oa系统服务器地址在哪里看网站seo课设
前言:
在计算机科学中,数组和链表是两种常见的数据结构,用于存储和组织数据。它们分别具有不同的特点和适用场景。
本博客将深入讨论数组和链表在OJ题目中的应用。我们将从基本概念开始,介绍数组和链表的定义和特点,并分析它们在不同场景下的优势和劣势。
接下来,我们将探讨数组在OJ题目中的常见应用。我们将介绍如何原地移除数组中所有的val元素,如何删除排序数组中的重复项,以及如何合并两个有序数组。
随后,我们将探讨链表在OJ题目中的常见应用。我们将介绍如何删除链表中值为val的所有节点,如何翻转单链表,如何返回链表的中间结点和倒数第k个结点,以及如何合并两个有序链表等。
此外,我们还将介绍一些更复杂的链表问题,如链表的分割、回文链表、相交链表、带环链表等。我们将详细讲解每个问题的解题思路和实现方法。
最后,我们将讨论带有随机指针的链表,介绍如何复制这种特殊的链表结构,并解决相关问题。
通过对这些数组和链表的OJ题目的探讨,我们将加深对数组和链表的理解,并学会在实际问题中灵活运用它们。希望本博客能帮助读者更好地掌握这两种数据结构,并提升解题能力。让我们开始吧!
个人主页:Oldinjuly的个人主页
收录专栏:数据结构
欢迎各位点赞👍收藏⭐关注❤️

目录
🌹一、数组
💐1.原地移除数组中所有的val元
💐2.删除排序数组中的重复项
💐3.合并两个有序数组
🌹二、链表
💐1.删除链表中值为val的所有节点
💐2.翻转单链表
💐3.返回中间结点
💐4.返回倒数第k个结点
💐6.链表分割
💐 7.回文链表
💐8.相交链表
💐9.带环链表Ⅰ
💐10.带环链表Ⅱ
💐11.复制带随机指针的链表
🌹一、数组
💐1.原地移除数组中所有的val元素


方法一:暴力删除,挪动数据覆盖: 时间复杂度O(N^2), 空间复杂度O(1)
方法二:开辟新空间tmp,设置两个“指针”dst和src,nums[src]不等于val的直接插入到tmp[dst]中,等于val的直接跳过,然后tmp拷贝到nums中。
int removeElement(int* nums, int numsSize, int val)
{int* tmp = (int*)malloc(sizeof(int)*numsSize);int dst=0,src=0;while(src<numsSize){if(nums[src]!=val){tmp[dst++]=nums[src++];}else{src++;}}memcpy(nums,tmp,sizeof(int)*dst);return dst;
}
方法三:双指针在原数组上直接覆盖
nums[src]不等于val,直接覆盖尾插到dst位置,++dst,++src。
nums[src]等于val,直接++src,相当于删除。

int removeElement(int* nums, int numsSize, int val)
{int dst=0,src=0;while(src < numsSize){if(nums[src] != val){nums[dst++] = nums[src++];}else{src++;}}return dst;
}
💐2.删除排序数组中的重复项


双指针dst和src:
dst和src如果相等,src++。
dst和src如果不相等,dst先++,然后src覆盖到dst上,src再++。

int removeDuplicates(int* nums, int numsSize)
{int dst=0, src=0;while(src<numsSize){if(nums[dst]==nums[src]){src++;}else{nums[++dst]=nums[src++];}}return ++dst;
}💐3.合并两个有序数组
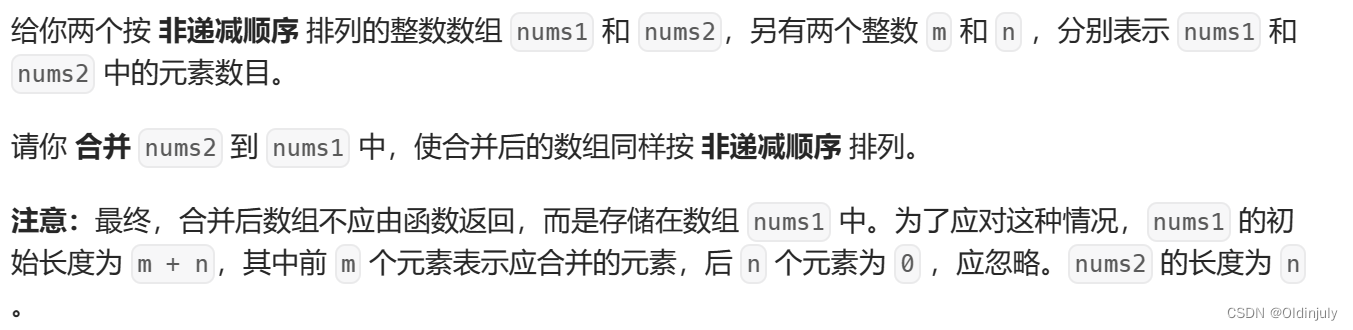

1.从前往后归并,需要开新空间
