网站建设要咨询哪些内容桂平seo快速优化软件
问题呈现
这是我在问答区看到的一个问题。
问:在python中使用pandas读取Excel数据,重复数据被区分了,如何做到重复数据不被区分?


解决思路
很明显,这是pandas读取excel文件时列名设置问题,我第一时间想到的就是pandas.read_excel()是否能读取多行为列名
在pandas.read_excel()里有这样一个参数header,官方文档中这样描述:

header:默认为0,接受整数和整数列表。
按照下标(第一行下标为0)读取为列名。如果传入整数列表,就将根据下标为这些整数的行生成多层索引。header=None表示没有列名。
解决方法已经呼之欲出了。
解决方法
参数header=[0, 1],将前两行作为多层索引
df.loc[:, ‘M1’].loc[:, ‘V1’],读取某列时逐层选定
测试数据如下:
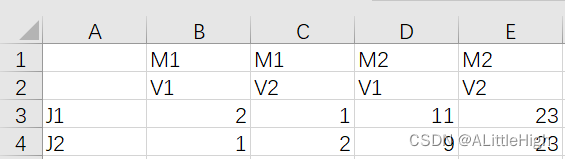
代码实现
import pandas as pddf = pd.read_excel(r"test.xlsx", header=[0, 1]) # header=[0, 1]表示根据第1和第二行值生成多层索引,这里为两层print('读取的列名有两层。第一层中有M1和M2两个列名,第二层中分别包含了V1和V2')
print(df)M1V1 = df.loc[:, 'M1'].loc[:, 'V1']print('读取时要逐次选定列名,比如要读取列名为M1下的V1列。先选定列名为M1,然后再选定列名为V1')
print(M1V1)
运行效果
读取的列名有两层。第一层中有M1和M2两个列名,第二层中分别包含了V1和V2Unnamed: 0_level_0 M1 M2 Unnamed: 0_level_1 V1 V2 V1 V2
0 J1 2 1 11 23
1 J2 1 2 9 23
读取时要逐次选定列名,比如要读取列名为M1下的V1列。先选定列名为M1,然后再选定列名为V1
0 2
1 1
Name: V1, dtype: int64
完美解决,对你有帮助的话记得收藏哦~