建设网站熊掌号深圳seo网络优化公司

鸢尾花数据集是机器学习领域非常经典的一个分类任务数据集。它的英文名称为Iris Data Set,使用sklearn库可以直接下载并导入该数据集。数据集总共包含150行数据,每一行数据由4个特征值及一个标签组成。标签为三种不同类别的鸢尾花,分别为:Iris Setosa,Iris Versicolour,Iris Virginica。
对于多分类任务,有较多机器学习的算法可以支持。本文将使用决策树、线性回归、SVM等多种算法来完成这一任务,并对不同方法进行比较。
01、使用Logistic实现鸢尾花分类
在前面介绍过Logistic用于二分类任务,对其进行扩展也用于多分类任务。下面将使用sklearn库完成一个基于Logistic的鸢尾花分类任务。如代码清单1所示,首先是导入sklearn.datasets包从而加载数据集,并将数据集按照测试集占比0.2随机分为训练集和测试集。
代码清单1 导入包以及加载数据集
rom sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.preprocessing import label_binarize
from sklearn.metrics import confusion_matrix, precision_score, accuracy_score,recall_score, f1_score, roc_auc_score, \roc_curve
import matplotlib.pyplot as plt# 加载数据集
def loadDataSet():iris_dataset = load_iris()X = iris_dataset.datay = iris_dataset.target# 将数据划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)return X_train, X_test, y_train, y_test如代码清单2所示,编写函数训练Logistic模型。
代码清单2 训练Logistic模型
# 训练Logistic模性
def trainLS(x_train, y_train):# Logistic生成和训练clf = LogisticRegression()clf.fit(x_train, y_train)return clfLogistic模型较为简单,不需要额外设置超参数即可开始训练。如代码清单3所示,初始化Logistic模型并将模型在训练集上训练,返回训练好的模型。
代码清单3 测试模型及打印各种评价指标
# 测试模型
def test(model, x_test, y_test):# 将标签转换为one-hot形式y_one_hot = label_binarize(y_test, np.arange(3))# 预测结果y_pre = model.predict(x_test)# 预测结果的概率y_pre_pro = model.predict_proba(x_test)# 混淆矩阵con_matrix = confusion_matrix(y_test, y_pre)print('confusion_matrix:\n', con_matrix)print('accuracy:{}'.format(accuracy_score(y_test, y_pre)))print('precision:{}'.format(precision_score(y_test, y_pre, average='micro')))print('recall:{}'.format(recall_score(y_test, y_pre, average='micro')))print('f1-score:{}'.format(f1_score(y_test, y_pre, average='micro')))# 绘制ROC曲线drawROC(y_one_hot, y_pre_pro)在预测结果时,为了方便后面绘制ROC曲线,需要首先将测试集的标签转化为one-hot的形式,并得到模型在测试集上预测结果的概率值即y_pre_pro,从而传入drawROC函数完成ROC曲线的绘制。除此外,该函数实现了输出混淆矩阵以及计算准确率、精确率、查全率以及f1-score的功能。
代码清单4 绘制ROC曲线
def drawROC(y_one_hot, y_pre_pro):# AUC值auc = roc_auc_score(y_one_hot, y_pre_pro, average='micro')# 绘制ROC曲线fpr, tpr, thresholds = roc_curve(y_one_hot.ravel(), y_pre_pro.ravel())plt.plot(fpr, tpr, linewidth=2, label='AUC=%.3f' % auc)plt.plot([0, 1], [0, 1], 'k--')plt.axis([0, 1.1, 0, 1.1])plt.xlabel('False Postivie Rate')plt.ylabel('True Positive Rate')plt.legend()plt.show()如代码清单4所示为绘制ROC曲线的代码实现。最后将加载数据集,训练模型,以及模型验证的整个流程连接起来从而实现main函数,如代码清单5所示。
代码清单5 main函数设置
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainLS(X_train, y_train)test(model, X_test, y_test)将上述所有代码放在同一py脚本文件中,如图1所示可得最终的输出结果为