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int* tmp = (int*)malloc(sizeof(int)*(m+n));int begin1=0, begin2=0, pos=0;while(begin1 < m && begin2 < n){if(nums1[begin1] < nums2[begin2]){tmp[pos++]=nums1[begin1++];}else{tmp[pos++]=nums2[begin2++];}}while(begin1 < m){tmp[pos++]=nums1[begin1++];}while(begin2 < n){tmp[pos++]=nums2[begin2++];}memcpy(nums1,tmp,sizeof(int)*(m+n));free(tmp);
}
2.从后往前归并,不需要开新空间
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int end1=m-1,end2=n-1,end=m+n-1;while(end1>=0&&end2>=0){if(nums1[end1]>nums2[end2]){nums1[end--]=nums1[end1--];}else{nums1[end--]=nums2[end2--];}}while(end2>=0){nums1[end--]=nums2[end2--];}
}
🌹二、链表
💐1.删除链表中值为val的所有节点
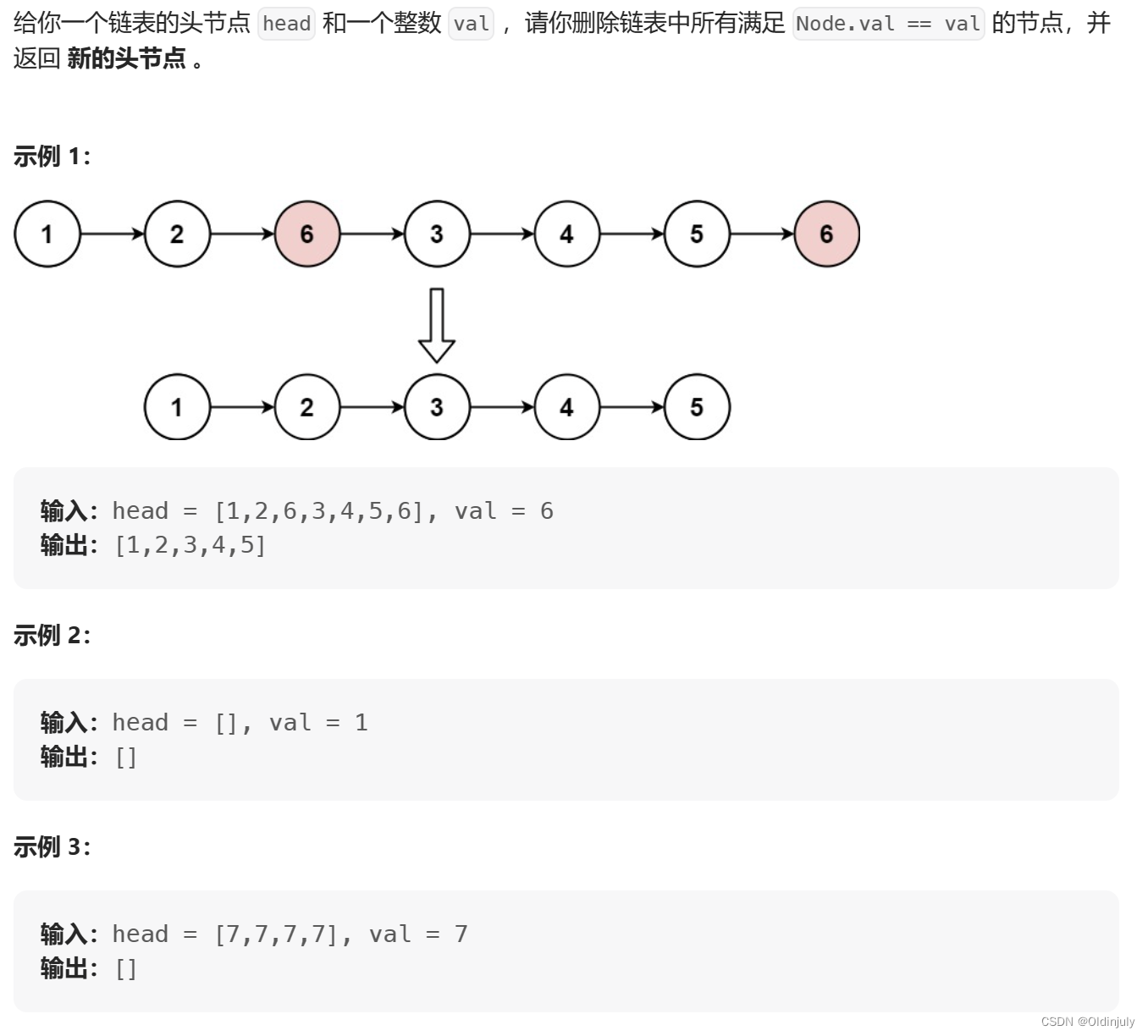
解法一:在原链表上进行操作
struct ListNode* removeElements(struct ListNode* head, int val)
{struct ListNode* cur = head;struct ListNode* prev = NULL;while(cur){if(cur->val == val){if(cur == head){head = cur->next;free(cur);cur = head;}else{prev->next = cur->next;free(cur);cur = prev->next;}}else{prev = cur;cur = cur->next;}}return head;
}
注意:头删不需要prev节点,是要单独讨论的。
解法二:创建一个新链表
struct ListNode* removeElements(struct ListNode* head, int val)
{struct ListNode* newhead = NULL, *tail = NULL, *cur = head;while(cur){if(cur->val == val){struct ListNode* next = cur->next;free(cur);cur = next; }else {if(newhead == NULL){newhead = cur;tail = cur;}else{tail->next = cur;tail = tail->next;}cur = cur->next;}}if(tail){tail->next = NULL;}return newhead;
}
注意:
- 逻辑上的一个新链表,但是内存没有额外开辟空间。
- 避免每次重复找尾结点,设置一个tail指针变量来记录。
- 最后要给tail的next置空。
💐2.翻转单链表
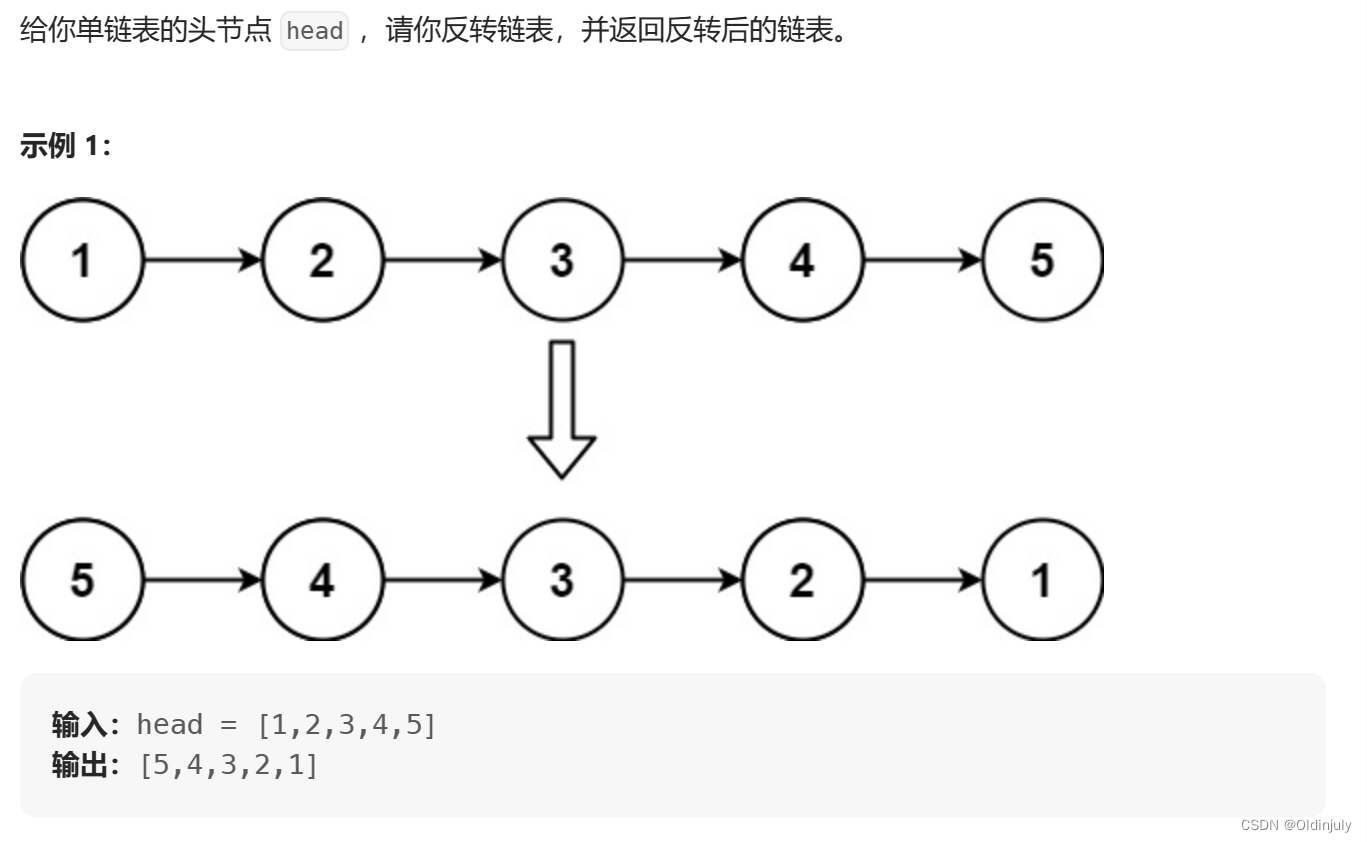

解法一:三指针链接法
struct ListNode* reverseList(struct ListNode* head)
{struct ListNode *n1, *n2, *n3;n1 = NULL;n2 = head;if(head)n3 = head->next;while(n2){n2->next = n1;n1 = n2;n2 = n3;if(n3)n3 = n3->next;} return n1;
}
问题:为什么设置三个指针变量进行迭代?
