网站源码安装教程网络营销手段有哪些方式
Flink 概述
Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心优点包括:
- 低延迟:Flink 可以在毫秒级的时间内处理数据,提供了低延迟的数据处理能力。
- 高吞吐:吞吐量巨大。
- 分布式计算:Flink 支持分布式计算,它可以在大规模集群上运行,并提供了高可用和容错机制。
- 流式数据处理:Flink 基于流式数据处理模型,支持实时数据处理和数据增量更新。
- 事件驱动:Flink 的计算引擎是基于事件驱动的,它使用消息传递机制来处理数据。
Flink 的数据处理流程
Flink 的数据处理流程包括以下几个步骤:
- 数据输入:Flink 可以从各种数据源中读取数据,如 Kafka、HDFS 等。
- 数据转换:Flink 可以使用 DataStream API 或 SQL API 对数据进行转换和处理。
- 数据分区:Flink 可以根据数据的属性或规则对数据进行分区,以便在分布式集群上进行处理。
- 数据传输:Flink 可以使用网络传输机制将数据传输到其他节点或进程。
- 数据输出:Flink 可以将处理后的数据写入到各种数据存储中,如 Kafka、HDFS 等。
Flink架构解析
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
![[图片]](https://img-blog.csdnimg.cn/direct/d172c69ebee4499a894d56fdd188f961.png)
JobManager
类似于司令官,分配工作给干活的士兵(TaskManager),听取士兵的汇报,当士兵失败时做出恢复等反应。
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager
- ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的基本单位。
- Dispatcher
- Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每一个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster
- 1个JobMaster 负责管理1个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby(请参考 高可用(HA))。
TaskManager
TaskManager(也称为 worker):执行JobManager分配过来的任务,并向JobManager汇报。taskManager之间也会交换数据
TaskManager中会有一到多个task slot, task slot是资源调度的最小单位, task slot 的数量表示并发处理task的数量。假设1个task有N个算子,那么执行这个task的slot 就会执行N个算子(直到结束)。
Client
Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。
Task和算子(Operator)
非分布式场景
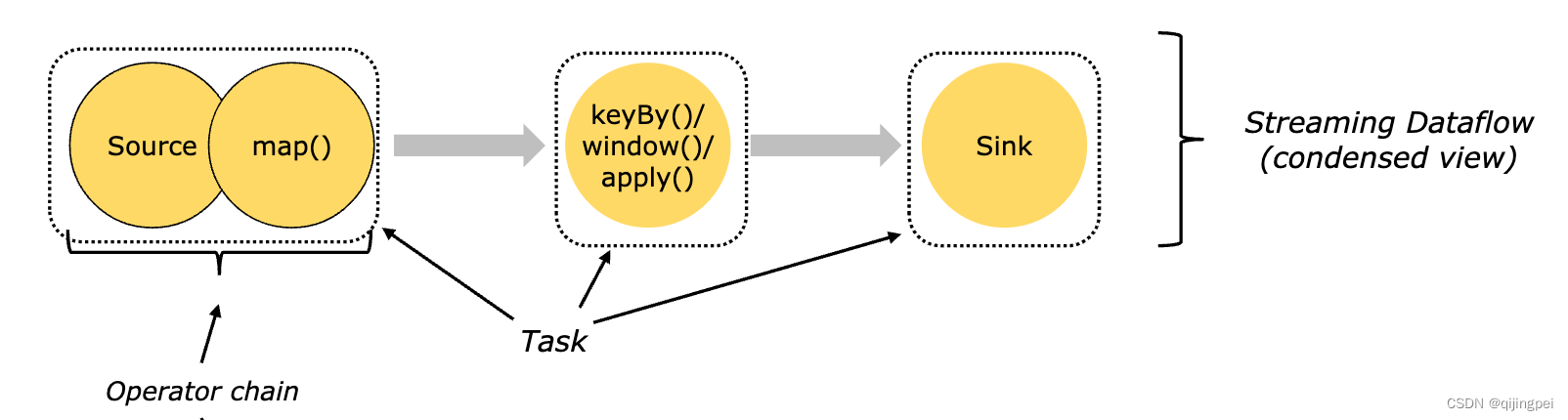
假设程序目前需要依次经过以下算子:source->map->keyBy->window->apply->Sink,如果每个算子都用1个线程执行的话,一共有多达6个线程,不仅导致线程间切换、缓冲数据会有不小的开销,还降低了吞吐量。
为降低线程切换、缓冲的开销,Flink会把可以在同一个线程中执行的算子,链在一起,我们管他叫“算子链”。如图有3个算子链:source+map是1个算子链,keyBy+window+apply是1个算子链,sink是一个。每个算子链会由1个Task来执行。
统计下数量:共有3个Task,会占用3个Task Slot执行。
线程数从6缩减成3个,降低了线程间切换、缓冲数据的开销。
把哪些算子“链”在一起,是可以配置的。
分布式场景
![[图片]](https://img-blog.csdnimg.cn/direct/32d4c209936746e9b644e60fb079517a.png)
分布式场景下,工作会有多个taskManager共同完成工作。如图所示,当前并行度为2.