图1 命令行打印的测试结果
绘制得到的ROC曲线如图2所示。

图2 ROC曲线
Logistic是一个较为简单的模型,参数量较少,一般也用于较为简单的分类任务中,当任务更为复杂时,可以选取更为复杂的模型获得更好的效果,下面将使用不同的模型从而验证同一任务在不同模型下的表现。
02、使用决策树实现鸢尾花分类
由于只改动了模型,加载数据集、模型评价等其他部分的代码不需要改动,如代码清单6所示,增加新的函数用于训练决策树模型。
代码清单6 使用决策树模型进行训练
from sklearn import tree
# 训练决策树模性
def trainDT(x_train, y_train):# DT生成和训练clf = tree.DecisionTreeClassifier(criterion="entropy")clf.fit(x_train, y_train)return clf同时修改main函数中调用的训练函数如代码清单7所示。
代码清单7 修改main函数内容
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainDT(X_train, y_train)test(model, X_test, y_test)最后运行可得命令行输出如图3所示。
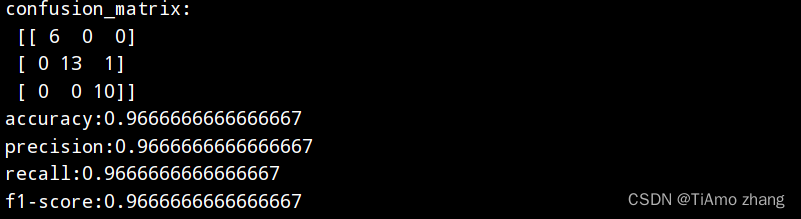
图3 决策树模型预测结果
以及ROC曲线如图4所示。
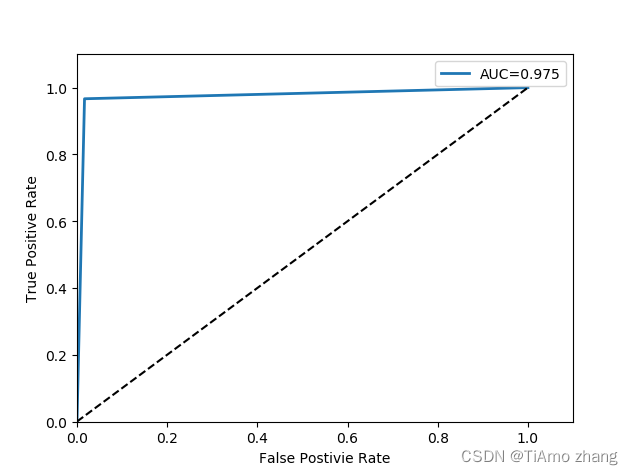
图4 决策树模型绘制ROC曲线
相比Logistic模型,决策树模型无论在哪一项指标上都得到了更高的评分,且决策树模型不会像Logistic模型一样受初始化的影响,多次运行程序均可获得相同的输出模型,而Logistic模型运行多次会发现评价指标会在某个范围内上下抖动。
03、使用SVM实现鸢尾花分类
到现在相信大家都已经非常熟悉如何继续修改代码从而实现SVM模型的预测,实现SVM模型的训练代码如代码清单8所示
代码清单8 使用SVM模型进行训练
# 训练SVM模性
from sklearn import svm
def trainSVM(x_train, y_train):# SVM生成和训练clf = svm.SVC(kernel='rbf', probability=True)clf.fit(x_train, y_train)return clf同时修改main函数,如代码清单9所示。
代码清单9 修改main函数内容
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainSVM(X_train, y_train)test(model, X_test, y_test)程序运行输出如图5所示。

图5 使用SVM模型预测结果
绘制得到的ROC曲线如图6所示。
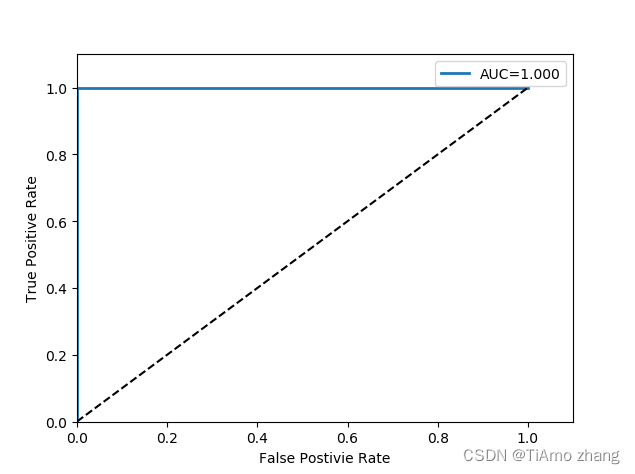
图6 使用SVM模型绘制的ROC曲线
可以发现,随着模型进一步变得复杂,最终预测的各项指标进一步上升,在三个模型中SVM模型的高斯核最终结果在测试集中表现得最好且没有发生过拟合的现象,因此可以选用SVM模型来完成鸢尾花分类这一任务。