山东中迅网站建设竞价排名机制
大数据学习笔记
MapReduce
一、MapReduce概述
- MapReduce是一个分布式运算程序的编程框架,是基于Hadoop的数据分析计算的核心框架。
MapReduce处理过程为两个阶段:Map和Reduce。
- Map负责把一个任务分解成多个任务;
- Reduce负责把分解后多任务处理的结果汇总。
- MapReduce优点
- MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。 - 良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。 - 高容错性
-MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。 - 适合PB级以上海量数据的离线处理
可以实现上千台服务器集群开发工作,提供数据处理能力。
- MapReduce缺点
- 不擅长实时计算
- 不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。 - 不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
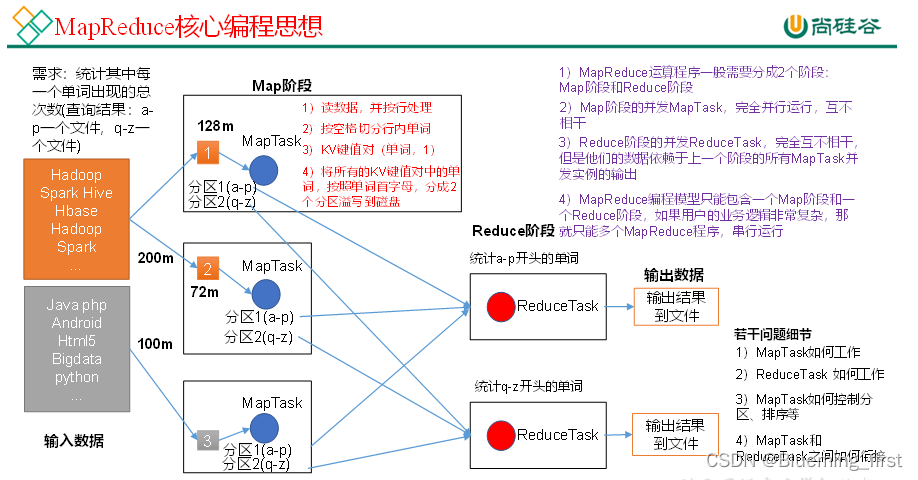
MapReduce核心编程思想
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
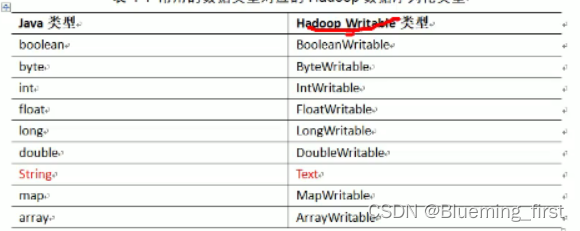
- 常用序列化类型
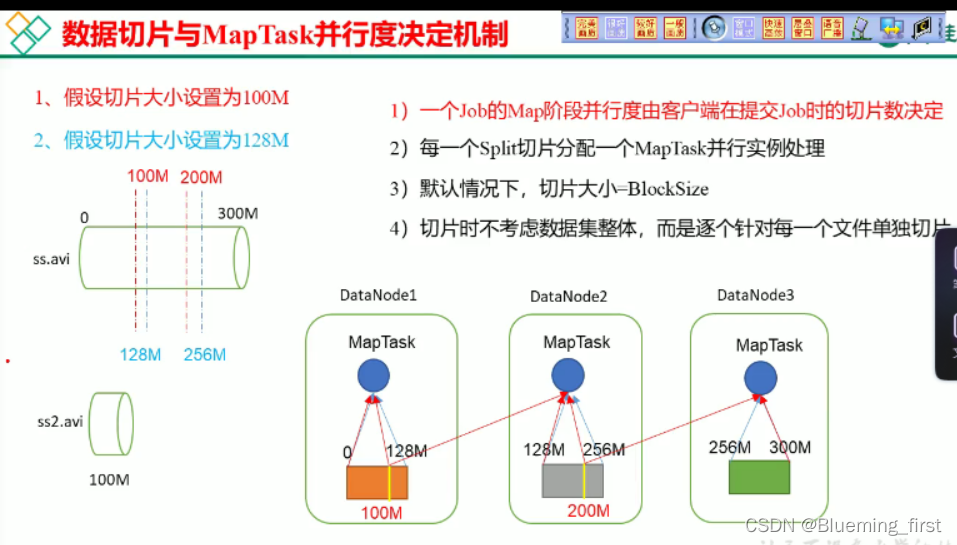
- MapTask的并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切分:数据切分只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。(只是在切分时默认按照块大小来切分)
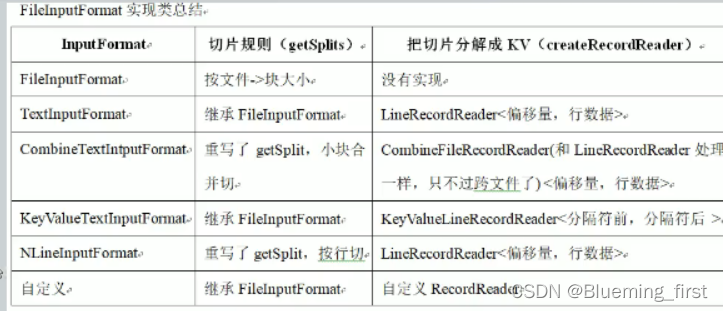
- FileInputFormat切片源码解析
1) 程序先找到你数据存储的目录。
2)开始遍历处理(规划切片)目录下的每一个文件
3)遍历第一个文件ss.txt
a) 获取文件大小fs.sizeOf(ss.txt)
b) 计算切片大小
