如何网站平台建设好长春seo快速排名
这篇文章是在完成 HW02 的过程中所产生的,是关于各 scheduler (ReduceLROnPlateau(),CosineAnnealingLR(),CosineAnnealingWarmRestarts())使用的对比实验。
起因是为了在 Kaggle 上跑出更高的成绩,但结果确出乎我的意料,为了工作不白费,我决定将它们的结果重新可视化分享给你们。我一开始没有过多的修改初始配置,这篇文章的目的仅仅是为了给你展现不同 scheduler 下的学习率变化以及对实验结果的影响(片面的)。
时间原因我仅在这个数据集上跑了对比实验。
文章目录
- 开始实验
- **ReduceLROnPlateau()**
- 学习率变化曲线
- 实验数据
- **Kaggle 分数: 0.74427**
- **CosineAnnealingLR()**
- 学习率变化曲线
- 实验数据
- **Kaggle 分数: 0.74391(没有提升)**
- **CosineAnnealingWarmRestarts()**
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74328(没有提升)**
- T_0 *= 2
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74403(没有提升)**
- **no scheduler**
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74408**
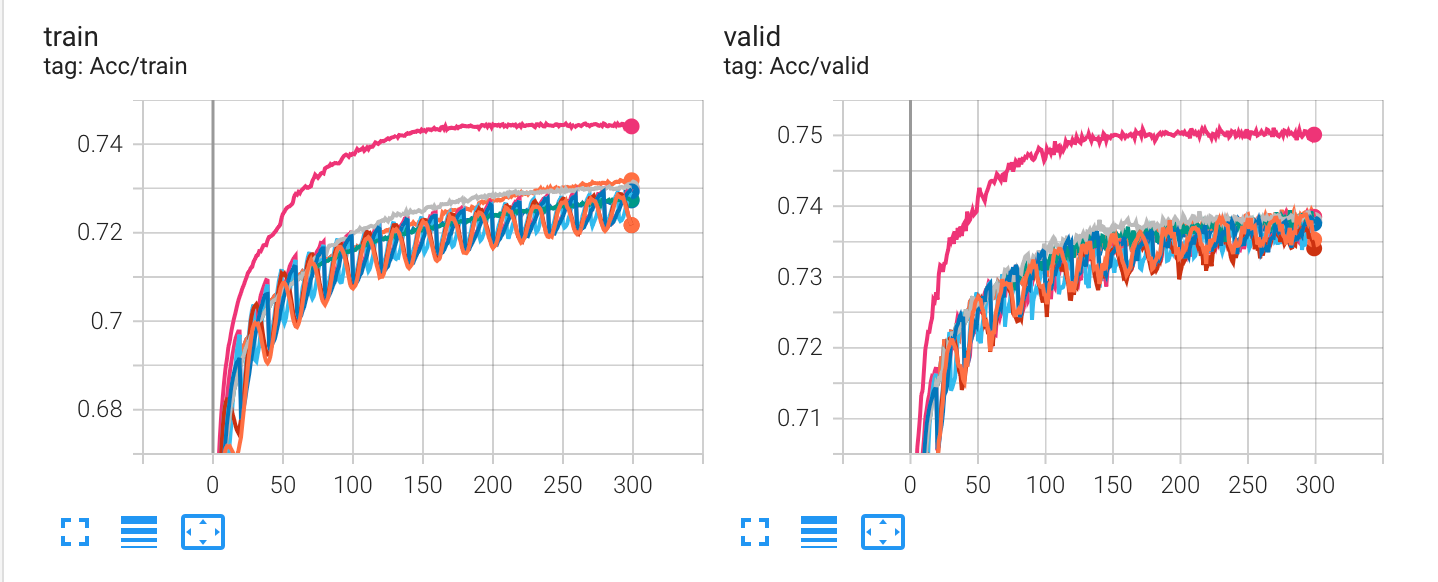
- **实验结果对比**
- 修改 lr=2.5e-4,重新实验
- **实验结果对比**
- 总结
开始实验
为了对比,每个 scheduler 都跑了 300 个epoch,可能不多,但也能看出些端倪。
这里贴一下我的其他参数,如果不需要做这个 HW,可以跳过这段往下看,并不影响。
跑 300 个 epoch 是因为在这个参数的设置(请勿模仿)下,大概到 300 就没有什么波动了。
"""dropout(p=0.25)"""concat_nframes = 15 # the number of frames to concat with, n must be odd (total 2k+1 = n frames) train_ratio = 0.95 # the ratio of data used for training, the rest will be used for validation# training parameters seed = 1213 # random seed batch_size = 512 # batch size num_epoch = 300 # the number of training epoch learning_rate = 5e-4 # learning ratehidden_layers = 6 # the number of hidden layers hidden_dim = 512 # the hidden dim
最初,我增加了一个自动调整 learning_rate 的 scheduler,选择的是 torch.optim.lr_scheduler 中的 ReduceLROnPlateau()。