统计下数量:共有5个Task,每个Task会被分配到1个Task Slot上执行,所以会占用5个Slot。
所以Task Slot的数量,决定了可以并行执行多少个Task。
Task Slots 和资源
1个TaskManager下的task slots共享CPU资源,但内存会分开。
1个TaskManager都是一个 JVM 进程,这导致TaskManager下的slot会共享TCP连接和心跳信息。
Task Slot共享解决阻塞问题
继续上面的例子,1个Task被分配到1个Slot中:
![[图片]](https://img-blog.csdnimg.cn/direct/fccf3a32f11d44339ef511e867e3e946.png)
这样会有1个问题:只有Source\Map拿到数据后,keyBy操作才能开始处理,这会导致keyBy所在算子有可能空闲。
为解决这样一个问题,Flink使用了Slot共享:slot被多个Task共享,如下图:
![[图片]](https://img-blog.csdnimg.cn/direct/2c0d98b5c5f6489f9d34d5cec12d020b.png)
通过Slot共享,将示例中的基本并行度从 2 个增加到 6 个,让每个Slot都可以执行Source算子,这样Source所在的Slot就不会阻塞别的Slot了。这样可以充分利用Slot的资源,同时确保繁重的Task们在 TaskManager 之间公平分配。
小总结:
1. Flink通过将多个算子链在一起,减少了线程之间的切换开销
2. 将任务分配到多个TaskManager上,提高了处理的速度
3. 最后通过Slot共享,确保Slot之间不会阻塞,充分让Slot忙碌起来。
WebUI界面+常见问题排查思路
通过Web UI,可以看到TaskManager、Slot的数量用于速度调优,也可以查看日志用于问题排查。
Flink的Web UI界面的地址是http://localhost:8081,其中localhost是JobManager的主机地址,8081是JobManager的Web UI端口号。在浏览器中输入这个地址,就可以访问Flink的Web UI界面了。
集群概览:查看任务是否正常运行、资源是否需要扩容
![[图片]](https://img-blog.csdnimg.cn/direct/94a0ff9fe5b44d7b87969f5331355a72.png)
点击1个Job查看Job详情:

点击1个算子查看算子详情:查看数据倾斜、反压等性能问题
![[图片]](https://img-blog.csdnimg.cn/direct/a45aa30791eb45c48594583661e790a7.png)
TaskManager:可以查看TaskManager的日志排查问题,注意蛋疼的是问题不一定出现在哪个TaskManager上。
![[图片]](https://img-blog.csdnimg.cn/direct/002a7c2c4eea48c2b7b5212871199b82.png)
JobManager:
![[图片]](https://img-blog.csdnimg.cn/direct/c6ae0e4858bc49cba4f56b68e82c0773.png)
Flink 的容错机制
Flink 的容错机制是通过 Checkpointing 实现的。Checkpointing 允许用户在处理流式数据时定期保存状态,以便在出现故障时恢复状态。Flink 的容错机制包括以下几个步骤:
- 定义 Checkpointing 策略:用户需要定义 Checkpointing 的频率和保存状态的位置。
- 触发 Checkpointing:在处理数据时,Flink 会根据定义的 Checkpointing 策略触发 Checkpointing。
- 恢复状态:在出现故障时,Flink 会根据保存的 Checkpointing 恢复状态。
Flink 的应用场景
Flink 可以应用于多种场景,如:
- 实时数据处理:Flink 可以用于实时数据处理,如实时监控、实时分析等。
- 数据清洗:Flink 可以用于数据清洗,如数据去重、数据清洗等。
- 数据分析:Flink 可以用于数据分析,如数据统计、数据挖掘等。
- 数据集成:Flink 可以用于数据集成,如数据同步、数据迁移等。
Flink常见算子
Flink 的常见算子包括:
- Source:从上游收集数据
- Sink:发送数据给下游
- Map:对输入数据进行转换操作,如数据清洗、数据格式化等。
- FlatMap:对输入数据进行扁平化操作,将一个数据项转换为多个数据项。
- Filter:对输入数据进行筛选操作,只保留符合条件的数据项。
- KeyBy:对输入数据进行分组操作,根据指定的键对数据进行分组。
- Reduce:对输入数据进行聚合操作,将多个数据项聚合为一个数据项。
- Window:对输入数据进行窗口操作,将数据按照指定的窗口大小进行分组。
- Union:对多个输入数据进行合并操作,将多个数据集合并为一个数据集。
- Split:对输入数据进行分裂操作,将一个数据集分裂为多个数据集。
- Join:对多个输入数据进行连接操作,将多个数据集按照指定的键进行连接。
- SQL:对输入数据进行 SQL 查询操作,使用 SQL 语句对数据进行查询和分析。
这些算子可以组合使用,以实现更复杂的数据处理逻辑。
总结
Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心特点包括流式数据处理、事件驱动、分布式计算、低延迟等。Flink 的核心组件包括 DataStream API、SQL API、Stateful Stream Processing、Checkpointing 等。Flink 的数据处理流程包括数据输入、数据转换、数据分区、数据传输、数据输出等。Flink 的状态管理是通过 Stateful Stream Processing 实现的,它允许用户在处理流式数据时维护状态。Flink 的容错机制是通过 Checkpointing 实现的,它允许用户在处理流式数据时定期保存状态,以便在出现故障时恢复状态。Flink 可以应用于多种场景,如实时数据处理、数据清洗、数据分析、数据集成等。