如果只设置两个指针变量进行迭代,n1赋值n2的next域之后,n2就无法迭代带原本的next域,而三个指针变量可以解决这个问题。
注意:n3进行迭代之前要判断n3是否为NULL。
解法二:头插法
struct ListNode* reverseList(struct ListNode* head)
{struct ListNode* newhead = NULL;struct ListNode* cur = head;while(cur){struct ListNode* next = cur->next;cur->next = newhead;newhead = cur;cur = next;}return newhead;
}
💐3.返回中间结点
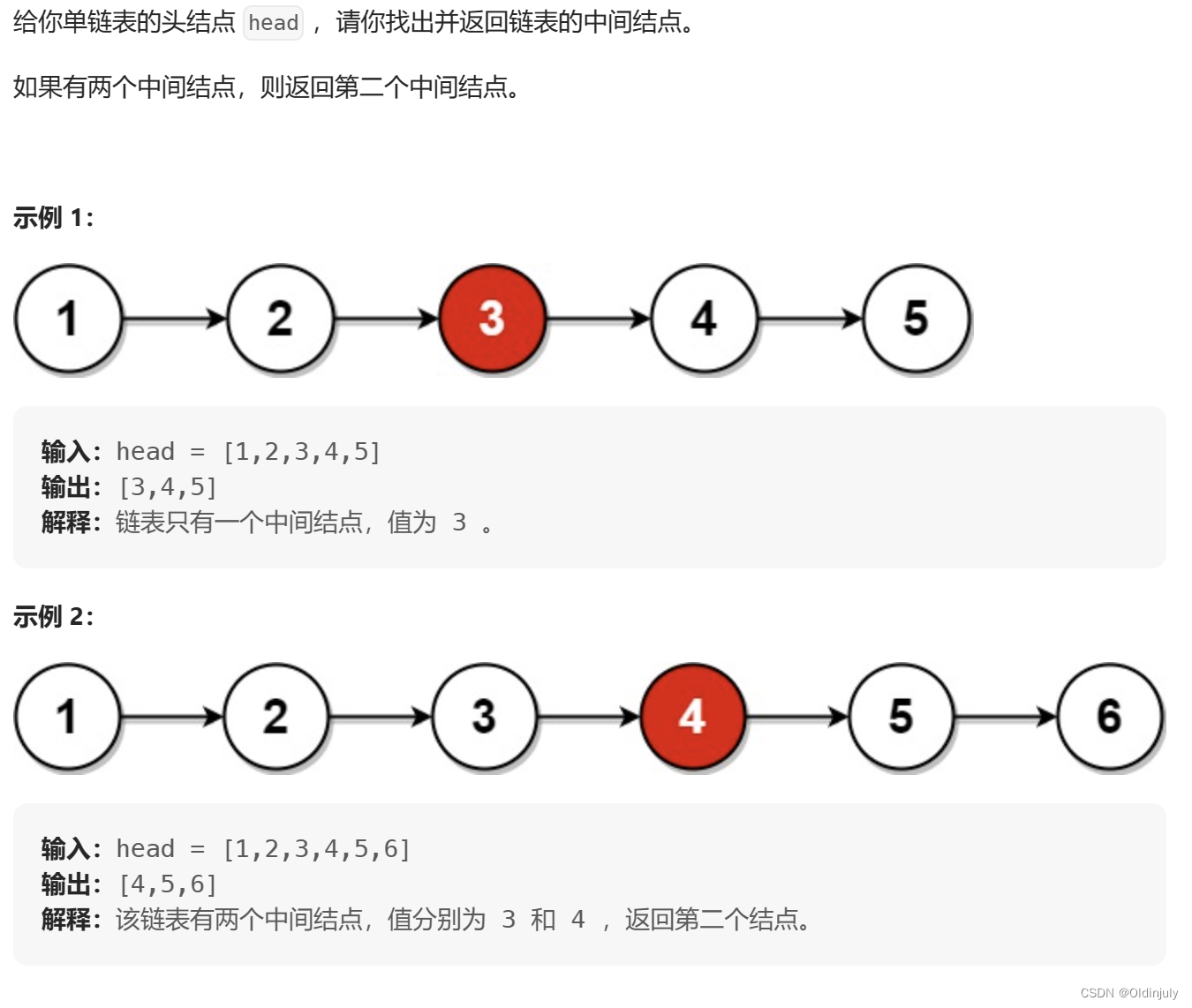
双指针(快慢指针):fast指针走两步,slow指针走一步
奇数个链表节点:fast == NULL,slow对应中间结点
偶数个链表结点:fast->next == NULL,slow对应中间节点
struct ListNode* middleNode(struct ListNode* head)
{struct ListNode *slow = head, *fast = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;}return slow;
}
💐4.返回倒数第k个结点

双指针:
fast指针先走k步,然后两个指针一起走,fast走到NULL,slow走到目标节点。
fast指针先走k-1步,然后两个指针一起走,fast走到尾结点,slow走到目标节点。
struct ListNode* getKthFromEnd(struct ListNode* head, int k)
{struct ListNode *fast = head, *slow = head;int i = 0;for(i=0;i<k;i++) {//链表没有k步长,那么倒数就是空if(!fast)return NULL;fast = fast->next;}/*while(k--)//k--走k步,--k走k-1步{if(!fast)return NULL;fast = fast->next;}*/while(fast){fast = fast->next;slow = slow->next;}return slow;
}
💐5.合并两个有序链表
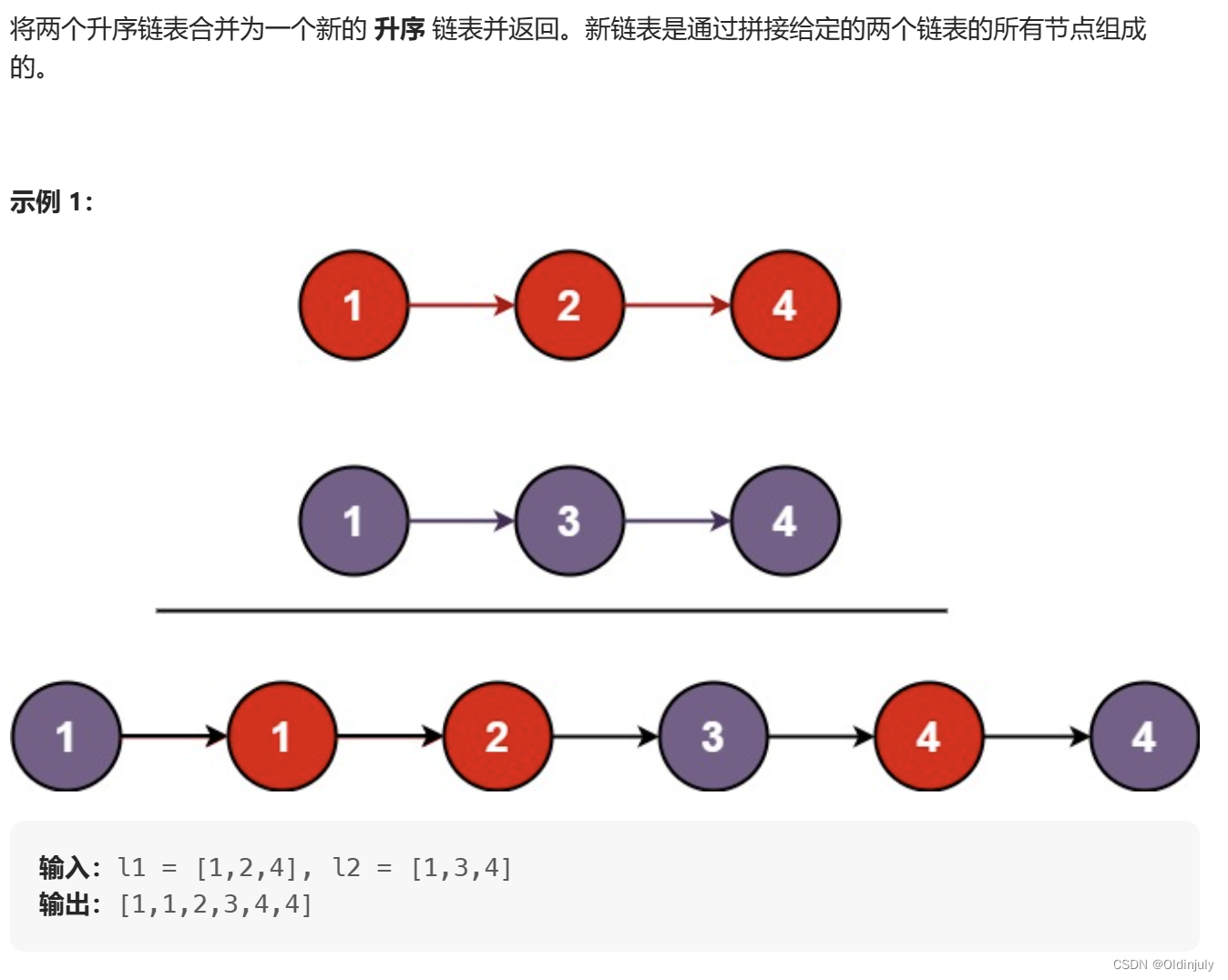

struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{struct ListNode *head = NULL, *tail = NULL;if(!list1)return list2;if(!list2)return list1;while(list1 && list2){if(list1->val < list2->val){if(head == NULL){head = list1;tail = list1;}else{tail->next = list1;tail= tail->next;}list1 = list1->next;}else{if(head == NULL){head = list2;tail = list2;}else{tail->next = list2;tail= tail->next;}list2 = list2->next;}}if(list1){tail->next = list1;}if(list2){tail->next = list2; }return head;
}
注意:
- while循环的条件是list1&&list2,循环里面是继续条件,但是我们心中想的是循环终止条件,也就是有一个链表结束循环也就结束。
- 当循环结束后,只需要把 没有遍历到空的链表尾接到tail后面即可。
这题合并有序链表和合并有序数组都使用了一个关键思想:归并,这也是排序算法的一个重要思想。
代码优化:
这里的归并使用了尾插,不带头结点单链表的尾插有一个缺点,就是第一次插入不需要找tail,直接赋值给head即可,需要单独讨论;为了使代码简洁,此时就需要另一种链表:带头结点(哨兵位)的单链表。
头结点什么数据也不存储,那么这个头结点有什么意义呢?