ReduceLROnPlateau()
先介绍一下参数方便理解:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。mode (str):指标的模式。可以是“min”或“max”。如果是“min”,那么当指标停止降低时将调整学习率;如果是“max”,那么当指标停止升高时将调整学习率。factor (float):学习率缩小的因子。新学习率=旧学习率 * factor。注意,factor 不能大于1。patience (int):如果指标没有改善,则等待多少个epoch来调整学习率。threshold (float):指标的变化量阈值,如果小于此值,则将其视为没有改进。threshold_mode (str):判断阈值的模式。可以是“rel”或“abs”。如果是“rel”,动态阈值等于最优值乘以(1+threshold)(在’max’模式下)或最优值乘以(1-threshold)(在’min’模式下)。在’abs’模式下,动态阈值等于最优值加上threshold(在’max’模式下)或最优值减去threshold(在’min’模式下)。cooldown (int):表示在减小学习率之后等待几个epoch才能再次减小学习率。min_lr (float or list):学习率的下限。eps (float):表示应用于学习率的最小衰减量。如果新旧学习率之间的差异小于eps,则更新会被忽略。verbose (bool):如果为True,则在调整学习率时打印更新的消息。
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.8, patience=10, threshold=0.001) # 如果 10 个 epoch 后都没有提升,lr *= factorfor epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step(metric) # 根据 metric 更新学习率
学习率变化曲线

实验数据
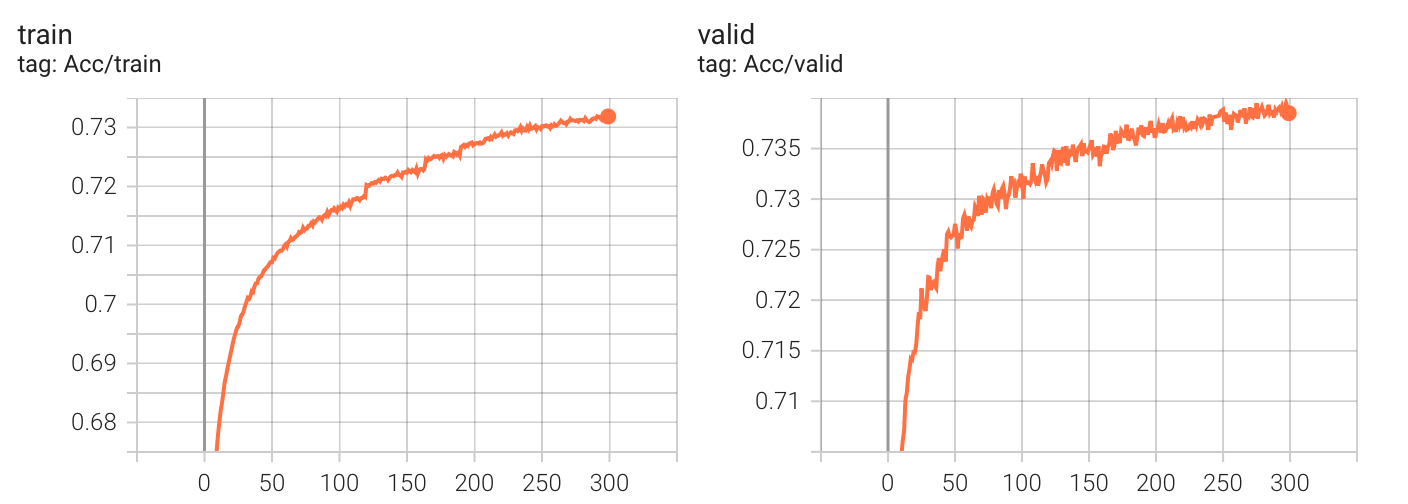
Kaggle 分数: 0.74427
最初选择 ReduceLROnPlateau() 的原因是基于一个设想的较乐观的情况:只要慢慢减少学习率一定会收敛到优秀的解。
当时发现了好几种scheduler,但看到根据 epoch 变化 learing rate 的 scheduler(比如 StepLR,ExponentialLR),觉得完全不如根据实验结果动态变化的 ReduceLROnPlateau 便没有进行选择。
看到这里你应该仅仅对 ReduceLROnPlateau() 有了简单的认识,不妨继续往下看,看看实验对比。
在 acc 卡住后,我试图去寻找其他的 scheduler,看能不能让 learning rate 在中途变大跳出一些区域后再变小,然后发现还有周期性变化的 scheduler(比如 CosineAnnealingLR,CyclicLR),于是,我尝试修改成 CosineAnnealingLR()。
CosineAnnealingLR()
