湖南网站建设什么优化
开放和高效的基础语言模型

Paper:https://arxiv.org/abs/2302.13971
Code: https://github.com/facebookresearch/llama
摘要
本文介绍了 LLaMA,这是⼀个包含 7B 到 65B 参数的基础语⾔模型的集合。作者在数万亿个令牌上训练模型,并表明可以仅使⽤公开可⽤的数据集来训练最先进的模型。特别是, LLaMA-13B 在⼤多数基准测试中都优于 GPT-3 (175B),并且 LLaMA 65B与最好的模型Chinchilla-70B和 PaLM-540B具有竞争⼒。
实验
数据集
训练数据集是多个来源的混合,如表 1 所示,涵盖了不同的领域。
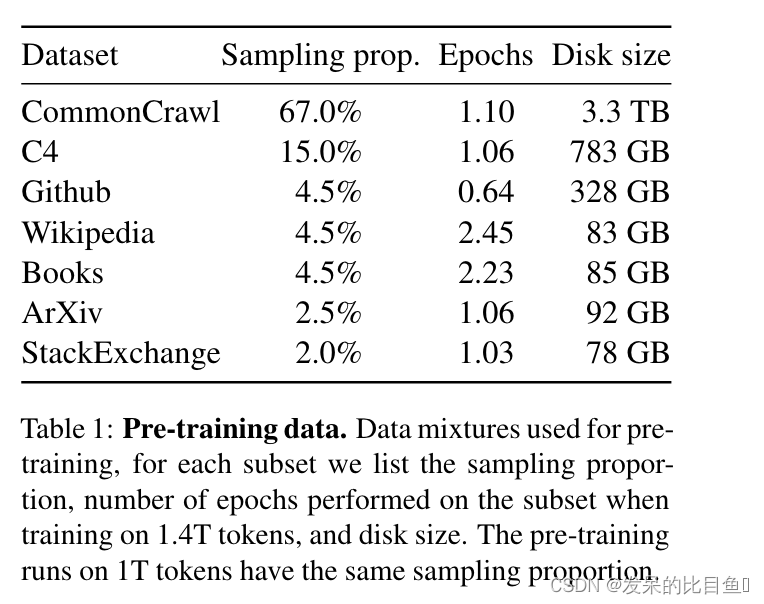
总体而言,作者的整个训练数据集在标记化后包含大约 1.4T 标记。对于作者的大部分训练数据,每个标记在训练过程中只使用一次
模型
整体架构仍然是Transformer的解码器模块,该模块参考论文Attention is all you need。下面是在Transformer架构上的进一步的3个改进。
- 使用RMSNorm(即Root Mean square Layer Normalization)对输入数据进行标准化,RMSNorm可以参考论文:Root mean square layer normalization。
原始Normalization:
μ = 1 n ∑ i = 1 n a i , σ = 1 n ∑ i = 1 n ( a i − μ ) 2 \mu=\frac{1}{n} \sum_{i=1}^n a_i, \quad \sigma=\sqrt{\frac{1}{n} \sum_{i=1}^n\left(a_i-\mu\right)^2} μ=n1∑i=1nai,σ=n1∑i=1n(ai−μ)2
RMSNorm:
a ˉ i = a i RMS ( a ) g i , where RMS ( a ) = 1 n ∑ i = 1 n a i 2 \bar{a}_i=\frac{a_i}{\operatorname{RMS}(\mathbf{a})} g_i, \quad \text { where } \operatorname{RMS}(\mathbf{a})=\sqrt{\frac{1}{n} \sum_{i=1}^n a_i^2} aˉi=RMS(a)aigi, where RMS(a)=n1∑i=1nai2 - 使用激活函数SwiGLU, 该函数可以参考PALM论文:Glu variants improve transformer。作者用SwiGLU激活函数代替ReLU非线性,以提高性能。
- 使用Rotary Embeddings进行位置编码,该编码可以参考论文 Roformer: Enhanced transformer with rotary position embedding。作者删除了绝对位置嵌入,取而代之的是在网络的每一层添加了旋转位置嵌入 (RoPE)。
优化器
采用AdamW optimizer优化器,该优化器可以参考论文Decoupled weight decay regularization。具有以下超参数:β1 = 0.9,β2 = 0.95。作者使用余弦学习率计划,使最终学习率等于最大学习率的 10%。作者使用 0.1 的权重衰减和 1.0 的梯度裁剪。并根据模型的大小改变学习率和批量大小。
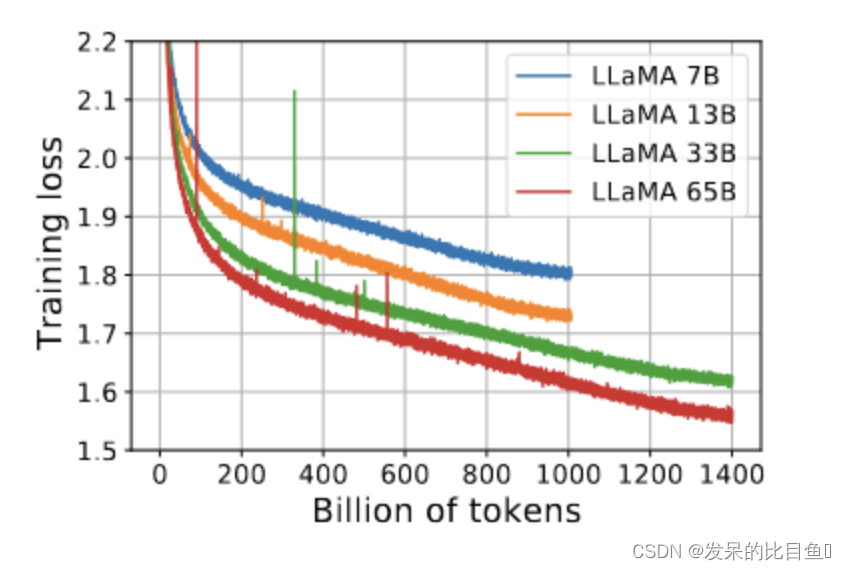
LLaMA-33B 和 LLaMA65B 在 1.4T tokens上进行了训练。较小的模型是在 1.0T tokens上训练的.
在训练 65B 参数模型时,作者的代码在具有80GB RAM 的 2048 A100 GPU 上处理大约 380 个令牌/秒/GPU。这意味着对包含 1.4T 令牌的数据集进行训练大约需要 21 天
其他有效改进措施
- 使用 随机多头注意力机制(causal multi-head attention) 提高模型的训练速度。该机制的实现借用了xformers库,它的思路是不存储注意力权重,不计算其中注意力得分。
- 手动实现了Transformer的激活函数,而没有用pytorch库的autograd,以得到更优的训练速度。同时使用了并行化技术提高训练速度。这两个改进点可以参考论文:Reducing activation recomputation in large transformer models.
参考
https://blog.csdn.net/a1920993165/article/details/130044242