阿里巴巴做国际网站要多少钱看颜色应该搜索哪些词汇
为什么我们在vs等编译器上写出的代码通过运行就会实现相关功能呢?
解决这个问题的关键就是关于编译与链接的知识。
首先从大的分类里有两部分:编译和链接
而编译这一大的部分又分为预处理(也叫预编译),编译,汇编三个小的部分。
第一步:
我们一开始写代码之前,要创建一个文件,这个文件就叫源文件,而引用#include<stdio.h>等一系列的文件就叫头文件(.h就是.head的缩写),我们可以创建多个源文件,也可以同时引用<string.h>,<math.h>多个头文件,它们全部都包括在一个以.c结束的文件里,也就是说,我们写的代码全部放在了.c文件里面了。

第二步:
然后我们使用的vs,dev等编译器就会经过编译(预处理,编译,汇编三部分)成为目标文件(windows以.obj为后缀的文件,Linux以.o为后缀的文件)
预处理——大致四个步骤
一:编译器会将我们写的代码里的#define删除,同时展开所有的宏定义
二:我们引用的头文件也会被全部展开,变成几十行的代码
三:不仅如此,还会处理所有的条件编译指令,如#if,#endif等等
四:我们写的注释也会全部消失不见
最后经过预处理后的文件就会变成以.i为后缀的文件
编译——大致三个步骤(将我们的高级语言编译成汇编语言再编译成机器指令)
一:词法分析
词法分析就是编译器中的扫描器将我们写的代码全部分解为每个记号(相当于一个英语句子拆分成每个字母)
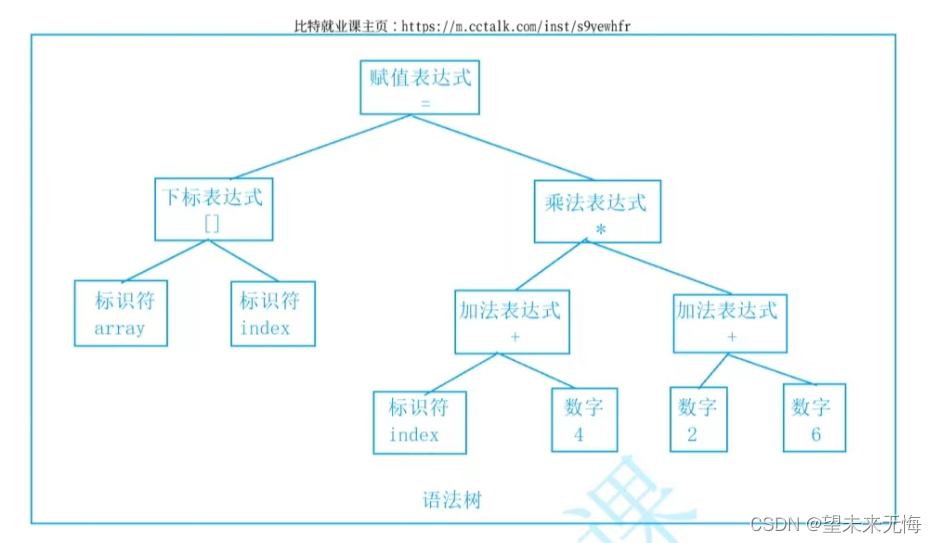
例如array[index]=(index+4)*(2+6)就会拆分成以下16个记号

二:语法分析
在刚刚词法分析中拆分的各个记号中,编译器中的语法分析器开始分析每个记号组成的语句含义(就相当于在一堆积木中,选出哪几块积木可以搭建成门,哪几块积木可以搭建成桥,开始分类)
只不过分类的方式采用树的方式,形成语法树
三:语义分析
在刚刚形成的语法树的基础上,编译器中的语义分析器会分析声明和类型的匹配,类型的转换等,这个阶段会报告错误的语法信息

汇编—— 一个步骤
将汇编代码转变为机器可执行的指令(也就是二进制语言,我们无法看懂的语言)
第三步:
链接(将目标文件.obj转换为可执行文件.exe)
这一部分主要就是将所有的目标文件.obj合并(链接)为一个可执行文件.exe,其中大致分为两个部分,一部分是数据,另一部分叫做符号表(记录函数的名字和地址),每个全局变量和函数(不包括局部变量,因为它的空间在栈帧中),所有的数据合并在一起,同时符号表也合并在一起,此时如果有些函数一开始是使用extern声明的,然后又编写了该函数,那么此时符号表中就会出现两个该函数名和该函数的地址,因为声明函数的时候什么都不知道,所以机器会将该声明的函数地址记为非法地址,而当我们真正写函数时,机器才会给我们一个有效地址,当符号表合并时,就会出现重复的函数名,此时机器就会比较这两个地址哪一个是该函数的真正地址,将真正的地址覆盖非法地址,这个地址修改的过程也被叫做:重定义

所以当我们函数名写错时,自然也就找不到重复的函数名,引用函数时也就找不到创建函数的地址
最后形成的可执行文件.exe对于计算机来说就能看懂了,于是我们写的程序也就经过计算机最后运行出来了。