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。T_max (int): 表示半个周期的长度。例如,如果T_max=10,则学习率在第0个epoch时为最大值,在第0到第10个epoch之间以余弦函数形式逐渐减小,在第10个epoch时达到最小值,在第11到第20个epoch之间以余弦函数形式逐渐增大,在第20个epoch时回到最大值。eta_min (float): 表示学习率的最小值,在学习率下降到这个值之后,就不再下降了。默认为0。last_epoch (int): 表示上一次更新学习率的epoch索引。默认为-1,表示还没有开始训练。这个参数用于恢复训练时使用,可以将其设置为已经训练的epoch数减 1。verbose (bool):如果为True,则在调整学习率时打印更新的消息。
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-7)for epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step() # 更新学习率
学习率变化曲线

实验数据
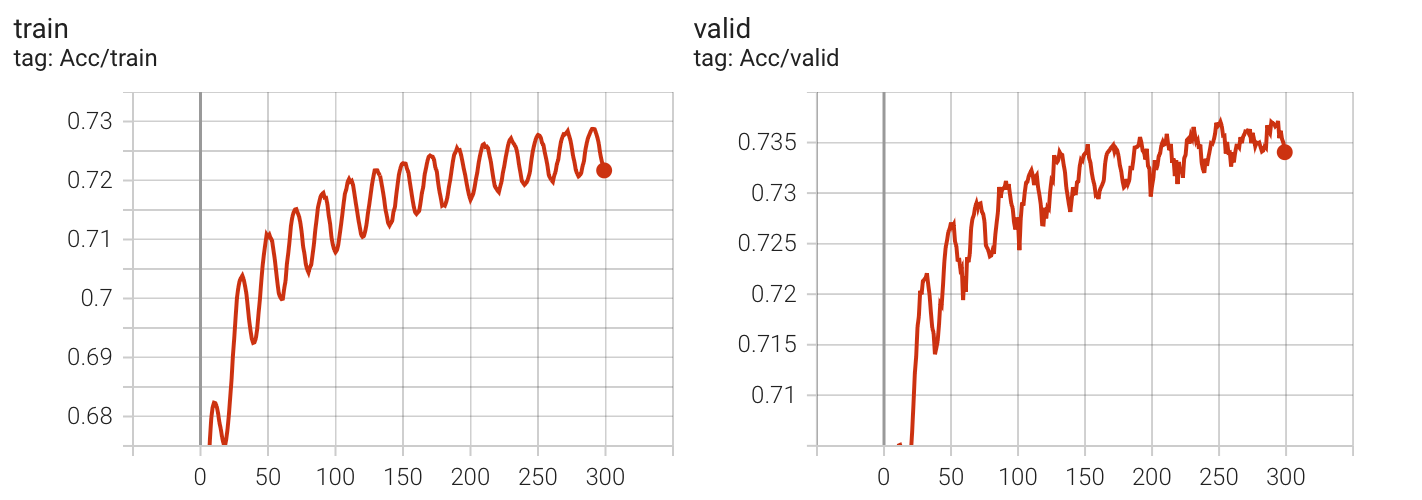
Kaggle 分数: 0.74391(没有提升)
这个 scheduler 中的 learning rate 变化曲线与余弦函数一致,但观察发现,CosineAnnealLR 的周期性变化似乎让收敛的过程变得曲折(多次实验效果都类似)。
观察 acc 和 lr 的变化:每一次 lr 逐步上升都会让 acc 下降。于是我想着有没有一种 scheduler,让 lr 跳过逐步上升的过程,于是找到了 CosineAnnealingWarmRestarts,这个 scheduler 会让 learning rate 在周期的最后瞬间上升 ,这个概念在李宏毅老师过去的视频中也有说到,即:warm restart。
CosineAnnealingWarmRestarts()
torch.optim.lr_scheduler.``CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。T_0 (int): 表示第一次restart的epoch,即在T_0个epoch后,学习率将回到最高点,重新开始下降。默认值为10。T_mult (float): 表示每次restart之后T_0的值将乘以T_mult。默认值为1。eta_min (float): 表示学习率的最小值,在学习率下降到这个值之后,就不再下降了。默认为0。last_epoch (int): 表示上一次更新学习率的epoch索引。默认为-1,表示还没有开始训练。这个参数用于恢复训练时使用,可以将其设置为已经训练的epoch数减 1。verbose (bool):如果为True,则在调整学习率时打印更新的消息
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=1, eta_min=1e-7)for epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step() # 更新学习率
学习率变化曲线

实验结果
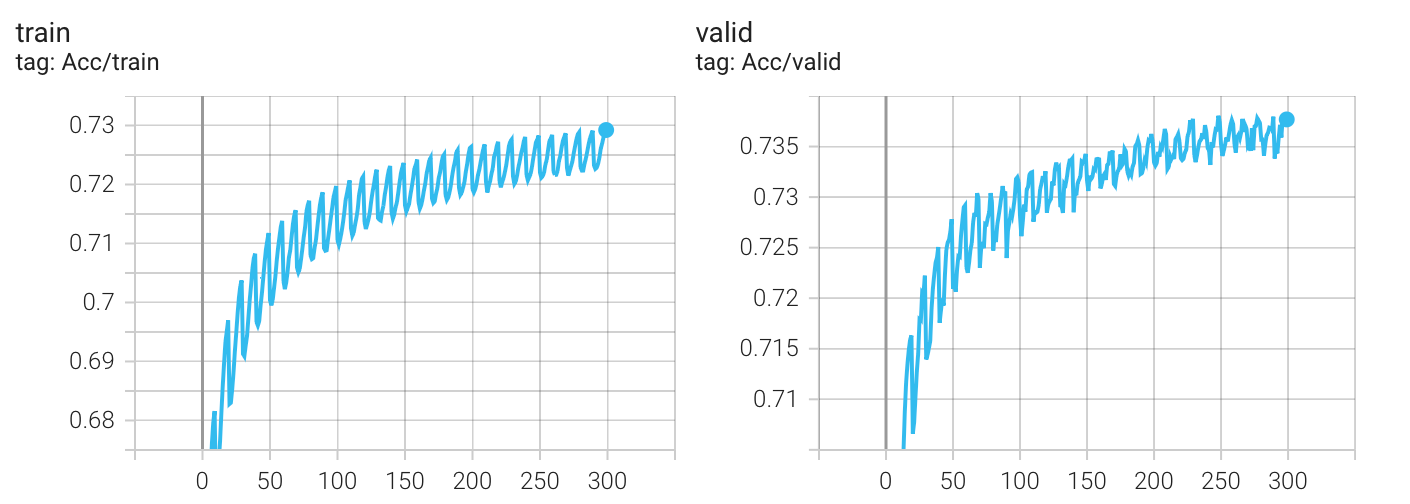
Kaggle 分数: 0.74328(没有提升)
我以为实验结果会变得更好,发现并没有,无论哪种 scheduler,最终的结果都差不多(epoch = 300),这可能是我初始lr设置的太大(5e-4)的原因?
