合肥外贸网站建设公司排名seo优化查询
目录
1.Transformer宏观结构
2.Transformer结构细节
2.1输入
2.2编码部分
2.3解码部分
2.4多头注意力机制
2.5线性层和softmax
2.6 损失函数
3.参考代码
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
Transformer整体结构图,与seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder),接下来拆解Transformer。
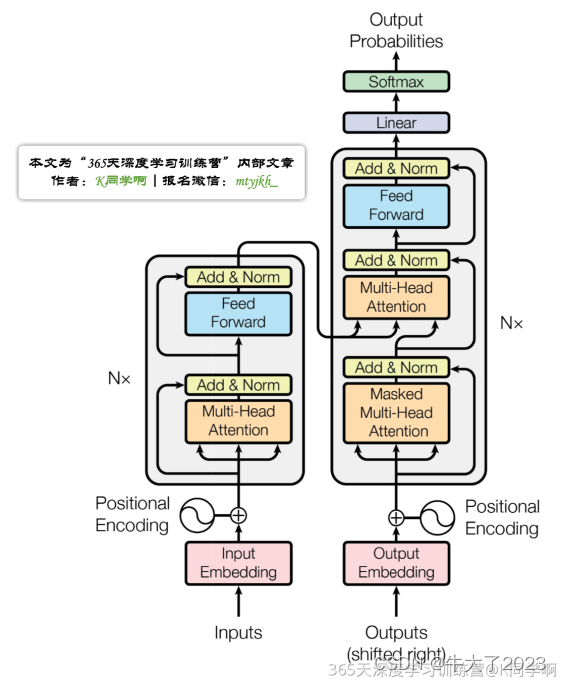
1.Transformer宏观结构
Transformer模型类似于seq2seq结构,包含编码部分和解码部分。不同之处在于它能够并行计算整个序列输入,无需按时间步进行逐步处理。
其宏观结构如下:

其中,每层encoder由两部分组成:
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,FFNN)
decoder在encoder的Self-Attention和FFNN中间多加了一个Encoder-Decoder Attention层。该层的作用是帮助解码器集中注意力于输入序列中最相关的部分。

2.Transformer结构细节
2.1输入
Transformer的数据输入与seq2seq不同。除了词向量,Transformer还需要输入位置向量,用于确定每个单词的位置特征和句子中不同单词之间的距离特征。
2.2编码部分
编码部分的输入文本序列经过处理后得到向量序列,送入第一层编码器。每层编码器输出一个向量序列,作为下一层编码器的输入。第一层编码器的输入是融合位置向量的词向量,后续每层编码器的输入则是前一层编码器的输出。
2.3解码部分
最后一个编码器输出一组序列向量,作为解码器的K、V输入。
解码阶段的每个时间步输出一个翻译后的单词。当前时间步的解码器输出作为下一个时间步解码器的输入Q,与编码器的输出K、V共同组成下一步的输入。重复此过程直到输出一个结束符。
解码器中的 Self-Attention 层,和编码器中的 Self-Attention 层的区别:
- 在解码器里,Self-Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self-Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将Attention Score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和Value矩阵来自于编码器最终的输出。
2.4多头注意力机制
Transformer论文引入了多头注意力机制(多个注意力头组成),以进一步完善Self-Attention。
- 它扩展了模型关注不同位置的能力
- 多头注意力机制赋予Attention层多个“子表示空间”。
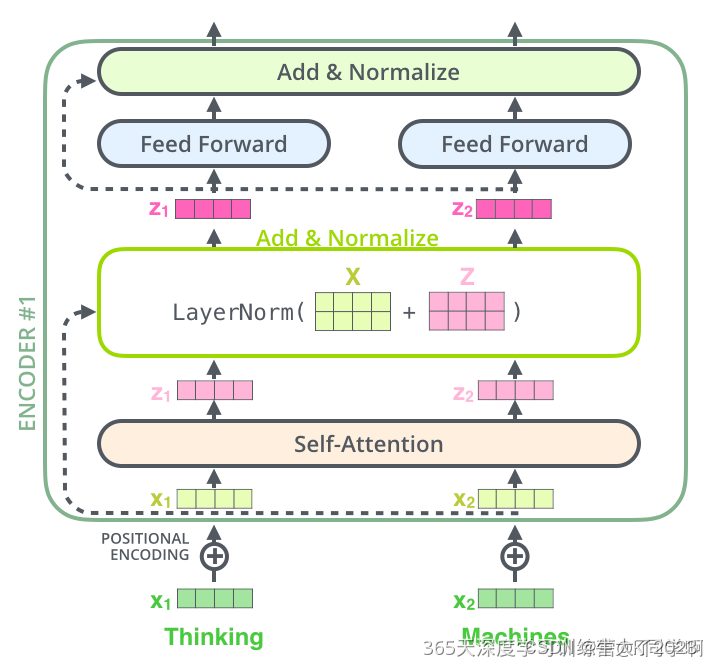
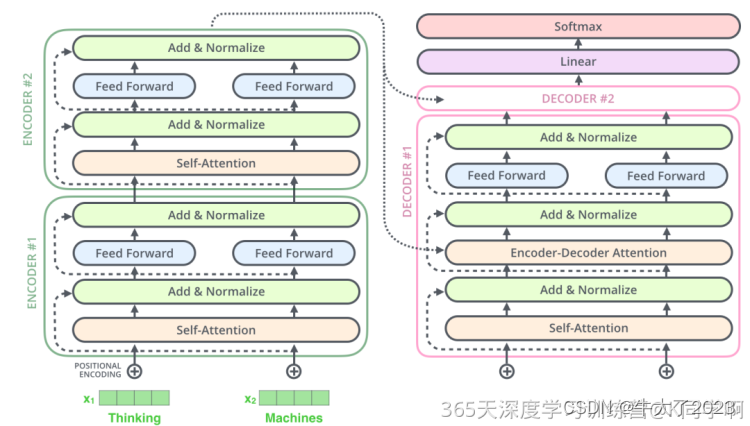
残差链接&Normalize: 编码器和解码器的每个子层(Self-Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization),细节如下图
2.5线性层和softmax
Decoder最终输出一个浮点数向量。通过线性层和Softmax,将该向量转换为一个包含模型输出词汇表中每个单词分数的logits向量(假设有10000个英语单词)。Softmax将这些分数转换为概率,使其总和为1。然后选择具有最高概率的数字对应的词作为该时间步的输出单词。
2.6 损失函数
在Transformer训练过程中,解码器的输出和标签一起输入损失函数,以计算损失(loss)。最终,模型通过方向传播(backpropagation)来优化损失。
3.参考代码
class SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N =query.shape[0]value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1]# split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys)# queries shape: (N, query_len, heads, heads_dim)# keys shape : (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim)# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, heads_dim)# (N, query_len, heads, head_dim)out = self.fc_out(out)return outclass TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion*embed_size),nn.ReLU(),nn.Linear(forward_expansion*embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass Encoder(nn.Module):def __init__(self,src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length,):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion,)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return outclass DecoderBlock(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(DecoderBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):attention = self.attention(x, x, x, trg_mask)query = self.dropout(self.norm(attention + x))out = self.transformer_block(value, key, query, src_mask)return outclass Decoder(nn.Module):def __init__(self,trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length,):super(Decoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(trg_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([DecoderBlock(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x ,enc_out , src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out =self.fc_out(x)return outclass Transformer(nn.Module):def __init__(self,src_vocab_size,trg_vocab_size,src_pad_idx,trg_pad_idx,embed_size = 256,num_layers = 6,forward_expansion = 4,heads = 8,dropout = 0,device="cuda",max_length=100):super(Transformer, self).__init__()self.encoder = Encoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length)self.decoder = Decoder(trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length)self.src_pad_idx = src_pad_idxself.trg_pad_idx = trg_pad_idxself.device = devicedef make_src_mask(self, src):src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)# (N, 1, 1, src_len)return src_mask.to(self.device)def make_trg_mask(self, trg):N, trg_len = trg.shapetrg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)return trg_mask.to(self.device)def forward(self, src, trg):src_mask = self.make_src_mask(src)trg_mask = self.make_trg_mask(trg)enc_src = self.encoder(src, src_mask)out = self.decoder(trg, enc_src, src_mask, trg_mask)return out