重庆云阳网站建设公司推荐产品推广计划
最近学习了Transformer模型,突然意识到我常阅读的一篇论文中也使用了Transformer。回想起上次开组会时,老师问我论文中的模型是什么,我当时没有答上来,现在才发现其实用的就是Transformer。这种学习过程让我深感,学得越多,知识之间的联系就会越清晰,许多概念最终都能融会贯通。 这里也分享一下论文地址。
这篇论文主要探讨了如何利用联邦学习来解决跨域推荐问题,然后是在序列编码器和域提示机制上运用了Transformer来增强模型的性能。
序列编码器
在推荐系统中,不同的领域(Domain)之间需要进行数据交换与学习。为了保护用户隐私,这篇论文引入了联邦学习算法。与传统上传用户数据的方式不同,联邦学习仅上传模型参数的梯度进行聚合,让客户端在本地进行模型训练,从而防止攻击者通过附加手段从模型参数或梯度中推断出隐私特征。
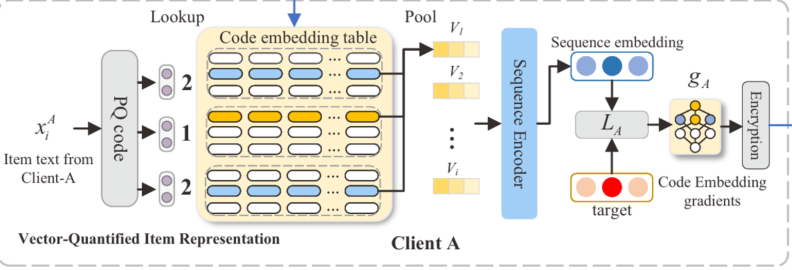
在这个背景下,论文中的序列编码器使用了Transformer架构,主要依赖于Transformer的核心组件:多头自注意力机制(Multi-Head Attention, MH)和位置感知前馈神经网络(Position-wise Feedforward Network, FFN)。这些模块使得模型能够捕捉用户行为数据中的顺序依赖关系。
具体来说,Transformer的自注意力机制能够让模型在计算某个输入项目时,同时关注其他位置的输入。这种全局的依赖建模能力,使得模型能够对用户的序列化行为进行更好的理解,从而提升推荐的准确性。
对于每个输入项目向量 v i v_i vi,我们首先将其与对应的位置信息嵌入 p j p_j pj相加(j为项目在序列中的位置),以确保模型能够感知项目序列中的位置。类似于处理句子时,不仅需要知道某个字的内容,还需要考虑它在句子中的位置。因此,有:
h j 0 = v i + p j h_j^0 = v_i + p_j hj0=vi+pj
然后,作者将这个初始状态 h j 0 h_j^0 hj0输入到MH和FFN中进行非线性变换,编码过程的定义如下:
H l = [ h 0 l ; . . . ; h n l ] H^l=[h_0^l;...;h_n^l] Hl=[h0l;...;hnl]
H ( l + 1 ) = F F N ( M H ( H l ) ) , l ∈ 1 , 2 , . . . , L H^(l+1)=FFN(MH(H^l)),l\in {1,2,...,L} H(l+1)=FFN(MH(Hl)),l∈1,2,...,L
其中𝑯𝑙 ∈ R𝑛×𝑑𝑉 表示第𝑙层中每个序列的隐藏表示,𝐿 是总层数。 我们将第 𝑛 个位置的隐藏状态𝒉i𝐴 = 𝒉n𝐿 作为序列表示(S𝐴 是域 A 中的输入序列)。
通过这种方式,序列编码器利用了Transformer的全局自注意力机制,能够同时考虑用户行为序列中所有项目的相互依赖关系,提升了跨域推荐的效果。
域提示
为了进一步提高跨域推荐的性能,论文设计了提示微调策略,该其中的域提示同样基于Transformer的多头注意力机制。域提示的核心在于捕捉每个领域(Domain)内用户的共性偏好。
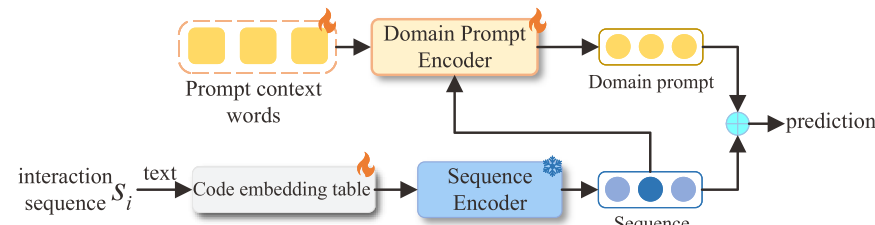
域提示机制由**提示上下文词(Prompt Context Words)和域提示编码器(Domain Prompt Encoder)**组成。在这个机制中,假设我们在域提示中有 d W d_W dW个上下文词,这些词通过Transformer中的多头注意力层(MA)进行编码。
与传统的自注意力不同,域提示机制利用预训练模型中的序列嵌入h作为查询向量,来对上下文词进行注意力计算。这种查询键-值的自注意力操作能够帮助模型通过上下文信息更精准地捕捉领域内的偏好特征。具体的计算过程如下:
M A ( P d o m a i n ) = [ h e a d 1 ; h e a d 2 ; . . . ; h e a d n h ] w O MA(P_{domain})=[head_1;head_2;...;head_{n_h}]w^O MA(Pdomain)=[head1;head2;...;headnh]wO
h e a d i = A t t e n t i o n ( h d W i Q , P d o m a i n W i K , P d o m a i n W i V ) head_i=Attention(h_dW_i^Q,P_{domain}W_i^K,P_{domain}W_i^V) headi=Attention(hdWiQ,PdomainWiK,PdomainWiV)
其中, n h n_h nh是注意力头的数量, W i Q , W i K , W i V ∈ R d V × d V / n h , W O ∈ R d V × d V W_i^Q, W_i^K, W_i^V \in \mathbb{R}^{d_V \times d_V/n_h},W_O \in \mathbb{R}^{d_V \times d_V} WiQ,WiK,WiV∈RdV×dV/nh,WO∈RdV×dV
为可学习参数, h d \mathbf{h}_d hd是上下文词的表示。
通过这种机制,域提示能够更好地从不同领域的用户行为中提取共性信息,进而提升跨域推荐的效果。
总结
这篇论文利用了Transformer的多头自注意力机制和前馈神经网络,在序列编码器和域提示学习机制中进行建模。Transformer的全局依赖建模能力,使得模型在捕捉用户行为序列中的复杂模式时更加有效,同时,通过联邦学习保护用户隐私,解决了跨域推荐中的关键问题。