虽然我产生了修改学习率的想法,但我还想尝试一下另一种修改方式,因为我发现 CosineAnnealLR 参数中 T_max 指代的是半个周期的长度,而 CosineAnnealingWarmRestarts 参数中的 T_0 指代的是一个周期长度,我将二者都设置成了 10,这使得 CosineAnnealingWarmRestarts 在300个epoch中有30个周期,是 CosineAnnealLR 的两倍,我或许应该将 T_0 设置为 2*T_max 来进行最终的对比实验。

T_0 *= 2
学习率变化曲线

实验结果
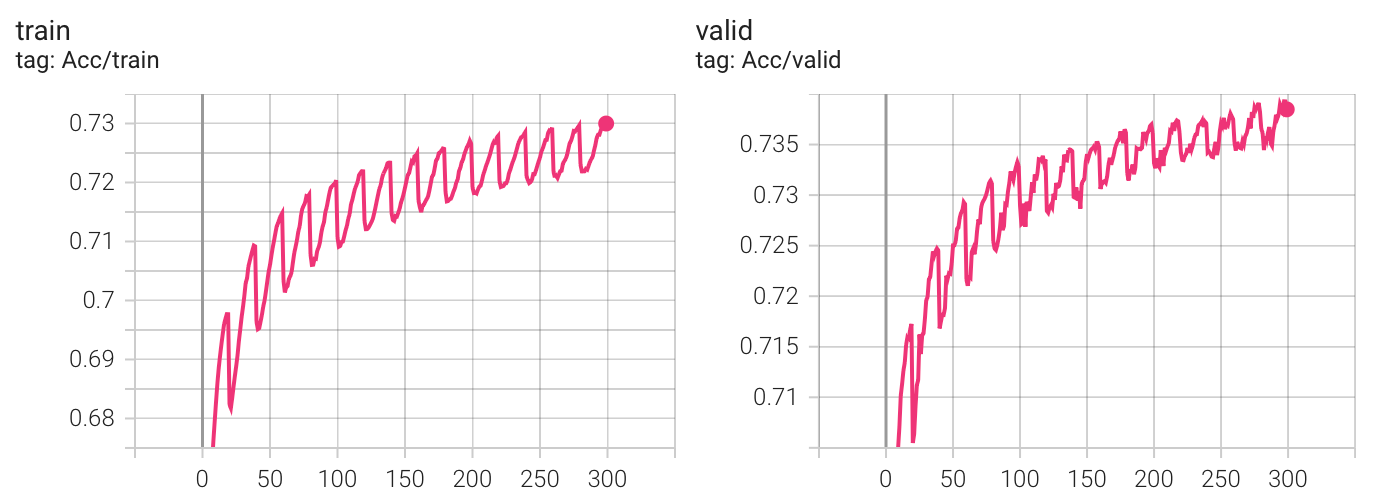
Kaggle 分数: 0.74403(没有提升)
