在网上做软件挣钱的网站微信朋友圈软文大全
最近做的项目里有涉及大模型,里面有一部分的功能是:
将图片输入VLM(视觉语言模型,我使用的是llava),询问图中最显著的物体,将其给出的答案作为基础分割模型(我使用的是Grounded-SAM)的text prompt,基础分割模型输出目标物体的mask
(可能会有uu疑问,为什么不直接问Grounded-SAM两次)
- 该项目目的是评估VLM的某项能力
- 基础分割模型的语言能力弱于VLM,输入的text prompt一般是单个词,指示希望分割出的目标
- 基础分割模型不能输出文本回答,无法进行“对话”
如果还是不理解这样做的理由(为什么不直接用既能多轮对话又能分割出mask的多模态大模型呢),那就把这篇当作两个大模型的使用记录吧
文章目录
- 整体流程
- 实现
- 使用模型
- LLaVA运行
- Grounded-SAM运行
- 代码
- 引入包
- llava_inference
- 非主要函数
- 包装Grounded-SAM的函数
- 主函数
- 运行bash文件
整体流程
为了方便理解,画了一个简单的示意图
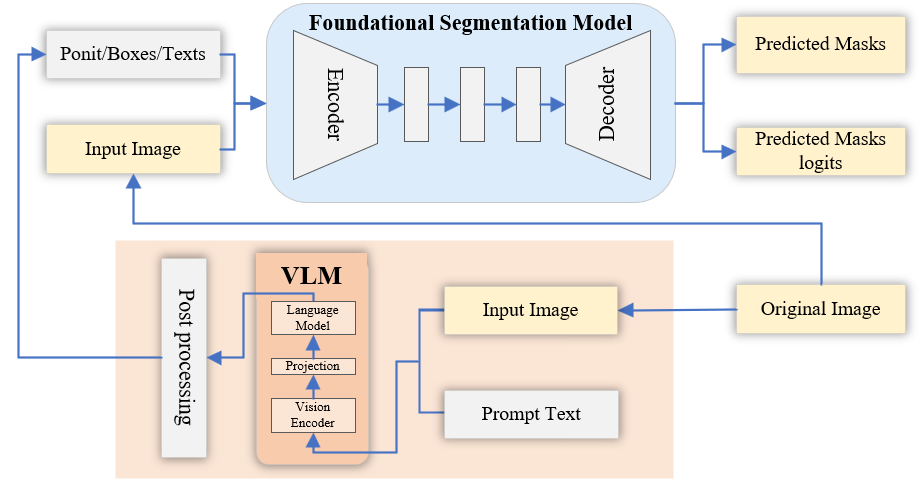
- 从右下开始看起,原图像(original image)和问题(prompt text)输入VLM,VLM输出回答,将回答进行后处理(post processing,如果答得准确,不需要提取关键字,也可以没有后处理)。
- 原图像(original image)和提示词(point/boes/texts)输入基础分割模型,输出预测的目标分割结果
Grounded-SAM的结果包含4个文件
- 原图像
- 带预测boxes+masks的原图
- 目标的实例分割图
- 记录预测目标分割的json文件
(1、2、3举例)
(4举例)



实现
使用模型
- VLM: llava-v1.5-7B
github: https://github.com/haotian-liu/LLaVA
huggingface(7B): https://huggingface.co/liuhaotian/llava-v1.5-7b/tree/main - 基础分割模型: Grounded-SAM
github:https://github.com/IDEA-Research/Grounded-Segment-Anything
需要下载两个权重,Grounded-SAM和SAM的,详细请见github
两个模型的运行网上已经有很多教程了,我给两个我参考过的,就不详细介绍了,会补充一些我认为需要注意的地方或是遇到的报错
LLaVA运行
参考:LLaVA模型安装、预测、训练详细教程
Grounded-SAM运行
参考:Grounded Segment Anything根据文字自动画框或分割环境配置和基本使用教程
代码
引入包
import argparse
import os
import sysimport numpy as np
import json
import torch
import re
import requests
from PIL import Image
from io import BytesIO
from transformers import TextStreamer
from torchvision import transformssys.path.append(os.path.join(os.getcwd(), "GroundingDINO"))
sys.path.append(os.path.join(os.getcwd(), "segment_anything"))# Grounding DINO
import GroundingDINO.groundingdino.datasets.transforms as T
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.util.utils import (clean_state_dict,get_phrases_from_posmap,
)# segment anything
from segment_anything import sam_model_registry, sam_hq_model_registry, SamPredictor
import cv2
import numpy as np
import matplotlib.pyplot as plt# llava
from llava.model.builder import load_pretrained_model
from llava.mm_utils import get_model_name_from_path
from llava.eval.run_llava import llava_inference, eval_model
# llava_inference是我根据eval_model修改的函数
from llava.constants import (IMAGE_TOKEN_INDEX,DEFAULT_IMAGE_TOKEN,DEFAULT_IM_START_TOKEN,DEFAULT_IM_END_TOKEN,
)
from llava.conversation import conv_templates, SeparatorStyle
from llava.model.builder import load_pretrained_model
from llava.utils import disable_torch_init
from llava.mm_utils import (process_images,tokenizer_image_token,get_model_name_from_path,
)
llava_inference
该项目需要进行多轮的对话,但又不想每次都加载一个新的模型,如你只进行一轮,可以直接在eval_model中增加返回: return outputs
def llava_inference(tokenizer, model, image_processor, args):# Modeldisable_torch_init()model_name = args.model_name# model_name = get_model_name_from_path(args.model_path)# tokenizer, model, image_processor, context_len = load_pretrained_model(# args.model_path, args.model_base, model_name# )qs = args.queryimage_token_se = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKENif IMAGE_PLACEHOLDER in qs:if model.config.mm_use_im_start_end:qs = re.sub(IMAGE_PLACEHOLDER, image_token_se, qs)else:qs = re.sub(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN, qs)else:if model.config.mm_use_im_start_end:qs = image_token_se + "\n" + qselse:qs = DEFAULT_IMAGE_TOKEN + "\n" + qsif "llama-2" in model_name.lower():conv_mode = "llava_llama_2"elif "mistral" in model_name.lower():conv_mode = "mistral_instruct"elif "v1.6-34b" in model_name.lower():conv_mode = "chatml_direct"elif "v1" in model_name.lower():conv_mode = "llava_v1"elif "mpt" in model_name.lower():conv_mode = "mpt"else:conv_mode = "llava_v0"if args.conv_mode is not None and conv_mode != args.conv_mode:print("[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}".format(conv_mode, args.conv_mode, args.conv_mode))else:args.conv_mode = conv_modeconv = conv_templates[args.conv_mode].copy()conv.append_message(conv.roles[0], qs)conv.append_message(conv.roles[1], None)prompt = conv.get_prompt()image_files = image_parser(args)images = load_images(image_files)image_sizes = [x.size for x in images]images_tensor = process_images(images, image_processor, model.config).to(model.device, dtype=torch.float16)input_ids = (tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).cuda())with torch.inference_mode():output_ids = model.generate(input_ids,images=images_tensor,image_sizes=image_sizes,do_sample=True if args.temperature > 0 else False,temperature=args.temperature,top_p=args.top_p,num_beams=args.num_beams,max_new_tokens=args.max_new_tokens,# use_cache=False,use_cache=True,)outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()return outputs
非主要函数
大部分都与原Grounded-SAM一致
def load_image(image_path):# load imageimage_pil = Image.open(image_path).convert("RGB") # load imagetransform = T.Compose([T.RandomResize([800], max_size=1333),T.ToTensor(),T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),])image, _ = transform(image_pil, None) # 3, h, wreturn image_pil, imagedef load_model(model_config_path, model_checkpoint_path, device):args = SLConfig.fromfile(model_config_path)args.device = devicemodel = build_model(args)checkpoint = torch.load(model_checkpoint_path, map_location="cpu")load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)print(load_res)_ = model.eval()return modeldef get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, device="cpu"
):caption = caption.lower()caption = caption.strip()if not caption.endswith("."):caption = caption + "."model = model.to(device)image = image.to(device)with torch.no_grad():outputs = model(image[None], captions=[caption])logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)logits.shape[0]# filter outputlogits_filt = logits.clone()boxes_filt = boxes.clone()filt_mask = logits_filt.max(dim=1)[0] > box_thresholdlogits_filt = logits_filt[filt_mask] # num_filt, 256boxes_filt = boxes_filt[filt_mask] # num_filt, 4logits_filt.shape[0]# get phrasetokenlizer = model.tokenizertokenized = tokenlizer(caption)# build predpred_phrases = []for logit, box in zip(logits_filt, boxes_filt):pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)if with_logits:pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")else:pred_phrases.append(pred_phrase)return boxes_filt, pred_phrasesdef show_mask(mask, ax, random_color=False):if random_color:color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)else:color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_box(box, ax, label):x0, y0 = box[0], box[1]w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2))ax.text(x0, y0, label)def save_mask_data(output_dir, mask_list, box_list, label_list):value = 0 # 0 for backgroundmask_img = torch.zeros(mask_list.shape[-2:])for idx, mask in enumerate(mask_list):# mask_img[mask.cpu().numpy()[0] == True] = value + idx + 1mask_img[mask.cpu().numpy()[0] == True] = 255plt.figure() # figsize=(10, 10)plt.imshow(mask_img.numpy(), cmap="gray")plt.axis("off")plt.savefig(os.path.join(output_dir, f"mask.png"),bbox_inches="tight",dpi=300,pad_inches=0.0,)json_data = [{"value": value, "label": "background"}]for label, box in zip(label_list, box_list):value += 1name, logit = label.split("(")logit = logit[:-1] # the last is ')'json_data.append({"value": value,"label": name,"logit": float(logit),"box": box.numpy().tolist(),})with open(os.path.join(output_dir, f"mask.json"), "w") as f:json.dump(json_data, f)包装Grounded-SAM的函数
