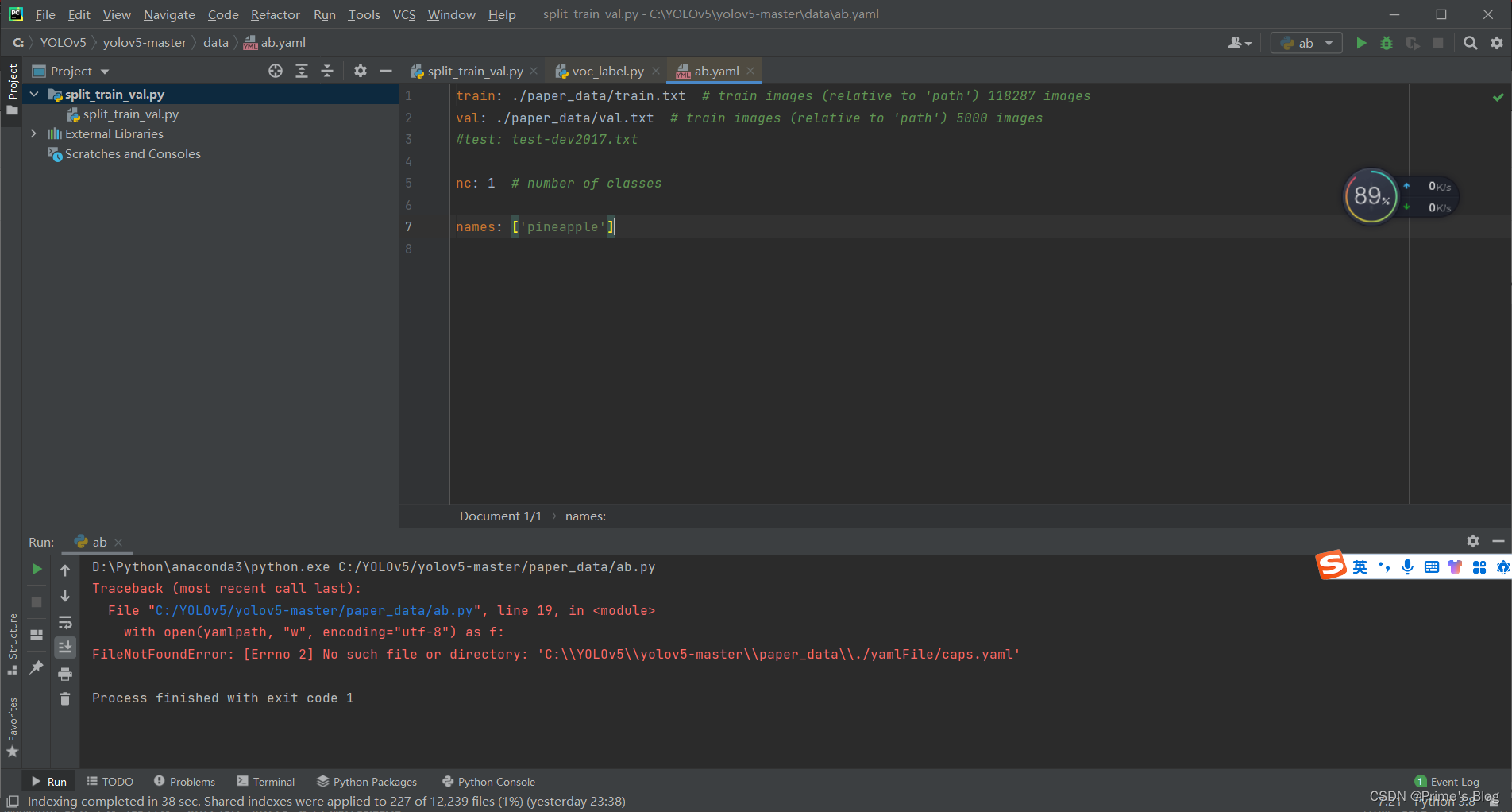
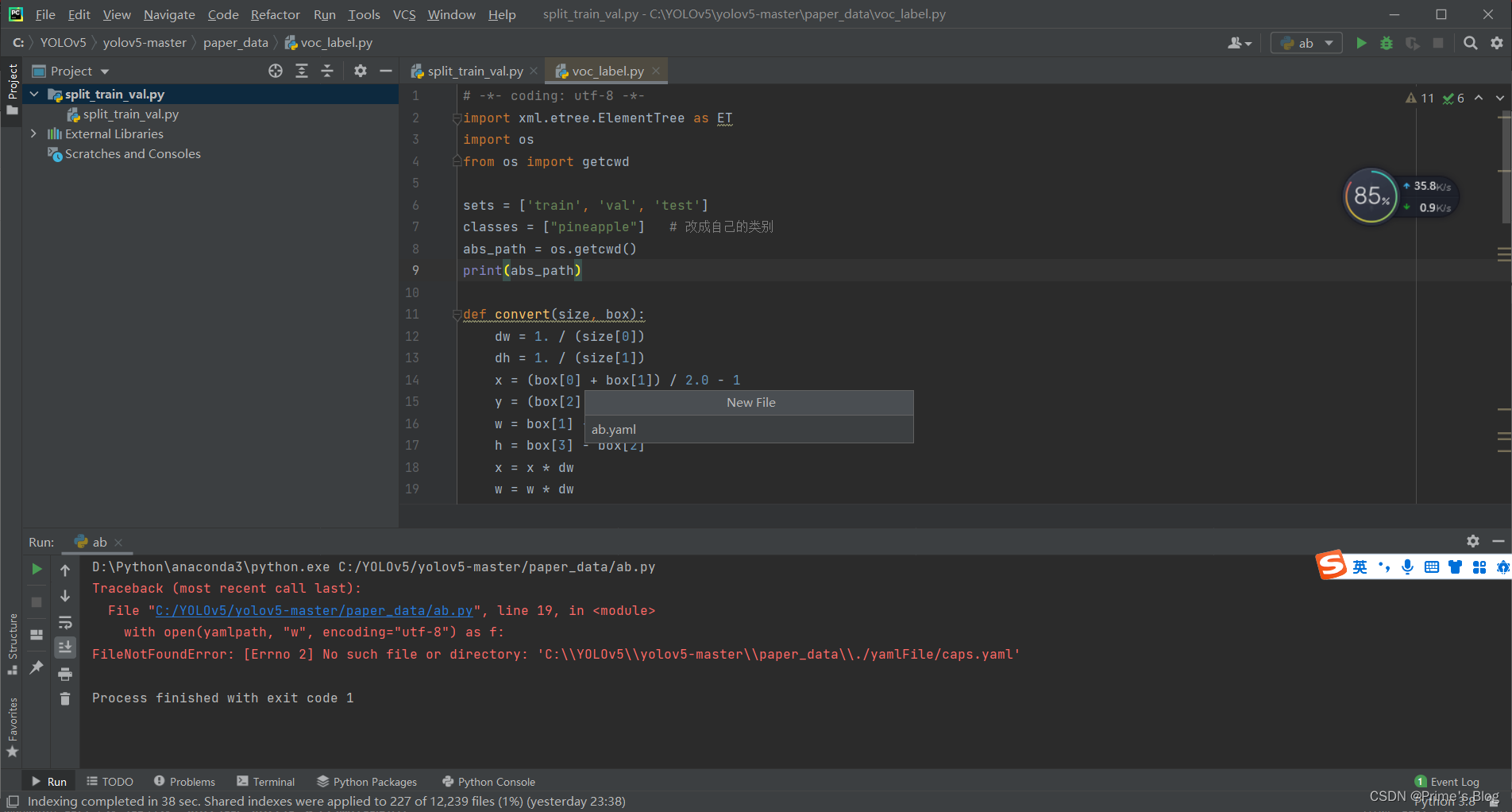 ab.yaml文件内容如下:
ab.yaml文件内容如下:
七、开始使用自己的数据集训练