看起来,各个 scheduler 最终的表现似乎没有区别?我决定跑一个没有scheduler的版本(是的,我一开始默认的觉得加上scheduler一定会让实验变得更好,但发现似乎并不是这样,最起码在当前的配置下不是(有可能是batchnorm的原因?))。
no scheduler
学习率变化曲线

实验结果
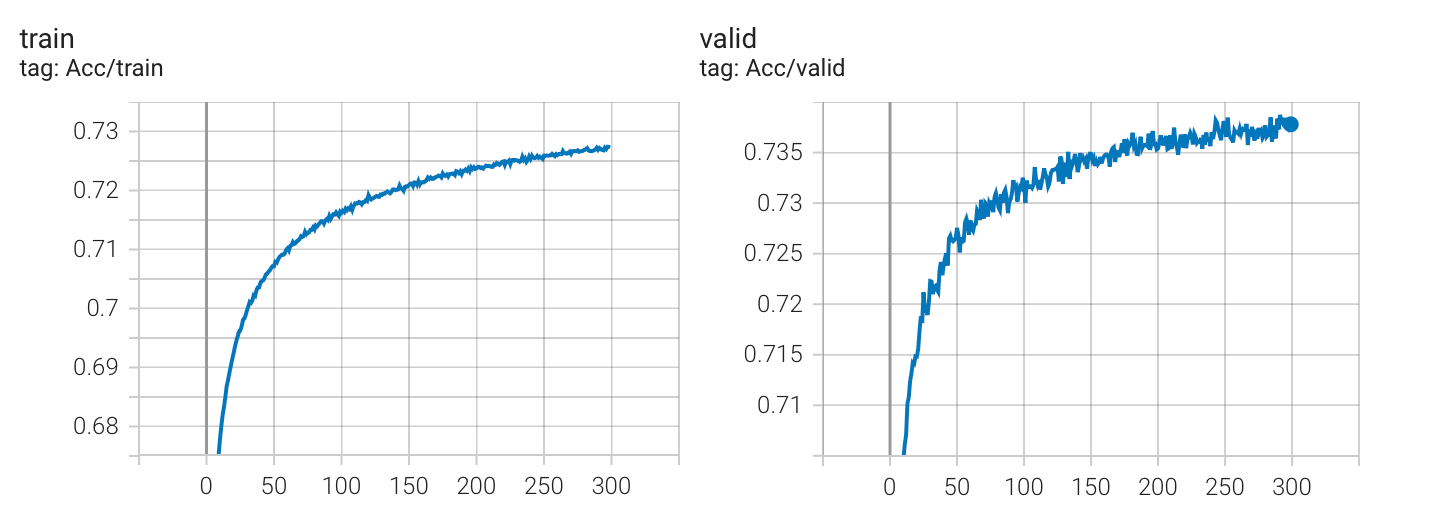
Kaggle 分数: 0.74408
实验结果对比
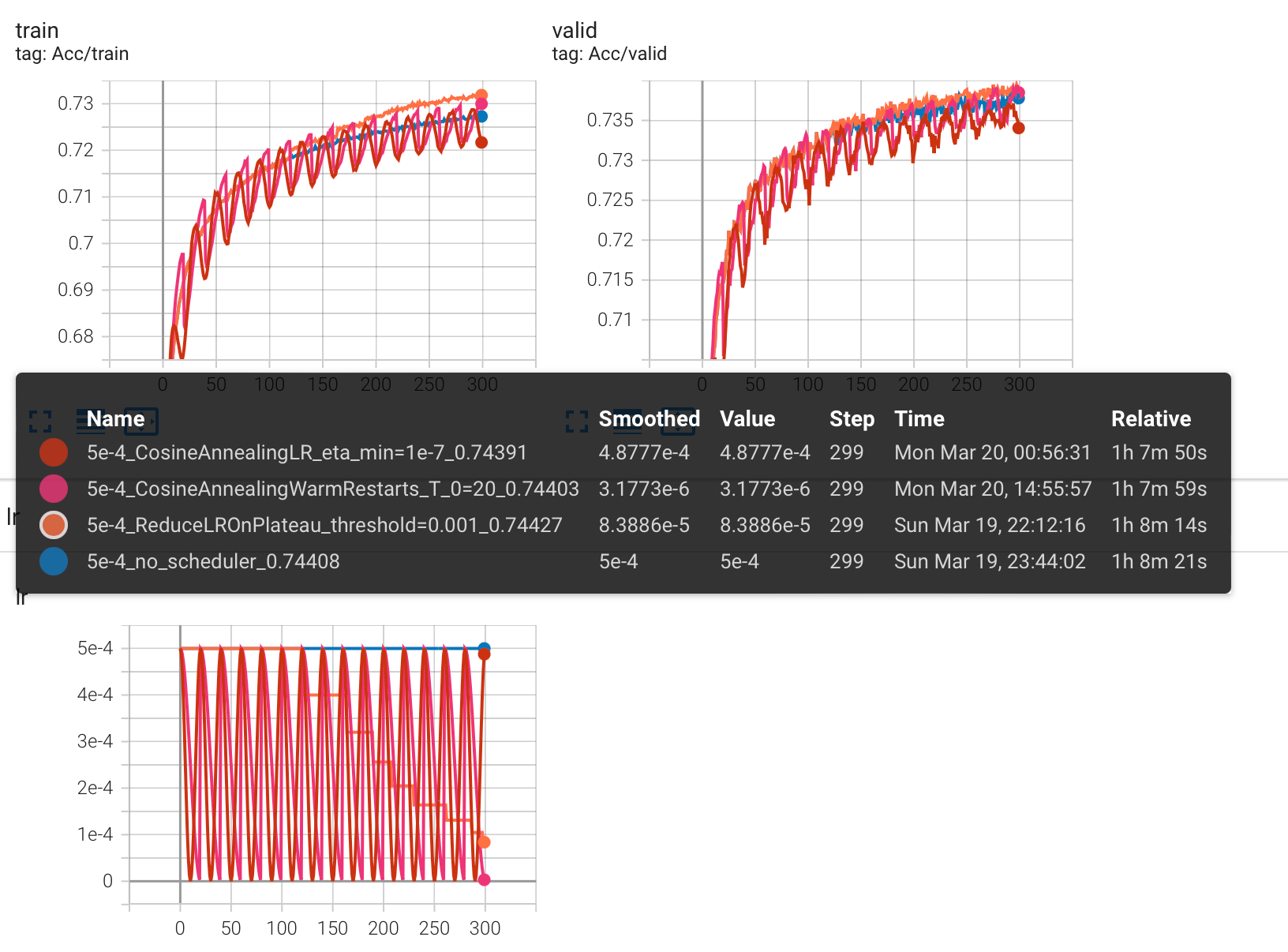
评价是:花里胡哨,没有区别(HW02 下)。真要用的话, ReduceLROnPlateau() 就够了,有时可以减少训练时间。
