做文化建设的网站苏州优化收费
一、概论
1.1 什么是DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
1.2 DataX 的设计
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。
1.3 框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发给Framework。
- Wiriter: 数据写入模块,负责不断向Framwork取数据,并将数据写入到目的端。
- Framework:用于连接read和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
运行原理
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
1.4 Datax所支持的渠道
| 类型 | 数据源 | 读者 | 作家(写) | 文件 |
|---|---|---|---|---|
| RDBMS关系型数据库 | MySQL | √ | √ | 读,写 |
| 甲骨文 | √ | √ | 读,写 | |
| SQL服务器 | √ | √ | 读,写 | |
| PostgreSQL的 | √ | √ | 读,写 | |
| DRDS | √ | √ | 读,写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读,写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读,写 |
| 美国存托凭证 | √ | 写 | ||
| 开源软件 | √ | √ | 读,写 | |
| OCS | √ | √ | 读,写 | |
| NoSQL数据存储 | OTS | √ | √ | 读,写 |
| Hbase0.94 | √ | √ | 读,写 | |
| Hbase1.1 | √ | √ | 读,写 | |
| 凤凰4.x | √ | √ | 读,写 | |
| 凤凰5.x | √ | √ | 读,写 | |
| MongoDB | √ | √ | 读,写 | |
| 蜂巢 | √ | √ | 读,写 | |
| 卡桑德拉 | √ | √ | 读,写 | |
| 无结构化数据存储 | 文本文件 | √ | √ | 读,写 |
| 的FTP | √ | √ | 读,写 | |
| HDFS | √ | √ | 读,写 | |
| 弹性搜索 | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| 技术开发局 | √ | √ | 读,写 |
二、快速入门
2.1 环境搭建
下载地址: http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址: https://github.com/alibaba/DataX
配置要求:
- Linux
- JDK(1.8以上 建议1.8) 下载
- Python(推荐 Python2.6.X)下载
安装:
1) 将下载好的datax.tar.gz上传到服务器的任意节点,我这里上传到node01上的/exprot/soft
2)解压到/export/servers/
[root@node01 soft]# tar -zxvf datax.tar.gz -C ../servers/3)运行自检脚本
出现以下结果说明你得环境没有问题
[/opt/module/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.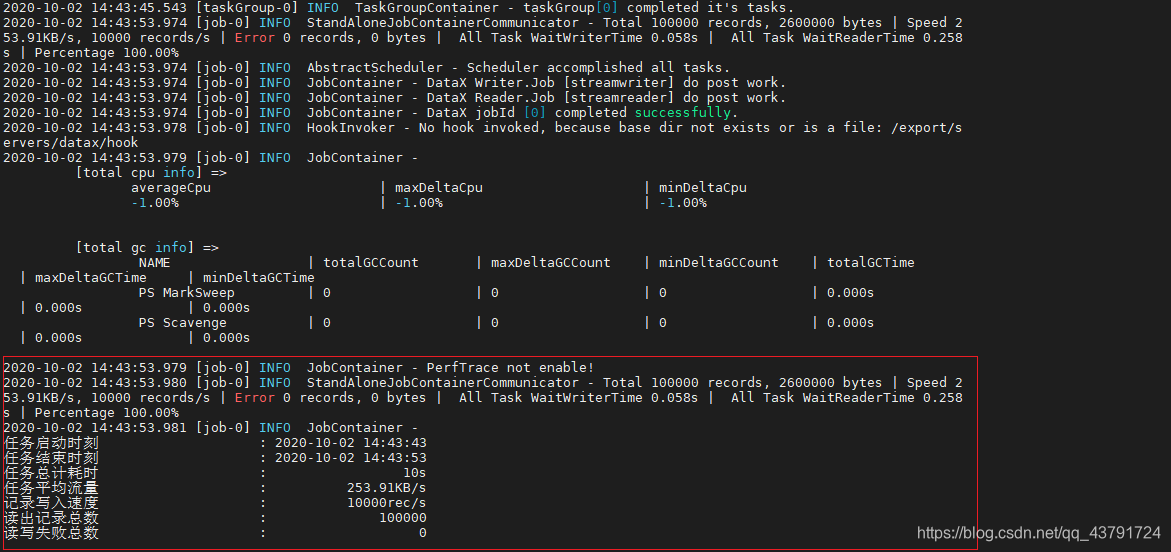
2.2搭建环境注意事项
[/opt/module/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.