computeSplitSize(Math.max(minSize.Math.min(maxSize,blocksize)))=blocksize=128M
c) 默认情况下,切片大小=blocksize
d)开始切,形成第一个切片:ss.txt–0:128M 第二个切片ss.txt–128:256M 第三个切片ss.txt–256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)
e)将切片信息写到一个切片规划文件中
f)整个切片的核心过程在getSplit()方法中完成
g) InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。 - FileInputFormat切片机制
1)简单地按照文件的内容长度进行切片
2)切片大小,默认等于Block大小
3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片

针对不同的文件类型FileInputFormat有不同的文件接口。 - CombineTextInputFormat切片机制
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。 - NLineInputFormat
NLineInputFormat每个map进程处理的InputSplit不再按Block块去划分,而是按NLineInputFormat指定的行数N来划分。 - NLineInputFormat
可指定分片数。
二、自定义inputformat案例
- 需求

- 自定义一个类继承FileInputFormat
1)重写isSplitable()方法,返回false不可分割
2)重写createRecordReader(),创建自定义的RecordReader对象,并初始化- 改写RecordReader,实现一次读取一个完整文件封装为KV
1)采用IO流一次读取一个文件输出到value中,因为设置了不可切片,最终把所有文件都封装到了value中
2)获取文件路径信息+名称,并设置key- 设置Driver
1)设置输入的inputFormat
2)设置输出的outputFormat

二、MapReduce详细工作流程
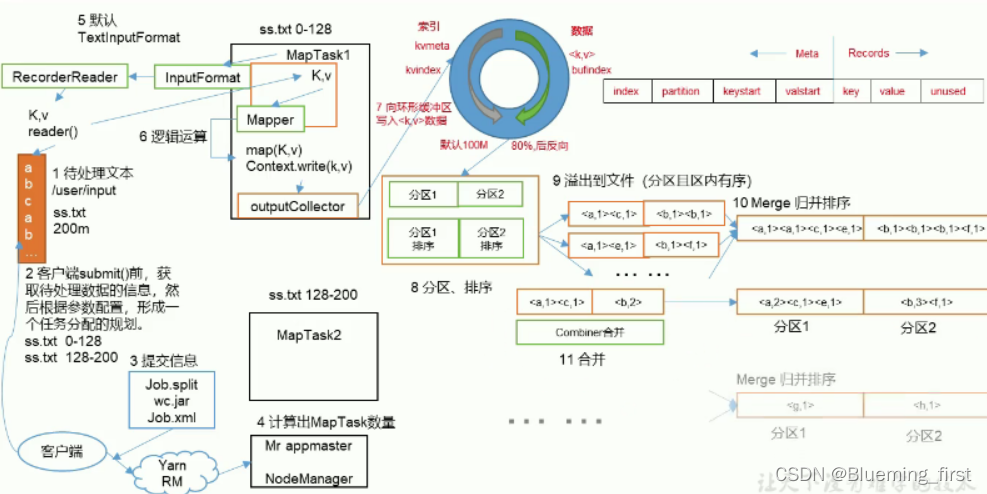
- MapReduce详细工作流程(一)
- 待处理文本 xx.txt
- 提交前要获取参数信息,形成一个任务分配的规划
- 提交信息 job(看是yarn 还是本地)