现在,我决定根据一个现象去改变 lr 的初始值:从输出中,观察到在所有周期中,每次 lr=2.5e-4 和 1.72e-4 的时候上升幅度最大,于是我将 lr 设置成 2.5e-4 重新跑了所有的实验。
修改 lr=2.5e-4,重新实验
实验结果对比
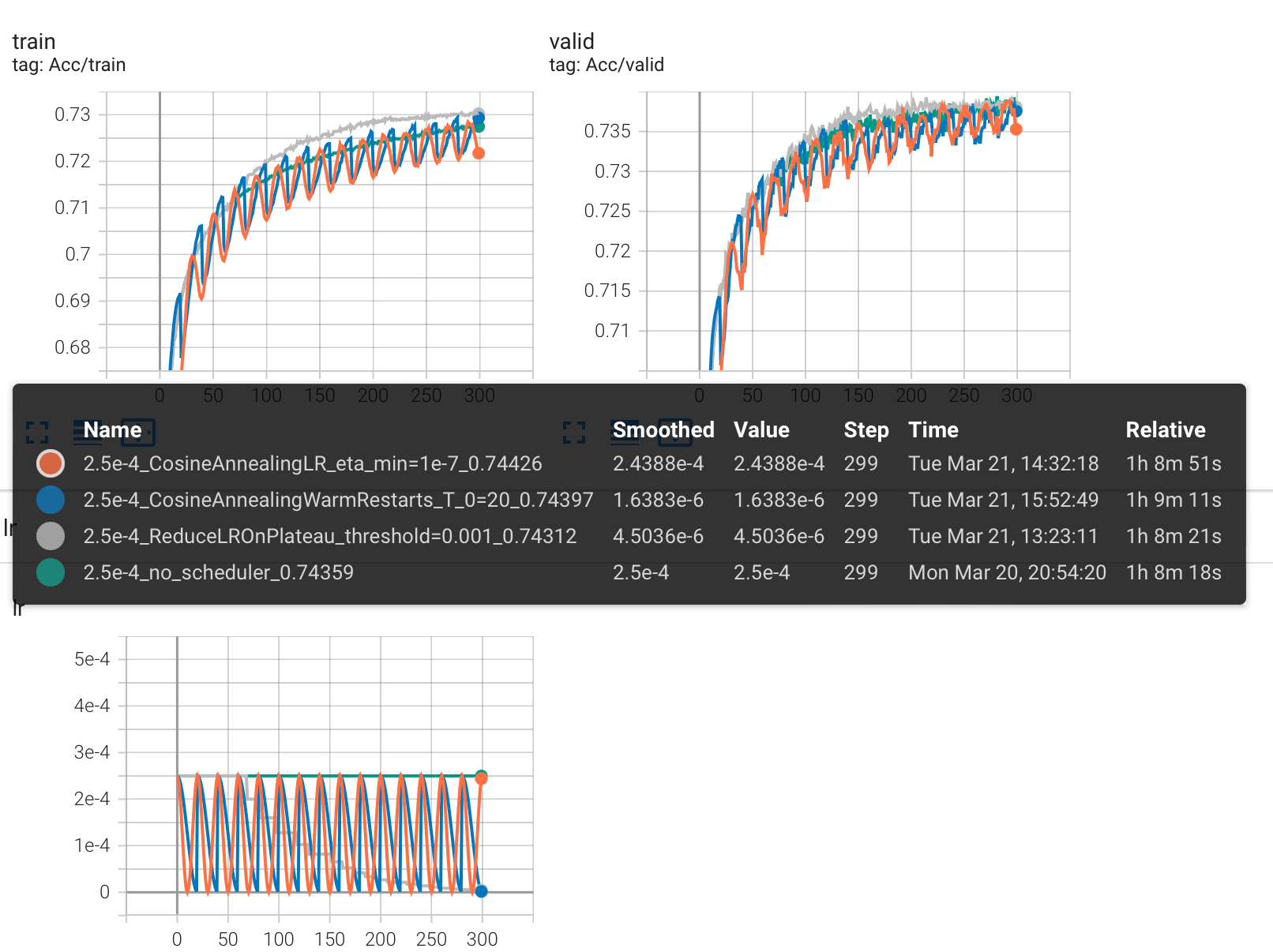
可以看到,Kaggle 分数没有提升。
下图是 lr = 5e-4 和 lr=2.5e-4 的 CosineAnnealingWarmRestarts 对比结果:
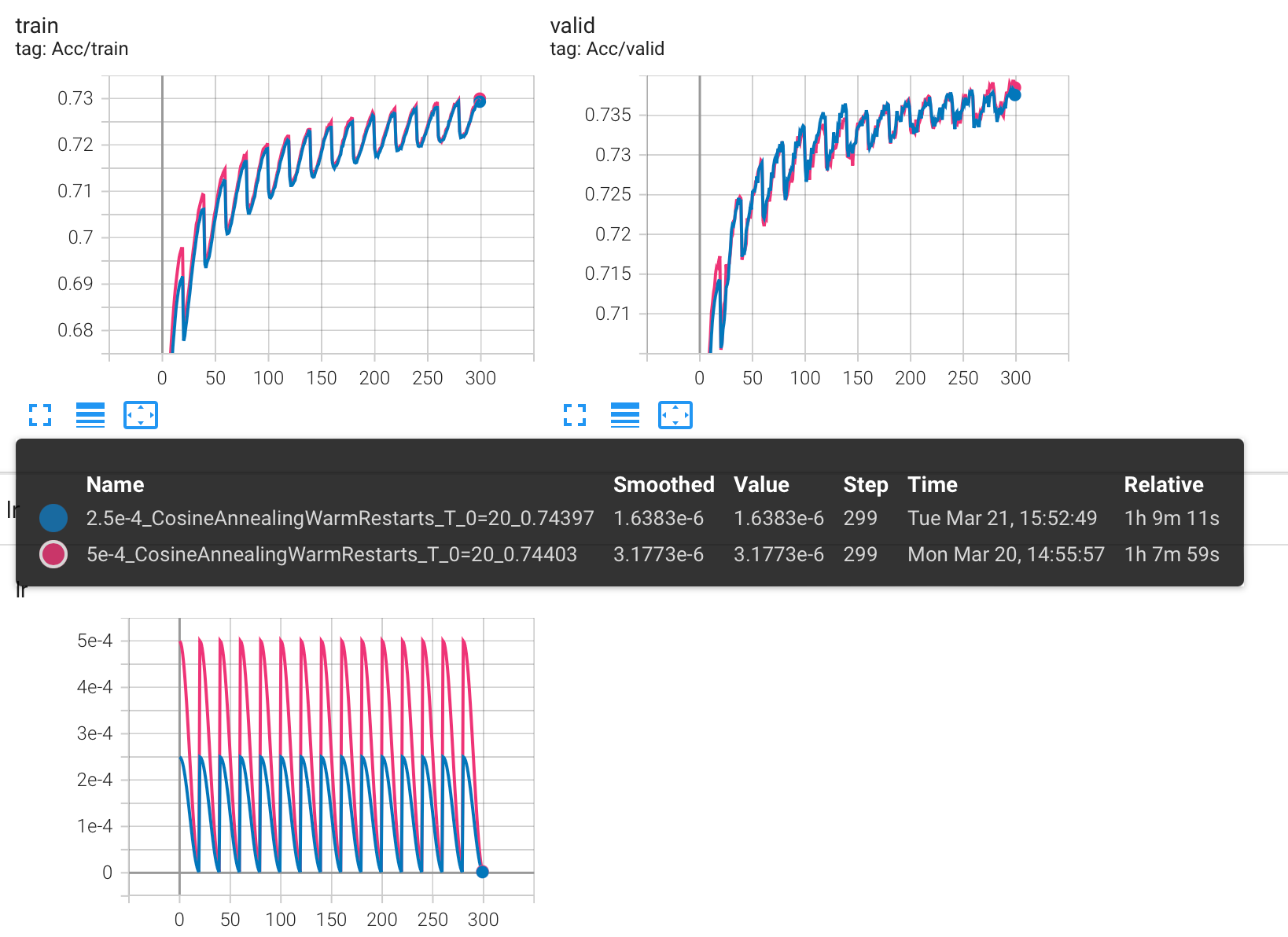
原以为会有很大的变化,比如在 lr 的最高点处 acc 不会降低这么多,发现并没有,甚至可以说是一模一样,这其中一定有什么我还不了解的东西在发挥作用。
总结
