怎么做前端网站互联网优化是什么意思
1. 背景
最近本qiang~关注了一个开源项目Scrapegraph-ai,是关于网页爬虫结合LLM的项目,所以想一探究竟,毕竟当下及未来,LLM终将替代以往的方方面面。
这篇文章主要介绍下该项目,并基于此项目实现一个demo页面,页面功能是输入一个待爬取的网页地址以及想要从网页中抽取的内容,最后点击按钮实现网页抓取及解析。
2. 模块简介
2.1 Scrapegraph-ai

该项目是一个网页爬虫的python包,使用LLM和直接图逻辑(direct graph logic)来为网页和本地文档(XML, HTML, JSON)创建爬取管道(pipeline)。
2.2 GPT-3.5免费申请,且国内可访问
GPT3.5-Turbo免费申请可以在开源项目GPT_API_free进行访问,其中该项目有免费申请的地址,以及网页插件、桌面应用安装等教程,在日志工作学习中,使用起来非常丝滑~
其次,国内访问gpt3.5可以基于该项目提供的代理: https://api.chatanywhere.tech/v1来实现访问。
3. 实战
3.1 安装第三方包
# 网页开发包,和Gradio类似
pip install streamlit
# 爬虫相关包
pip install playwright
playwright install
playwright install-deps # 安装依赖
3.2 设置gpt3.5代理环境变量
import os
os.environ['OPENAI_API_BASE'] = 'https://api.chatanywhere.tech/v1'
OPEN_API_KEY = 'sk-xxxxx'
3.3 创建网页元素
import streamlit as stst.title('网页爬虫AI agent')
st.caption('该app基于gpt3.5抓取网页信息')url = st.text_input('属于你想抓取的网页地址URL')
user_prompt = st.text_input('输入你想要从该网页获取知识的prompt')
3.4 基于scrapegraph-ai包构建图配置以及创建图逻辑
from scrapegraphai.graphs import SmartScraperGraph# 图配置信息,默认调用gpt3.5,其次embedding模型未设置,但阅读源码后,可以发现默认走的是openai的embedding模型
graph_config = {'llm': {'api_key': OPEN_API_KEY,'model': 'gpt-3.5-turbo','temperature': 0.1}
}# 创建直接图逻辑
smart_scraper_graph = SmartScraperGraph(prompt=user_prompt, # 用户输入的promptsource=url, # 用户输入的urlconfig=graph_config
)# 增加一个按钮进行爬取、解析及页面渲染
if st.button('爬取'):result = smart_scraper_graph.run()st.write(result)
3.5 运行启动
streamlit run scrape_web_openai.py3.6 底层原理
通过研读SmartScraperGraph源码,底层直接图逻辑的原理如下图所示。分为抓取、解析、RAG、答案生成,并默认以json格式输出
4. 效果
4.1 新闻类
网址:ps://news.sina.com.cn/w/2024-05-20/doc-inavwrxq4965190.shtml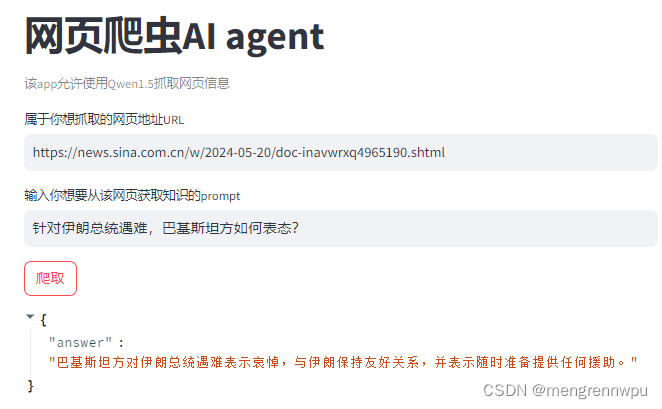
4.2 公众号
https://mp.weixin.qq.com/s/rFYXKiedqmVo5URDxlbHzA

针对一些简单的网页如新闻网页等,可以正常爬取,但响应时间在10s以上,针对一些复杂的页面,如包含鉴权、反爬机制等,可能无法正常爬取。
5. 总结
一句话足矣~
本文主要是通过Scrapegraph-ai集成gpt3.5实现一个简单的网页爬取并解析的demo应用,其中涉及到gpt3.5免费申请,Scrapegraph-ai底层原理简介,demo应用源码等。
之后会写一篇关于Qwen7B和BGE的相似度模型,与Scrapegraph-ai集成的demo应用,敬请期待 ~
6. 参考
1. Scrapegraph-ai: https://github.com/VinciGit00/Scrapegraph-ai
2. GPT_API_free: https://github.com/chatanywhere/GPT_API_free