参考:
find ./* -type f -name ".*er" | xargs rm -rf
find: paths must precede expression: |
Usage: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]find /datax/plugin/reader/ -type f -name "._*er" | xargs rm -rf
find /datax/plugin/writer/ -type f -name "._*er" | xargs rm -rf这里的/datax/plugin/writer/要改为你自己的目录
原文链接:https://blog.csdn.net/dz77dz/article/details/127055299
2.3读取Mysql中的数据写入到HDFS
准备
创建数据库和表并加载测试数据
create database test;
use test;
create table c_s(id varchar(100) null,c_id int null,s_id varchar(20) null
);
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 1, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 2, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 3, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 5, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 6, '201967');查看官方提供的模板
[root@node01 datax]# bin/datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.mdPlease refer to the hdfswriter document:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [],"connection": [{"jdbcUrl": [],"table": []}],"password": "","username": "","where": ""}},"writer": {"name": "hdfswriter","parameter": {"column": [],"compress": "","defaultFS": "","fieldDelimiter": "","fileName": "","fileType": "","path": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}
}根据官网模板进行修改
[root@node01 datax]# vim job/mysqlToHDFS.json
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","c_id","s_id"],"connection": [{"jdbcUrl": ["jdbc:mysql://node02:3306/test"],"table": ["c_s"]}],"password": "123456","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "string"},{"name": "c_id","type": "int"},{"name": "s_id","type": "string"}],"defaultFS": "hdfs://node01:8020","fieldDelimiter": "\t","fileName": "c_s.txt","fileType": "text","path": "/","writeMode": "append"}}}],"setting": {"speed": {"channel": "1"}}}
}
HDFS的端口号注意版本,2.7.4 是9000;hdfs://node01:9000
MySQL的参数介绍
HDFS参数介绍
运行脚本
[root@node01 datax]# bin/datax.py job/mysqlToHDFS.json
2020-10-02 16:12:16.358 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /export/servers/datax/hook
2020-10-02 16:12:16.359 [job-0] INFO JobContainer -[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 1 | 1 | 1 | 0.245s | 0.245s | 0.245sPS Scavenge | 1 | 1 | 1 | 0.155s | 0.155s | 0.155s2020-10-02 16:12:16.359 [job-0] INFO JobContainer - PerfTrace not enable!
2020-10-02 16:12:16.359 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 50 bytes | Speed 5B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2020-10-02 16:12:16.360 [job-0] INFO JobContainer -
任务启动时刻 : 2020-10-02 16:12:04
任务结束时刻 : 2020-10-02 16:12:16
任务总计耗时 : 12s
任务平均流量 : 5B/s
记录写入速度 : 0rec/s
读出记录总数 : 5
读写失败总数 : 02.4 读取HDFS中的数据写入到Mysql
准备工作
create database test;
use test;
create table c_s2(id varchar(100) null,c_id int null,s_id varchar(20) null
);
查看官方提供的模板
[root@node01 datax]# bin/datax.py -r hdfsreader -w mysqlwriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the hdfsreader document:https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.mdPlease refer to the mysqlwriter document:https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"column": [],"defaultFS": "","encoding": "UTF-8","fieldDelimiter": ",","fileType": "orc","path": ""}},"writer": {"name": "mysqlwriter","parameter": {"column": [],"connection": [{"jdbcUrl": "","table": []}],"password": "","preSql": [],"session": [],"username": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}
}根据官方提供模板进行修改
[root@node01 datax]# vim job/hdfsTomysql.json
{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"column": ["*"],"defaultFS": "hdfs://node01:8020","encoding": "UTF-8","fieldDelimiter": "\t","fileType": "text","path": "/c_s.txt"}},"writer": {"name": "mysqlwriter","parameter": {"column": ["id","c_id","s_id"],"connection": [{"jdbcUrl": "jdbc:mysql://node02:3306/test","table": ["c_s2"]}],"password": "123456","username": "root","writeMode": "replace"}}}],"setting": {"speed": {"channel": "1"}}}
}
脚本运行
[root@node01 datax]# bin/datax.py job/hdfsTomysql.json[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 1 | 1 | 1 | 0.026s | 0.026s | 0.026sPS Scavenge | 1 | 1 | 1 | 0.015s | 0.015s | 0.015s2020-10-02 16:57:13.152 [job-0] INFO JobContainer - PerfTrace not enable!