scheduler 真的没有作用吗?不尽然,这很大程度上取决于你现在的损失函数面和参数配置,使用 scheduler 往往可以更快的收敛。下图是对比:
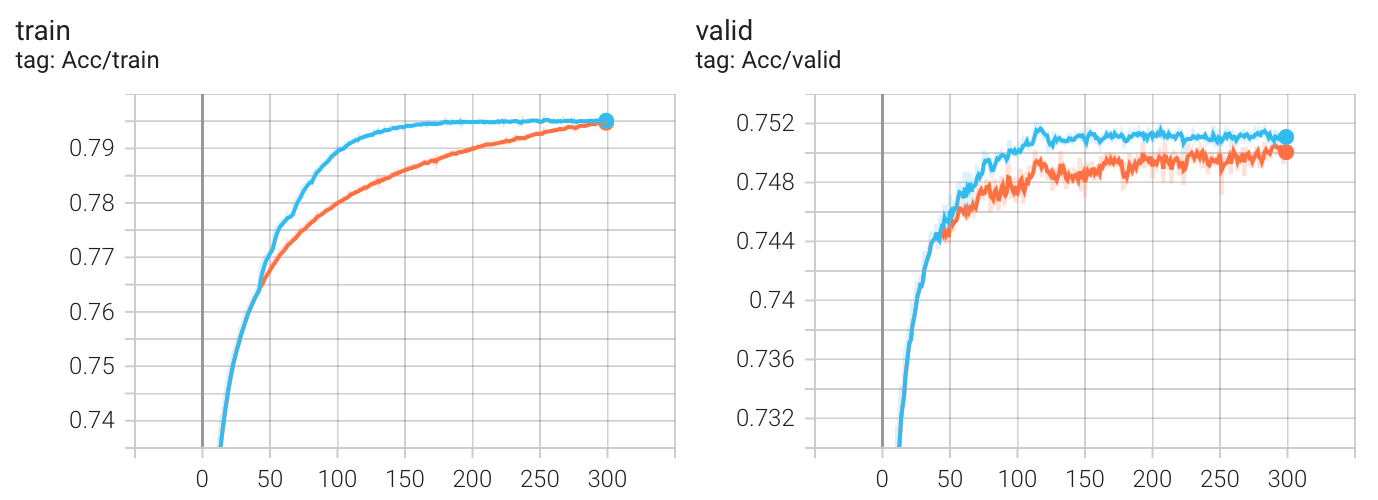
但相对于盲目的使用一些可能提高 metric 的函数,你更应该在预处理数据上下功夫:
- 跑完这个对比实验后,我增加了输入的维度,让数据在一开始拥有更多的信息(对应到 HW02 就是:将 concat_nframes 从 15 增加到了 21,使得在网络可以更多的考虑到相邻的音素),仅仅改变这一条,Kaggle 的分数便超过了 strong baseline,达到了 0.75623。
- 进一步的,dropout 其实不应设置成 25,通过观察可以发现:没有 dropout 的时候,训练集很容易便能达到 90+ 的准确率,当然,这是过拟合了。