- 尾插尾删不需要单独讨论,形成统一化。
- 不需要传二级指针了,改的是头结点的next,修改结构体,直接传结构体指针即可。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{if(!list1)return list2;if(!list2)return list1;struct ListNode* head = (struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* tail = head;while(list1 && list2){if(list1->val < list2->val){tail->next = list1;tail = tail->next;list1 = list1->next;}else{tail->next = list2;tail = tail->next;list2 = list2->next;}}if(list1)tail->next = list1;if(list2)tail->next = list2;struct ListNode* next = head->next;free(head);head = next;return head;
}
💐6.链表分割

class Partition {
public:ListNode* partition(ListNode* pHead, int x) {ListNode *lHead, *lTail, *gHead, *gTail;lHead = lTail = (ListNode*)malloc(sizeof(ListNode));gHead = gTail = (ListNode*)malloc(sizeof(ListNode));ListNode* cur = pHead;while(cur){if(cur->val < x){lTail->next = cur;lTail = lTail->next;}else{gTail->next = cur;gTail = gTail->next;}cur = cur->next;}lTail->next = gHead->next;//不置空,可能会出现环gTail->next = NULL;ListNode* next = lHead->next;free(lHead);free(gHead); return next; }
};注意:
- 该题开辟了两个链表头结点:lessHead,greaterHead,lessHead存放比x小的节点,greaterHead存放大于等于x的节点。
- 这题最好使用带头结点的单链表,原因:如果不带头结点,lessHead为空或者greaterHead为NULL的话,此时链接两个链表lTail->next = gHead->next这句代码就会出错。
- greaterTail的next的要置空,否则会出现环。
💐 7.回文链表

思路:
对于链表1->2->3->2->1->NULL;想判断是否回文,可以先将链表后半部分3->2->1->NULL进行逆置变成1->2->3->NULL;然后前半部分和后半部分进行比较,全部相等就是回文链表。
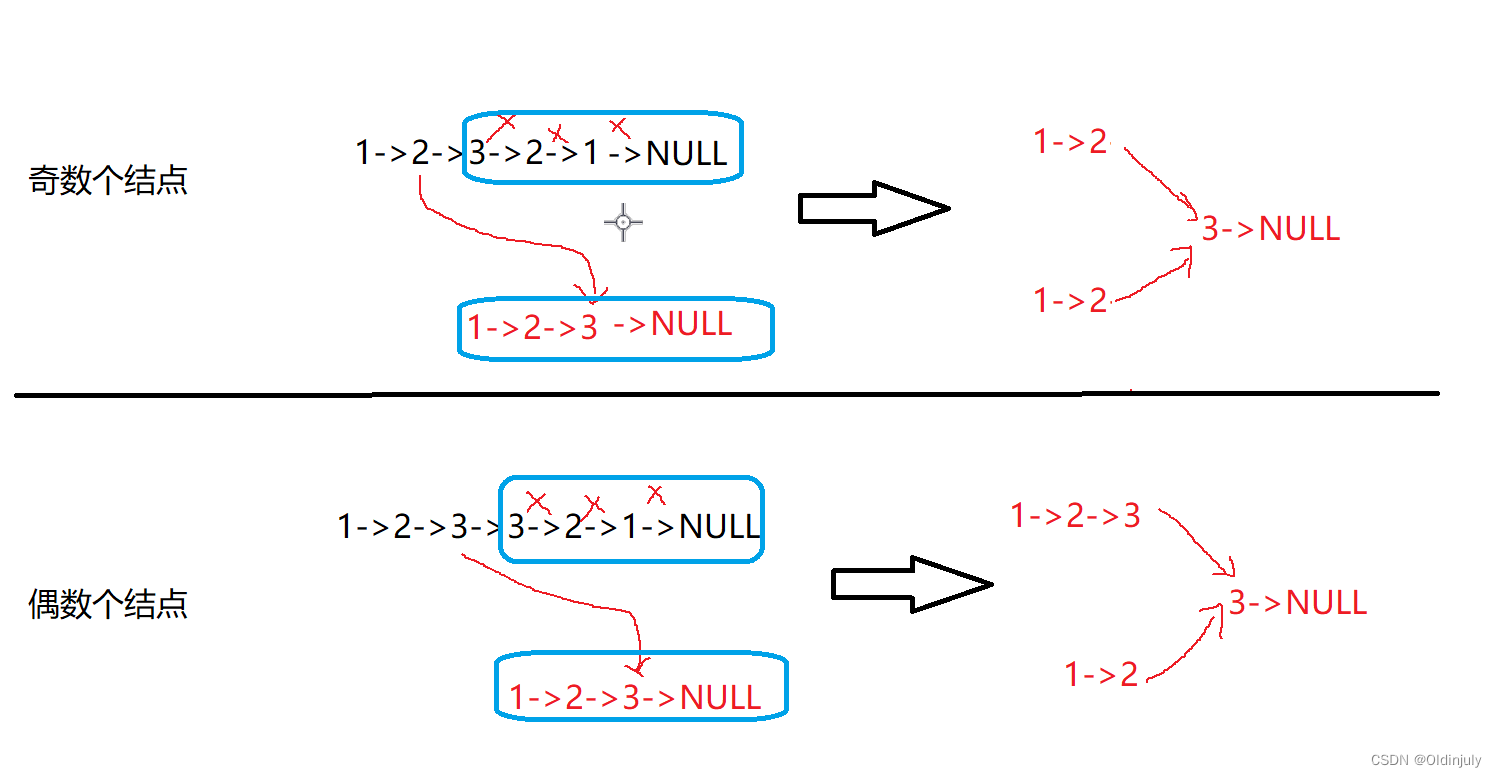
这里要复用之前的两个题目的函数:返回中间节点和翻转单链表。
struct ListNode* middleNode(struct ListNode* head)
{struct ListNode *slow = head, *fast = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;}return slow;
}struct ListNode* reverseList(struct ListNode* head)
{struct ListNode* newhead = NULL;struct ListNode* cur = head;while(cur){struct ListNode* next = cur->next;cur->next = newhead;newhead = cur;cur = next;}return newhead;
