公司电脑做网站今日足球赛事推荐
6.1 使用scikit-learn构建模型
- 6.1.1 使用sklearn转换器处理数据
- 6.1.2 将数据集划分为训练集和测试集
- 6.1.3 使用sklearn转换器进行数据预处理与降维
- 1、数据预处理
- 2、PCA降维算法
- 代码
scikit-learn(简称sklearn)库整合了多种机器学习算法,可以帮助使用者在数据分析过程中快速建立模型,且模型接口统一,使用起来非常方便。同时,sklearn拥有优秀的官方文档,知识点详尽,内容丰富,是入门学习sklearn的最佳内容。
开源机器学习库:https://scikit-learn.org/stable/index.html 开源机器学习库

涵盖分类、回归、聚类、降维、模型选择、数据预处理六大模块
6.1.1 使用sklearn转换器处理数据
sklearn提供了model_selection模型选择模块、preprocessing数据预处理模块与decomoisition特征分解模块。通过这三个模块能够实现数据的预处理与模型构建前的数据标准化、二值化、数据集的分割、交叉验证和PCA降维等工作。
datasets模块常用数据集的加载函数与解释如下表所示:
波士顿房价、鸢尾花、红酒数据集

使用sklearn进行数据预处理会用到sklearn提供的统一接口——转换器(Transformer)。
加载后的数据集可以视为一个字典,几乎所有的sklearn数据集均可以使用data,target,feature_names,DESCR分别获取数据集的数据,标签,特征名称和描述信息。
from sklearn.datasets import load_boston # 波士顿房价数据集
from sklearn.datasets import load_breast_cancer # 癌症数据集
# cancer = load_breast_cancer() # 读取数据集
# print("长度: ", len(cancer))
# print("类型: ", type(cancer))
boston = load_boston() # 读取数据集
print("长度: ", len(boston))
# print(boston)
print('data:\n', boston['data']) # 数据
print('target:\n', boston['target']) # 标签
print('feature_names:\n', boston['feature_names']) # 特征名称
print('DESCR:\n', boston['DESCR']) # 描述信息
6.1.2 将数据集划分为训练集和测试集
在数据分析过程中,为了保证模型在实际系统中能够起到预期作用,一般需要将样本分成独立的三部分:
- 训练集(train set):用于训练模型。
- 验证集(validation set):用于训练过程中对模型性能评估。
- 测试集(test set):用于检验最终的模型的性能。
典型的划分方式是训练集占总样本的50%,而验证集和测试集各占25%。
K折交叉验证法
当数据总量较少的时候,使用上面的方法将数据划分为三部分就不合适了。
常用的方法是留少部分做测试集,然后对其余N个样本采用K折交叉验证法,基本步骤如下:
- 将样本打乱,均匀分成K份。
- 轮流选择其中K-1份做训练,剩余的一份做验证。
- 计算预测误差平方和,把K次的预测误差平方和的均值作为选择最优模型结构的依据。
sklearn的model_selection模块提供了train_test_split函数,能够对数据集进行拆分,其使用格式如下。
sklearn.model_selection.train_test_split(*arrays, **options)

将数据集划分为训练集和测试集
- train_test_split函数根据传入的数据,分别将传入的数据划分为训练集和测试集。
- 如果传入的是1组数据,那么生成的就是这一组数据随机划分后训练集和测试集,总共2组。
- 如果传入的是2组数据,则生成的训练集和测试集分别2组,总共4组。
- train_test_split是最常用的数据划分方法,在model_selection模块中还提供了其他数据集划分的函数,如PredefinedSplit,ShuffleSplit等。
from sklearn.datasets import load_boston # 波士顿房价数据集
boston = load_boston() # 读取数据集
# 划分数据集
from sklearn.model_selection import train_test_split
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
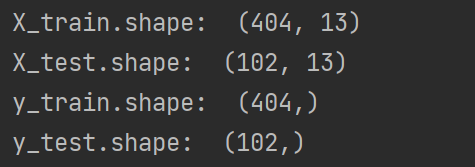
print("X_train.shape: ", X_train.shape)
print("X_test.shape: ", X_test.shape)
print("y_train.shape: ", y_train.shape)
print("y_test.shape: ", y_test.shape)
6.1.3 使用sklearn转换器进行数据预处理与降维
在数据分析过程中,各类特征处理相关的操作都需要对训练集和测试集分开操作,需要将训练集的操作规则,权重系数等应用到测试集中。如果使用pandas,则应用至测试集的过程相对烦琐,使用sklearn转换器可以解决这一困扰。
sklearn把相关的功能封装为转换器(transformer)。使用sklearn转换器能够实现对传入的NumPy数组进行标准化处理,归一化处理,二值化处理,PCA降维等操作。转换器主要包括三个方法:fit、transform 和 fit-transform。

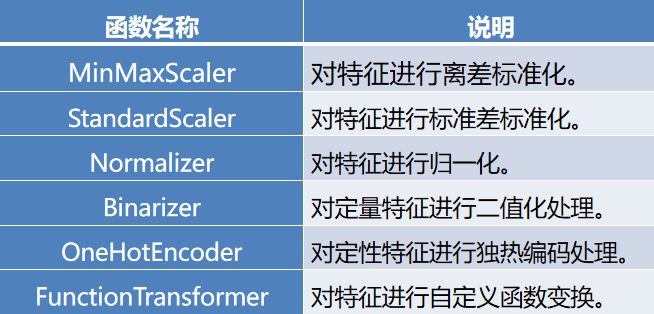
1、数据预处理
sklearn部分预处理函数与其作用
2、PCA降维算法
sklearn还提供了降维算法,特征选择算法,这些算法的使用也是通过转换器的方式。

代码
from sklearn.datasets import load_boston # 波士顿房价数据集
boston = load_boston() # 读取数据集
# print("长度: ", len(boston))
# # print(boston)
# print('data:\n', boston['data']) # 数据
# print('target:\n', boston['target']) # 标签
# print('feature_names:\n', boston['feature_names']) # 特征名称
# print('DESCR:\n', boston['DESCR']) # 描述信息# 划分数据集
from sklearn.model_selection import train_test_split
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# print("X_train.shape: ", X_train.shape)
# print("X_test.shape: ", X_test.shape)
# print("y_train.shape: ", y_train.shape)
# print("y_test.shape: ", y_test.shape)
# 离差标准化
import numpy as np
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(X_train) # 生成规则
# 将规则用于训练集
data_train = Scaler.transform(X_train)
# 将规则用于训练集
data_test = Scaler.transform(X_test)
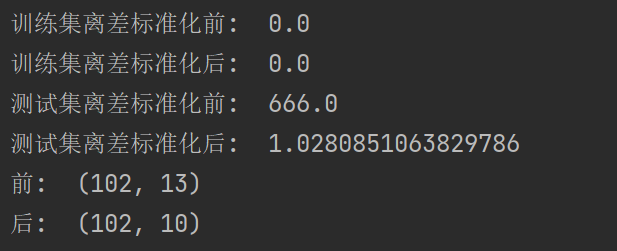
print("训练集离差标准化前: ", np.min(X_train))
print("训练集离差标准化后: ", np.min(data_train))
print("测试集离差标准化前: ", np.max(X_test))
print("测试集离差标准化后: ", np.max(data_test))# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=10).fit(data_train) # 生成规则
# 将规则用于训练集
pca_test = pca.transform(data_test)
print("前: ", data_test.shape)
print("后: ", pca_test.shape)