- APPmaster接收请求,根据切片来计算出开多少个MapTask
- 按照默认切片方式128M为一块,默认按照TextInputFormat读数据
- 将kv内容交给Mapper(逻辑运算内容) 业务逻辑
- 将数据写到环形缓冲区,包含元数据信息和真实输入的kv,元数据中包含索引、分区信息、key起始、value起始等信息。
- 分区、排序。
- 将缓冲区文件,溢写到文件,并分区且区内有序。
- Merge 归并,将溢写出的文件合并并排序
- 合并
- MapReduce详细工作流程(二)
- reduce根据当前分区的个数(MapTask数目)开启reduce Task进程
- 下载到ReduceTask本地磁盘,对每个分区做合并并进行归并排序
14.使用reduce方法 读文件数据- 分组
- 默认TextOutputFormat
三、Shuffle机制
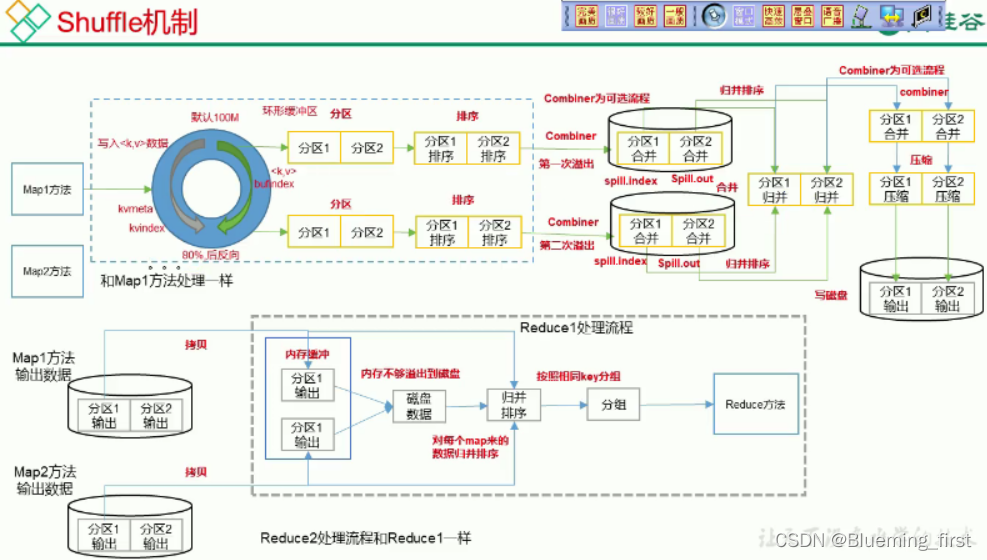
- Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。 - Map方法将 kv数据写入环形缓冲区,默认100M 当达到80%时会向磁盘溢写,(可选流程)将溢写到磁盘的分区进行合并排序
- reduce 拷贝maptask处理的分区数据放入内存,如果内存不够写入磁盘,对每一个map来的数据归并排序,按照相同的key执行reduce方法。
四、Partition分区
要求将统计结果按照条件输出到不同文件(分区)中去。
分区总结:

五、排序
指定排序规则。
- 概述
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对应MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它会从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以上传一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
2. 排序分类
1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
3)辅助排序
在reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
4)二次排序
自定义排序,如果compareTo中的判断条件为两个即为二次排序。