}bool isPalindrome(struct ListNode* head)
{struct ListNode* headA = head;struct ListNode* headB = middleNode(head);struct ListNode* curA = headA;struct ListNode* curB = reverseList(headB);;while(curA && curB){if(curA->val != curB->val)return false;curA = curA->next;curB = curB->next;}return true;
}
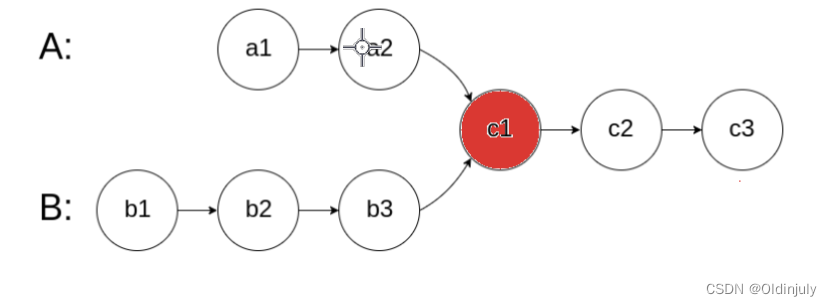
💐8.相交链表
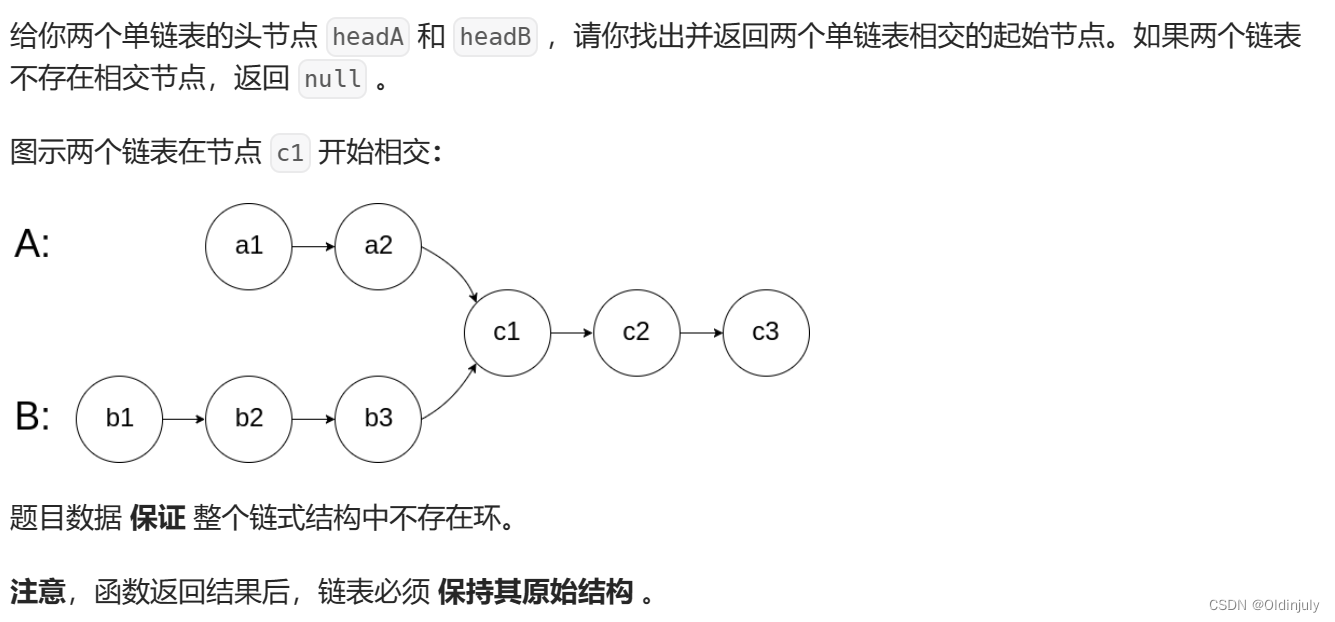
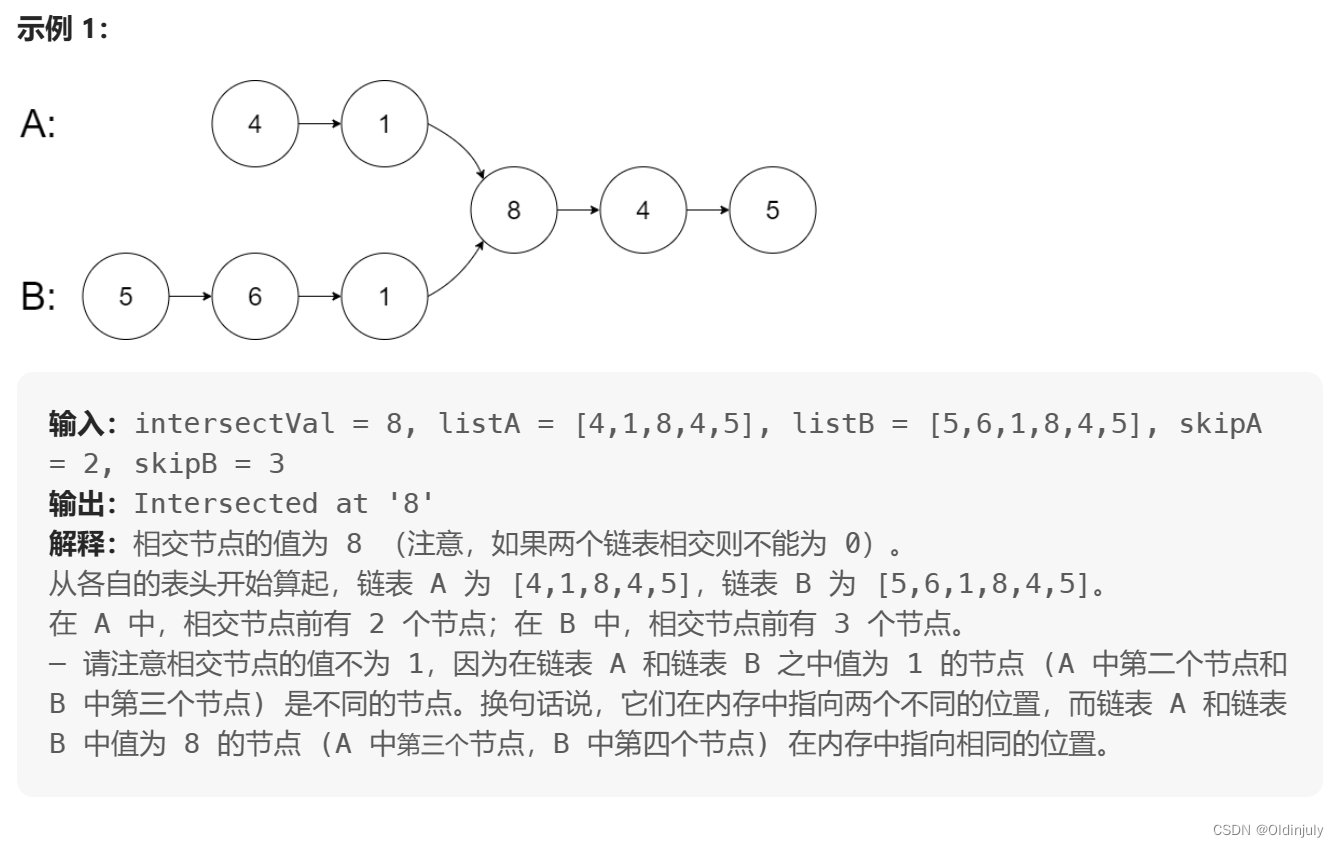
补充:相交链表
上一道题目回文链表中,后半部分逆置过后的链表其实就是相交链表。
相交链表是这样的:
而不是这样:
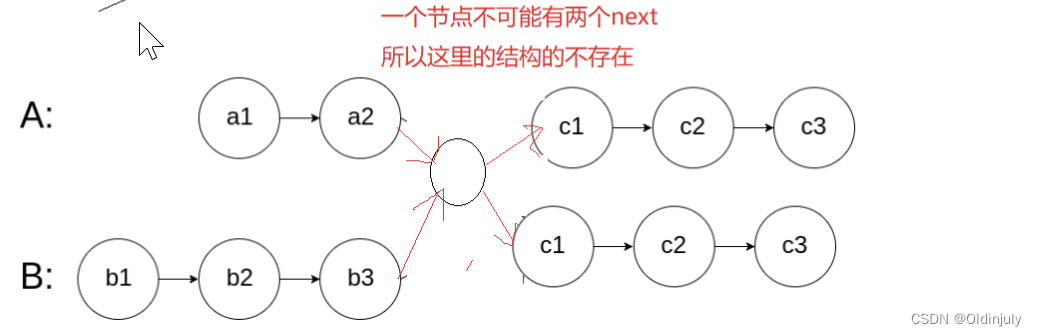
解法一:暴力遍历,headA的每一个节点都和headB的每一个节点比较(比较的是节点指针,不能比较val),时间复杂度O(N^2)。
解法二:
先遍历两个链表得到两个链表的长度,先判断尾结点是否相等,如果不相等一定不是相交链表;
再算出长度差,让长的先走长度差步,然后一起走,第一个相等的就是公共结点。
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{struct ListNode *curA = headA, *curB = headB;int lenA = 1, lenB = 1;while(curA->next)//这里是为了找到尾结点,所以len初始化成1{curA = curA->next;lenA++;} while(curB->next){curB = curB->next;lenB++;}//不相交if(curA != curB)return NULL; int dis = abs(lenA - lenB);struct ListNode *longList = headA, *shortList = headB;if(lenA < lenB){longList = headB;shortList = headA;}while(dis--){longList = longList->next;}while(longList != shortList){longList = longList->next;shortList = shortList->next;}return longList;
}
💐9.带环链表Ⅰ


这题也可以用快慢指针来解决:
fast指针:一次走两步
slow指针:一次走两步
在两个指针都进环后,他们在环中的某个位置一定能相遇!为什么呢?这要用相对运动的思想来分析一下了:
- 我们可以把带环链表进行抽象化,便于分析:
- 首先fast指针一定比slow指针先入环:
- slow指针入环后,fast指针开始追赶slow指针,只是典型的追击问题,假设slow入环后两者距离为N。
- slow走一步,fast走两步,每追击一次,两者的距离缩短1。两者的距离变化:N->N-1->N-2->...->1->0
- 综上,两者的距离最终为0,会相遇。
bool hasCycle(struct ListNode *head)
{struct ListNode *fast = head, *slow = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;if(fast == slow)return true; }return false;
}
思考:如果fast一次走三步、四步?他们会在环中相遇吗?