但 p=25 时,acc 一直上不去又何尝不是欠拟合呢?基于这个想法,我在 p=25/15 下做了对比,下图是大致的实验结果(使用了 ReduceLROnPlateau()):
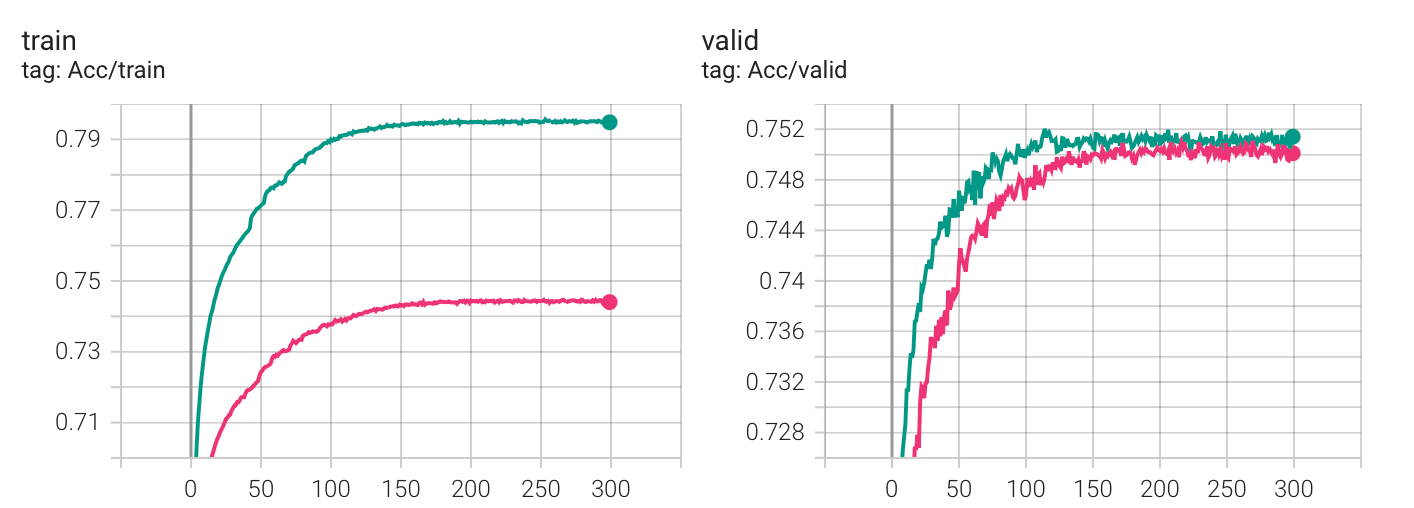
发现这使得 acc 比之前更快的抵达了 strong baseline,至于刚刚所想的欠拟合,好像没有体现出来 : )
P.S. epoch 设置成 300 完全是为了跑对比实验,做 HW 的时候不要设这么大,浪费时间。
实验局限在一个可能不好的参数配置,也局限在单独的 optimizer 之下,仅向大家展示片面的的结果 : )
以上是关于部分 scheduler 使用的实验对比和总结,希望对你有所帮助~