2020-10-02 16:57:13.152 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 50 bytes | Speed 5B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.033s | Percentage 100.00%
2020-10-02 16:57:13.153 [job-0] INFO JobContainer -
任务启动时刻 : 2020-10-02 16:57:02
任务结束时刻 : 2020-10-02 16:57:13
任务总计耗时 : 11s
任务平均流量 : 5B/s
记录写入速度 : 0rec/s
读出记录总数 : 5
读写失败总数 : 0
2.5将Mysql表导入Hive
1.在hive中建表
-- hive建表
CREATE TABLE student2 (classNo string,stuNo string,score int)
row format delimited fields terminated by ',';-- 构造点mysql数据
create table if not exists student2(classNo varchar ( 50 ),stuNo varchar ( 50 ),score int
)
insert into student2 values('1001','1012ww10087',63);
insert into student2 values('1002','1012aa10087',63);
insert into student2 values('1003','1012bb10087',63);
insert into student2 values('1004','1012cc10087',63);
insert into student2 values('1005','1012dd10087',63);
insert into student2 values('1006','1012ee10087',63);2.编写mysql2hive.json配置文件
{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","connection": [{"table": ["student2"],"jdbcUrl": ["jdbc:mysql://192.168.43.10:3306/mytestmysql"]}],"column": ["classNo","stuNo","score"]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://192.168.43.10:9000","path": "/hive/warehouse/home/myhive.db/student2","fileName": "myhive","writeMode": "append","fieldDelimiter": ",","fileType": "text","column": [{"name": "classNo","type": "string"},{"name": "stuNo","type": "string"},{"name": "score","type": "int"}]}}}]}
}3.运行脚本
bin/datax.py job/mysql2hive.json 4.查看hive表是否有数据

2.6将Hive表数据导入Mysql
1.要先在mysql建好表
create table if not exists student(classNo varchar ( 50 ),stuNo varchar ( 50 ),score int
)2.hive2mysql.json配置文件
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/hive/warehouse/home/myhive.db/student/*","defaultFS": "hdfs://192.168.43.10:9000","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "Long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "root","column": ["classNo","stuNo","score"],"preSql": ["delete from student"],"connection": [{"jdbcUrl": "jdbc:mysql://192.168.43.10:3306/mytestmysql?useUnicode=true&characterEncoding=utf8","table": ["student"]}]}}}]}
}
注意事项:
在Hive的ODS层建表语句中,以“,”为分隔符;
fields terminated by ','
在DataX的json文件中,也以“,”为分隔符。
"fieldDelimiter": "," 与hive表里面的分隔符保持一致即可
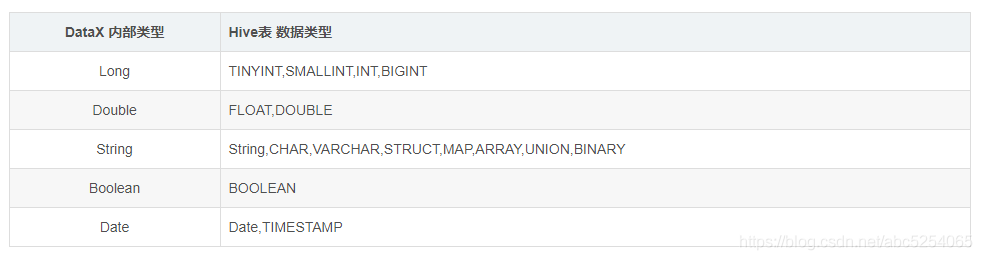
由于DataX不能完全支持所有Hive表的数据类型,应将DataX启动文件中的hdfsreader中的column字段的类型改成DataX支持的类型