答案是不一定!
分析:
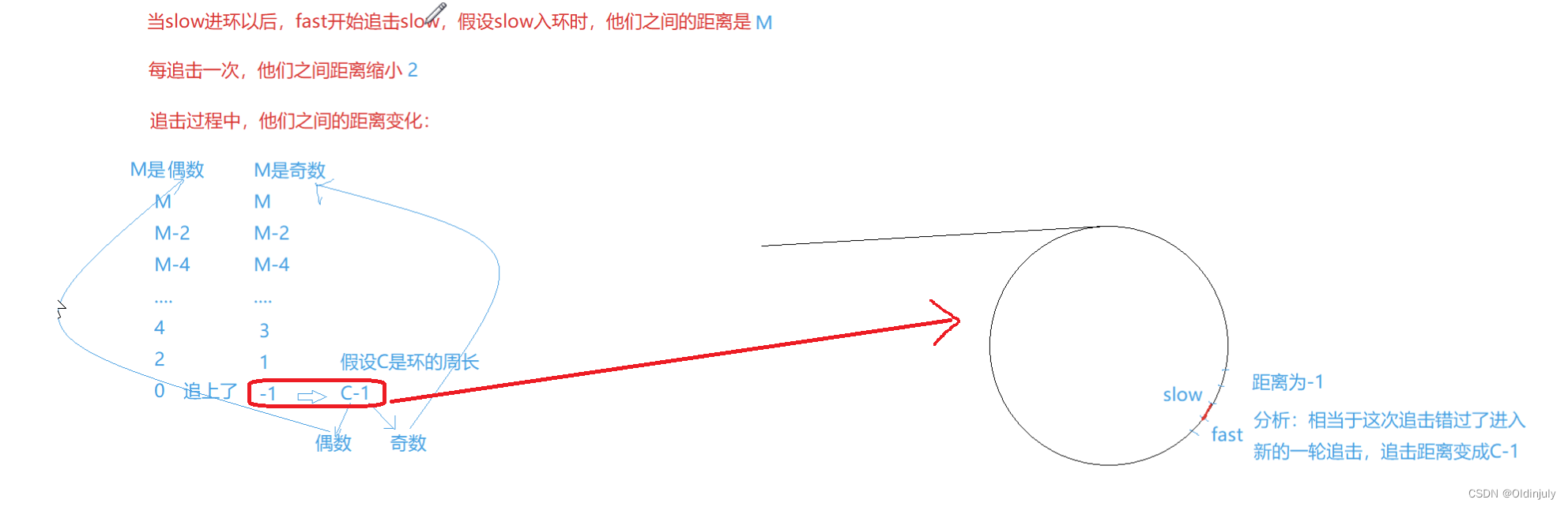
所以:初始距离M和C-1均为奇数的话,他们永不相遇!fast一次走四步也是一样的道理,综上fast最好的步数就是两步。
💐10.带环链表Ⅱ

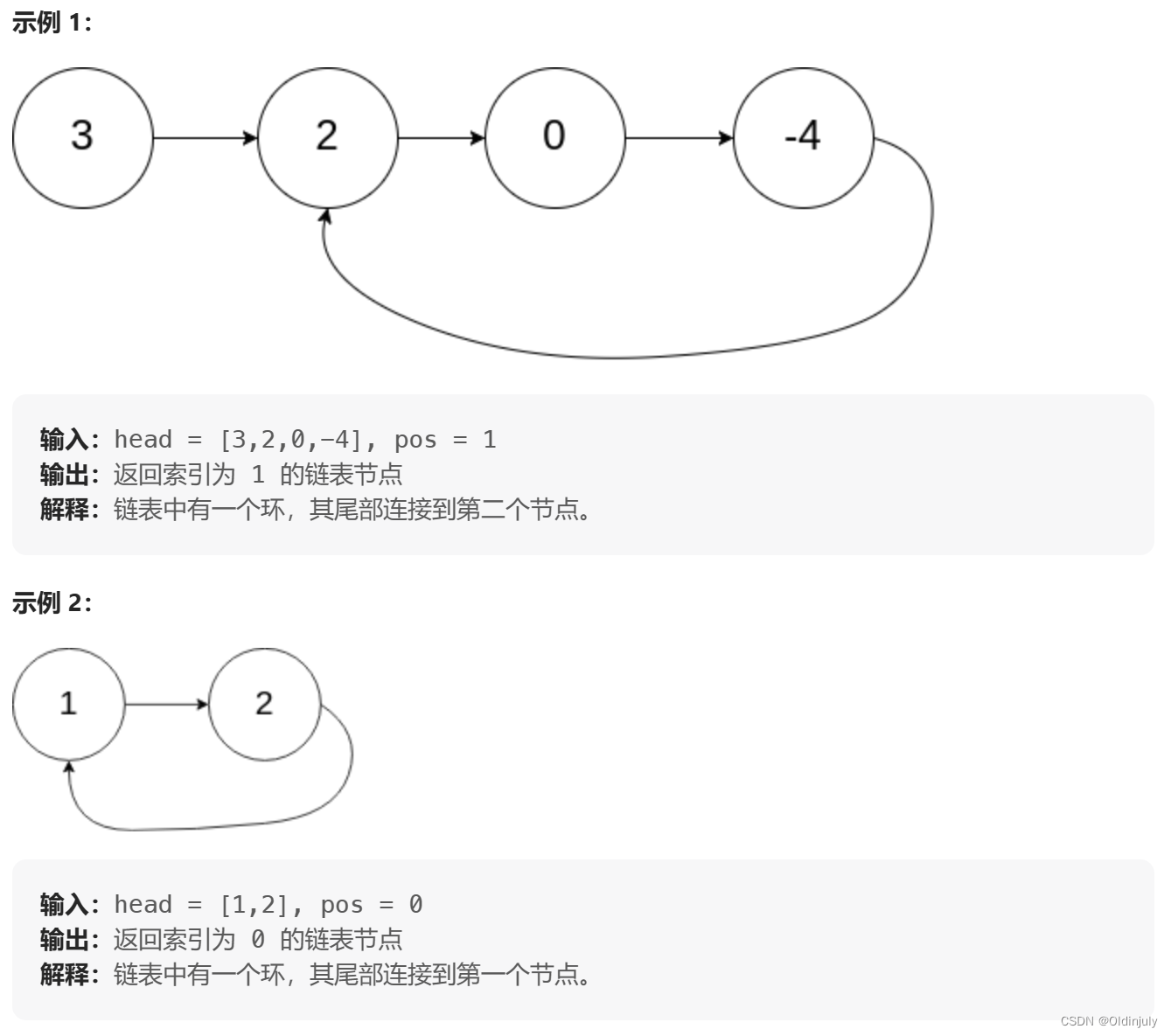

解法一:需要一些数学知识来分析: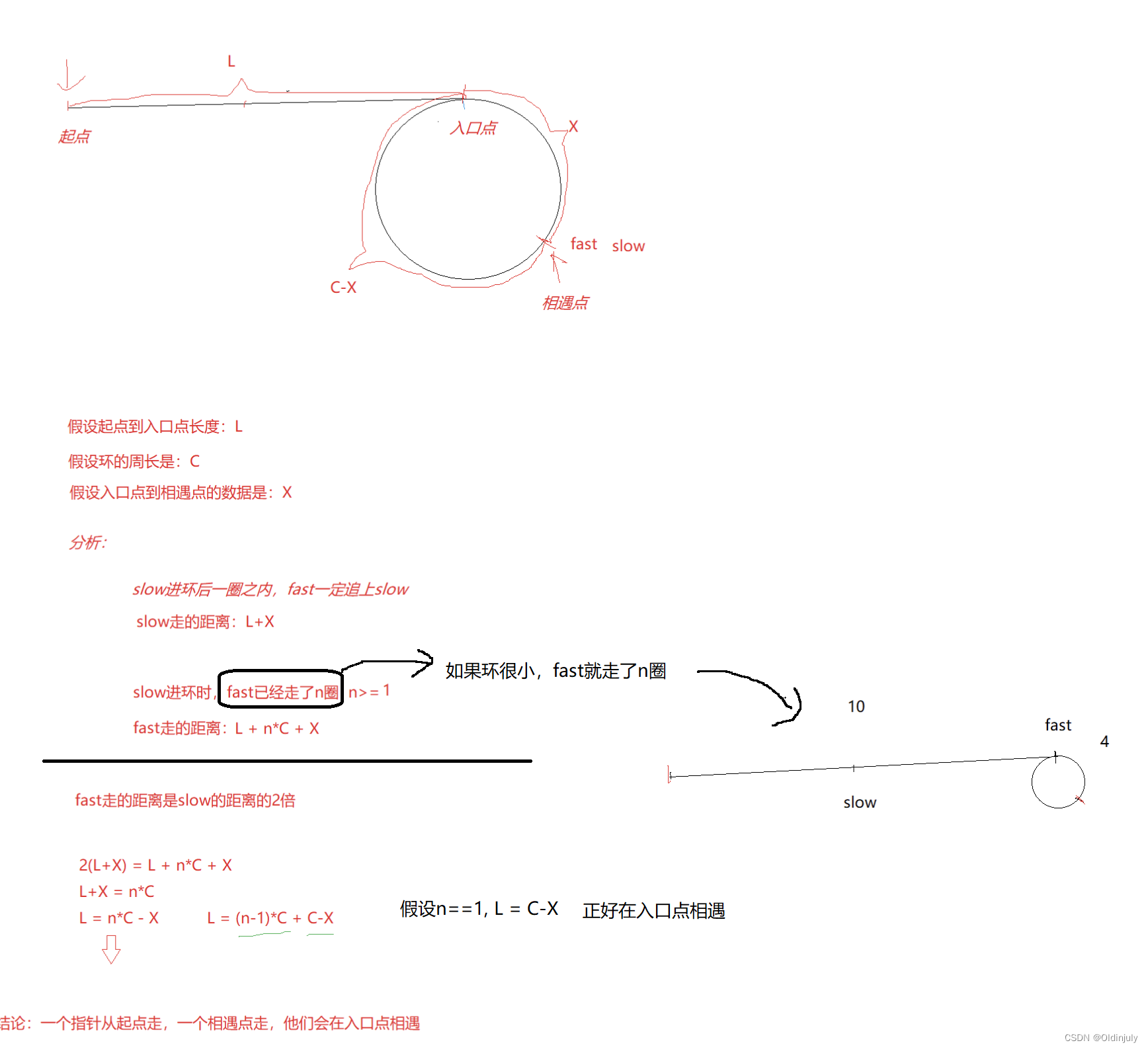
struct ListNode *detectCycle(struct ListNode *head)
{struct ListNode *slow = head, *fast = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;if(fast == slow){struct ListNode* meet = slow;struct ListNode* cur = head;while(cur != meet){cur = cur->next;meet = meet->next;}return cur;}}return NULL;
}解法二:相交链表法
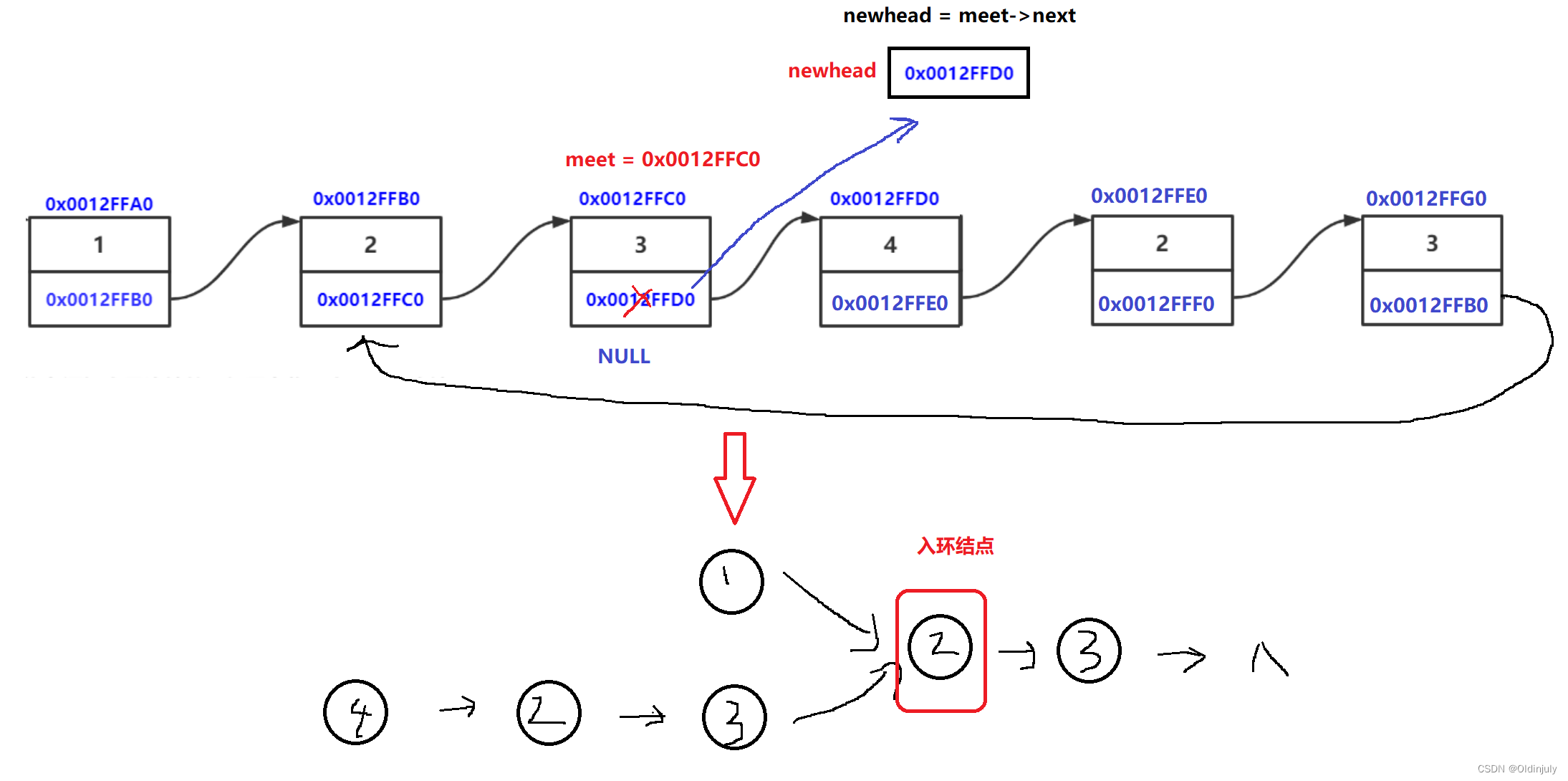
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{struct ListNode *curA = headA, *curB = headB;int lenA = 1, lenB = 1;while(curA->next)//这里是为了找到尾结点,所以len初始化成1{curA = curA->next;lenA++;} while(curB->next){curB = curB->next;lenB++;}//不相交if(curA != curB)return NULL; int