def gSAM_main(args, prompt, image_path, grounded_sam_model, predictor):# cfgoutput_dir = args.output_dirbox_threshold = args.box_thresholdtext_threshold = args.text_thresholdgrounded_device = args.grounded_device# device = "cpu"# image_pil = Image.open(image_path).convert("RGB")image_pil, image = load_image(image_path)# run grounding dino modelboxes_filt, pred_phrases = get_grounding_output(grounded_sam_model,image,prompt,box_threshold,text_threshold,device=grounded_device,)image = cv2.imread(image_path) # torch.Size([3, 800, 1211])image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)predictor.set_image(image)size = image_pil.sizeH, W = size[1], size[0]for i in range(boxes_filt.size(0)):boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])boxes_filt[i][:2] -= boxes_filt[i][2:] / 2boxes_filt[i][2:] += boxes_filt[i][:2]boxes_filt = boxes_filt.cpu()transformed_boxes = predictor.transform.apply_boxes_torch(boxes_filt, image.shape[:2]).to(grounded_device)masks, _, _ = predictor.predict_torch(point_coords=None,point_labels=None,boxes=transformed_boxes.to(grounded_device),multimask_output=False,)# draw output imageplt.figure(figsize=(10, 10))plt.imshow(image)for mask in masks:show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)for box, label in zip(boxes_filt, pred_phrases):show_box(box.numpy(), plt.gca(), label)plt.axis("off")plt.savefig(os.path.join(output_dir, f"grounded_sam_output.png"),bbox_inches="tight",dpi=300,pad_inches=0.0,)save_mask_data(output_dir, masks, boxes_filt, pred_phrases)print(f"原图分割结果保存在:{os.path.abspath(output_dir)}")with open(os.path.join(output_dir, f"mask.json"), "r", encoding="utf8") as fp:json_data = json.load(fp)max_logit = json_data[1]["logit"]print(f"Prompt:{prompt}, Detected Object Number:{len(json_data)-1},Max Logit:{max_logit}")return max_logit, masks主函数
if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--model-path", type=str, default="facebook/opt-350m")parser.add_argument("--model-base", type=str, default=None)# parser.add_argument("--image-file", type=str, required=True)parser.add_argument("--device", type=str, default="cuda")parser.add_argument("--conv-mode", type=str, default=None)parser.add_argument("--temperature", type=float, default=0.2)parser.add_argument("--max-new-tokens", type=int, default=1024)parser.add_argument("--load-8bit", action="store_true")parser.add_argument("--load-4bit", action="store_true")parser.add_argument("--debug", action="store_true")# parser = argparse.ArgumentParser("Grounded-Segment-Anything Demo", add_help=True)parser.add_argument("--config", type=str, required=True, help="path to config file")parser.add_argument("--grounded_checkpoint", type=str, required=True, help="path to checkpoint file")parser.add_argument("--sam_version",type=str,default="vit_h",required=False,help="SAM ViT version: vit_b / vit_l / vit_h",)parser.add_argument("--sam_checkpoint", type=str, required=False, help="path to sam checkpoint file")parser.add_argument("--sam_hq_checkpoint",type=str,default=None,help="path to sam-hq checkpoint