python train.py --img 900 --batch 2 --epoch 5 --data paper_data/ab.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt
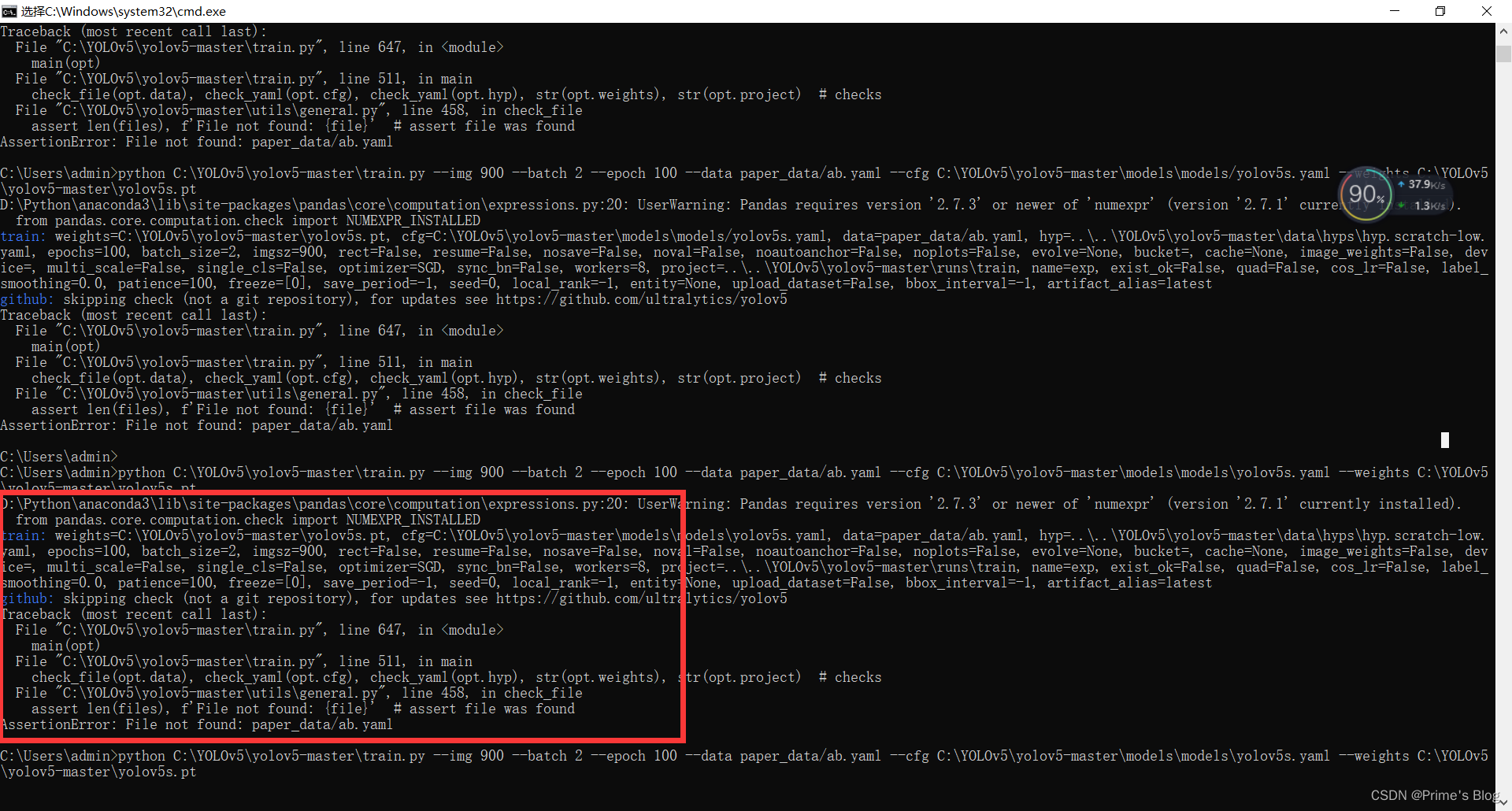
文件报错,这里还不知道是什么原因。后续查找修改Bug
八、总结
通过Y1和Y2的学习,学会了yolov5的环境配置以及用自己的数据集训练模型。接下来就是查阅资料,解决Bug。