dis = abs(lenA - lenB);struct ListNode *longList = headA, *shortList = headB;if(lenA < lenB){longList = headB;shortList = headA;}while(dis--){longList = longList->next;}while(longList != shortList){longList = longList->next;shortList = shortList->next;}return longList;
}struct ListNode *detectCycle(struct ListNode *head)
{struct ListNode *fast = head, *slow = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;if(fast == slow){struct ListNode* meet = slow;struct ListNode* newhead = meet->next;meet->next = NULL;return getIntersectionNode(head,newhead);}} return NULL;
}💐11.复制带随机指针的链表
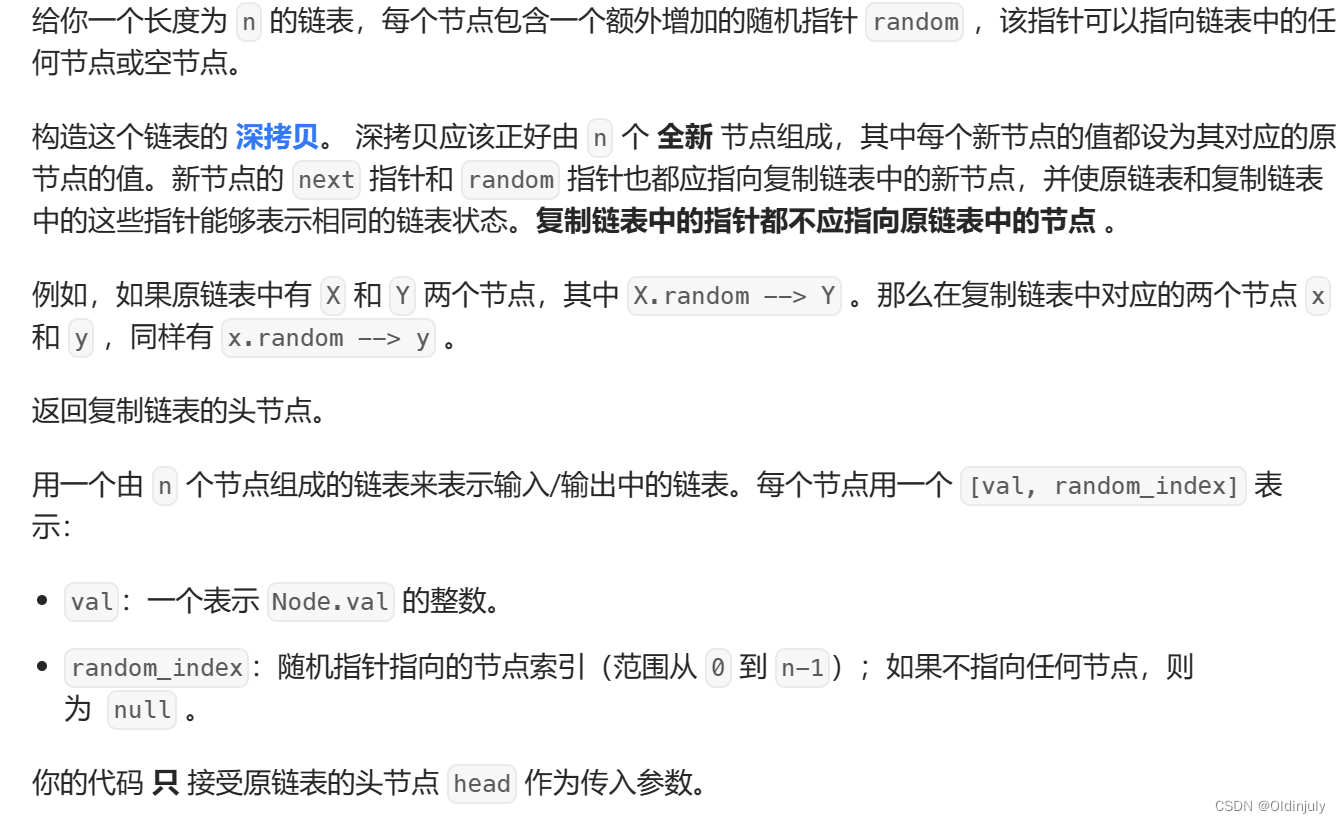
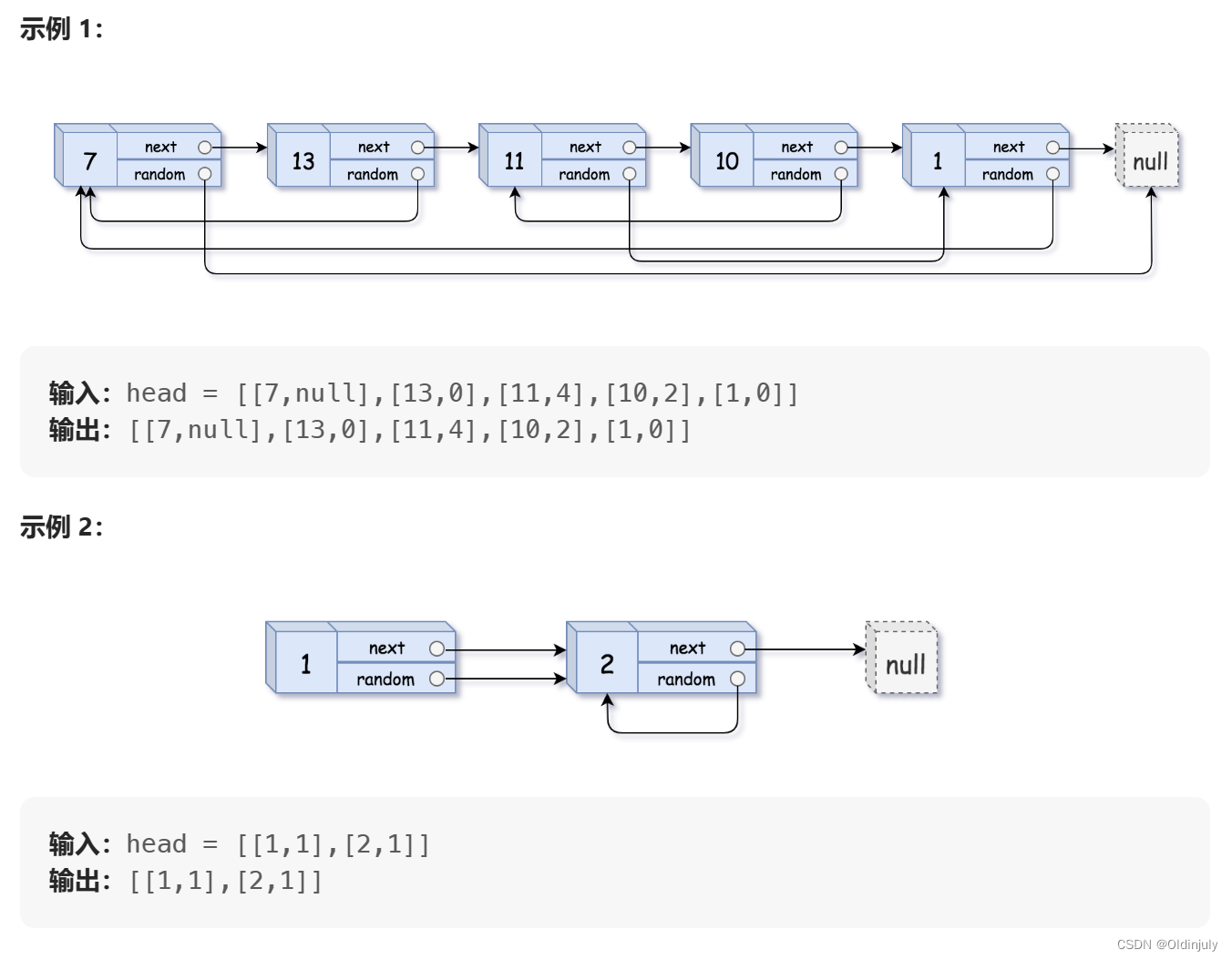
分析:所谓深拷贝,就是malloc出新的节点,然后把原始结点的数据赋值到新结点中。并且新链表随机指针的链接关系要和原链表的链接关系相同。
方法一:首先拷贝原链表的结点得到一个新链表,然后记录每个结点和他random域结点的相对位置,或者给每个节点设置一个索引值。通过相对位置来调整新链表的random域的链接关系。(注意:一定不能通过原链表的random域的值来进行链接,否则拷贝链表中的指针会指向原链表中。)
时间复杂度:O(N^2)
方法二:让拷贝结点插入到原节点的后面,然后置每个拷贝节点的random域,最后把拷贝结点给解下来并恢复原链表。
struct Node* copyRandomList(struct Node* head)
{//拷贝结点插入到原节点的后面struct Node* cur = head;while(cur){struct Node* next = cur->next;struct Node* copy = (struct Node*)malloc(sizeof(struct Node));copy->val = cur->val;cur->next = copy;copy->next = next;cur = next;} //置一下拷贝节点的random域cur = head;while(cur){struct Node* copy = cur->next;if(cur->random == NULL){copy->random = NULL;}else{copy->random = cur->random->next;}cur = copy->next;}//把拷贝结点尾插下来,并且恢复原结点cur = head;struct Node *copyhead = NULL, *copytail = NULL;while(cur){struct Node *copy = cur->next, *next = copy->next;//copy节点尾插到新链表if(copyhead == NULL){copyhead = copytail =copy;}else{copytail->next = copy;copytail = copytail->next;}//恢复原链表cur->next = next;cur = next;}return copyhead;
}