file",)parser.add_argument("--use_sam_hq", action="store_true", help="using sam-hq for prediction")parser.add_argument("--input_image", type=str, required=True, help="path to image file")# parser.add_argument("--text_prompt", type=str, required=True, help="text prompt")parser.add_argument("--output_dir","-o",type=str,default="outputs",required=True,help="output directory",)parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")parser.add_argument("--grounded_device",type=str,default="cpu",help="running on cpu only!, default=False",)args = parser.parse_args()# cfgconfig_file = args.config # change the path of the model config filegrounded_checkpoint = args.grounded_checkpoint # change the path of the modelsam_version = args.sam_versionsam_checkpoint = args.sam_checkpointsam_hq_checkpoint = args.sam_hq_checkpointuse_sam_hq = args.use_sam_hqimage_path = args.input_image# text_prompt = args.text_promptoutput_dir = args.output_dirbox_threshold = args.box_thresholdtext_threshold = args.text_thresholddevice = args.devicegrounded_device = args.grounded_device# 这部分有改动,在项目中两个模型会多次使用,这里各用一次model_path = args.model_pathmodel_base = args.model_baseprompt = ["What is the most obvious target object in the picture? Answer the question using a single word or phrase."]target = ""# make diros.makedirs(output_dir, exist_ok=True)# load imageimage_pil, image = load_image(image_path)# load modelmodel = load_model(config_file, grounded_checkpoint, device=grounded_device)# visualize raw imageimage_pil.save(os.path.join(output_dir, "image_0.png"))# initialize SAMpredictor = SamPredictor(sam_model_registry[sam_version](checkpoint=sam_checkpoint).to(grounded_device))# initialize llava# 禁用 Torch 初始化,可能由于多个进程同时访问 GPU 导致的问题# disable_torch_init()# load llava modelmodel_name = get_model_name_from_path(model_path)tokenizer, llava_model, image_processor, context_len = load_pretrained_model(model_path, model_base, model_name) llava_args = type("Args",(),{"model_path": model_path,"model_base": model_base,"model_name": model_name,"query": prompt[0],"conv_mode": None,"image_file": image_path,"sep": ",","temperature": 0,"top_p": None,"num_beams": 1,"max_new_tokens": 512,},)()# llava_output = eval_model(llava_args)llava_output = llava_inference(tokenizer, llava_model, image_processor, llava_args)# llava_output = re.findall(r"(.+?)</s>", llava_output)[0]# print("llava_output:", llava_output)if target == "": # 如果target没有预先设定target = llava_outputprint(f"将llava的输出{target}作为grounded-SAM的prompt输入")max_logit, _ = gSAM_main(args, target, args.input_image, model, predictor)
运行bash文件
项目运行目录: /{ }/Grounded-Segment-Anything/
/{ }/Grounded-Segment-Anything/test.sh如下
#!/bin/bashexport CUDA_VISIBLE_DEVICES="6,7"
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
export CUDA_HOME=/usr/local/cuda-11.7/python prompt_controller.py \--model-path /{}/llava-v1.5-7b \--config /{}/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint /{}/groundingdino_swint_ogc.pth \--sam_checkpoint /{}/sam_vit_h_4b8939.pth \--input_image /{}/test.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--grounded_device "cpu" \
前面的几个export请根据实际情况使用和更改
prompt_controller.py是文件名,请换成你自己的py名
–model-path: llava权重路径
–config: Grounded-SAM配置文件路径
–grounded_checkpoint: Grounded-SAM权重路径
–sam_checkpoint: SAM权重路径
–input_image: 输入的图片
–output_dir: Grounded-SAM输出结果的文件夹
–box_threshold/–text_threshold:
–grounded_device: Grounded-SAM使用设备(一般为cuda,但是我用gpu会报“_c”错,只好使用cpu推理)
运行项目时,cd /{ }/Grounded-Segment-Anything/, 在终端bash test.sh