宁波甬晟园林建设有限公司网站网址收录入口
参考博文:神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_pynq 注意力机制_Bubbliiiing的博客-CSDN博客
【计算机视觉】详解 自注意力:Non-local 模块与 Self-attention (视觉注意力机制 (一))_自注意力模块_何处闻韶的博客-CSDN博客
参考视频:
SEnet模块实现_哔哩哔哩_bilibili
视觉注意力代码汇总仓库:
GitHub - MenghaoGuo/Awesome-Vision-Attentions: Summary of related papers on visual attention. Related code will be released based on Jittor gradually.
https://github.com/xmu-xiaoma666/External-Attention-pytorch
背景
在计算机视觉中,注意力机制 (attention) 旨在让系统学会注意力 —— 能够忽略无关信息而关注重点信息。
分类1
注意力机制一种是软注意力 (soft attention),另一种则是强注意力 (hard attention)。
软注意力
这种注意力 更关注 区域 或 通道,而且软注意力是 确定性的 注意力,学习完成后直接可以通过网络生成。最关键之处在于软注意力是 可微 的,这意味着其可通过神经网络算出梯度 (如 PyTorch 自动求导),且前向传播和后向反馈来习得注意力的权重。
强注意力
与软注意力不同点在于,首先它 更关注 点,即图像中的 每个点都有可能延伸出注意力;同时强注意力是一个 随机的预测过程,更强调 动态变化。当然,最关键之处在于,强注意力是 不可微的,训练过程往往是通过 强化学习 (reinforcement learning) 来完成的。
本文中主要讲软注意力!
分类2
注意力分成了四种基本类型:通道注意力、空间注意力、时间注意力和分支注意力,以及两种组合注意力:通道-空间注意力和空间-时间注意力。

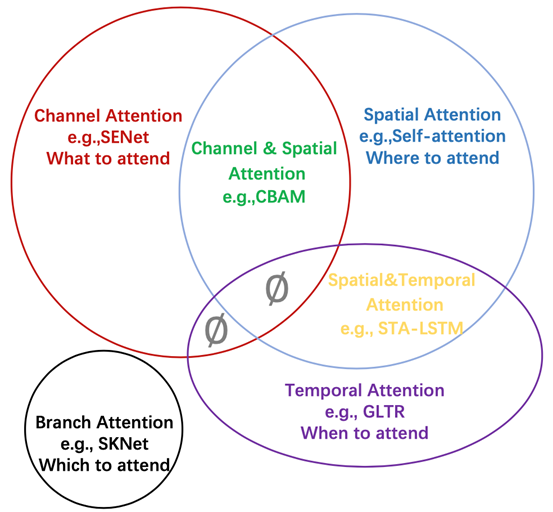
SENet-通道注意力
SENet是通道注意力机制的典型实现。
2017年提出的SENet是最后一届ImageNet竞赛的冠军,其实现示意图如下所示,对于输入进来的特征层,我们关注其每一个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。利用SENet,我们可以让网络关注它最需要关注的通道。
其具体实现方式就是:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
代码
import torch
from torch import nnclass senet(nn.Module):def __init__(self, channel, ratio=16): # channel为输入通道数,ratio为压缩比super(senet, self).__init__() # 初始化父类self.avg_pool = nn.AdaptiveAvgPool2d(1) # 1.全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.fc = nn.Sequential( # 2.两个全连接层nn.Linear(channel, channel // ratio, False), # 第一次全连接神经元个数较少,输入通道数,输出通道数,是否偏置nn.ReLU(inplace=True), # 激活函数nn.Linear(channel // ratio, channel, False), # 第二次全连接神经元个数和输入特征层相同。nn.Sigmoid(), # 激活函数)def forward(self, x):b, c, h, w = x.size() # b为batch_size,c为通道数,h为高,w为宽avg = self.avg_pool(x) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1avg = avg.view(b, c) # b*c*1*1 -> b*cfc = self.fc(avg).view([b, c, 1, 1]) # 对平均池化后的特征图进行两次全连接,再view reshape方便后面的处理 #b*c -> b*c*1*1print(fc) # 打印测试一下return x * fc #4.乘上原输入特征层# 测试一下
model = senet(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)
CBAM-通道+空间注意力

CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
通道注意力CAM

图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。这两个池化都是对高,宽进行池化的。在完成池化后可以获得两个特征长条,特征长条长度都是我们输入的通道数。
之后对平均池化和最大池化的结果(特征长条),利用共享的全连接层进行处理,全连接层负责学习通道之间的权重关系,增强重要通道的特征响应,并抑制不重要通道的特征响应,这个过程相当于对每个通道应用一个可学习的权重系数。
全连接后得到特征长条,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。(这个绿色部分和我们原特征层的通道数一样
空间注意力SAM

我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值,与上面对高宽进行池化不同,此处对通道进行池化。相当于把输入图像压瘪了,通道数为1。
将这些压瘪的图像堆叠之后得到高宽为2(HxWx2)的特征层。
对高宽为2的特征图利用一次通道数为1的卷积调整通道数,获得高宽为1(HxWx1)的特征层,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
代码
# 是通道注意力和空间注意力的结合
import torch
from torch import nn# 通道注意力
class channel_attention(nn.Module):def __init__(self,channel, ratio = 16): # channel为输入通道数,ratio为压缩比super(channel_attention, self).__init__() # 初始化父类self.max_pool = nn.AdaptiveMaxPool2d(1) # 全局最大池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.fc = nn.Sequential( # 2.两个全连接层nn.Linear(channel, channel//ratio, False) # 第一次全连接神经元个数较少,输入通道数,输出通道数,是否偏置,nn.ReLU(inplace=True) # 激活函数,nn.Linear(channel//ratio, channel, False) # 第二次全连接神经元个数和输入特征层相同。)self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):b, c, h, w = x.size()max_pool_out = self.max_pool(x).view([b,c]) # 全局最大池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1, 再view reshape方便后面的处理, b*c*1*1 -> b*cavg_pool_out = self.avg_pool(x).view([b,c]) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1, 再view reshape方便后面的处理, b*c*1*1 -> b*c#再用全连接层进行处理max_fc_out = self.fc(max_pool_out).view([b,c,1,1]) # b*c -> b*c*1*1avg_fc_out = self.fc(avg_pool_out).view([b,c,1,1]) # b*c -> b*c*1*1#相加out = max_fc_out + avg_fc_outout = self.sigmoid(out) # 激活函数return x * out # 通道注意力机制的输出# 空间注意力
class spatial_attention(nn.Module):def __init__(self,kernel_size = 7): # kernel_size为卷积核的大小super(spatial_attention, self).__init__() # 初始化父类self.conv = nn.Conv2d(2, 1, kernel_size, 1, padding=kernel_size//2,bias=False) # 1.卷积层self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):max_out,_ = torch.max(x, dim=1, keepdim=True) # 最大池化, _为最大值的索引,这里不需要;keepdim=True保持维度不变avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化pool_out = torch.cat([avg_out,max_out], dim=1) # 拼接out = self.conv(pool_out) # 卷积out = self.sigmoid(out) # 激活函数return x * out # 空间注意力机制的输出# CBAM模块, 结合通道注意力机制和空间注意力机制
class CBAM(nn.Module):def __init__(self, channel, ratio = 16, kernel_size = 7):super(CBAM, self).__init__()# 定义通道注意力机制self.channel_attention = channel_attention(channel, ratio)# 定义空间注意力机制self.spatial_attention = spatial_attention(kernel_size)def forward(self,x):x = self.channel_attention(x) # 通道注意力机制的输出x = self.spatial_attention(x) # 空间注意力机制的输出return x# 测试一下
model = CBAM(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)
ECA-通道注意力的改进版
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。1D卷积是一种应用于序列数据(或一维数据)的卷积操作。在计算机视觉中,我们熟悉的卷积通常是应用于图像数据的2D卷积,而1D卷积则主要用于处理一维序列数据,例如文本、语音和时间序列数据等。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。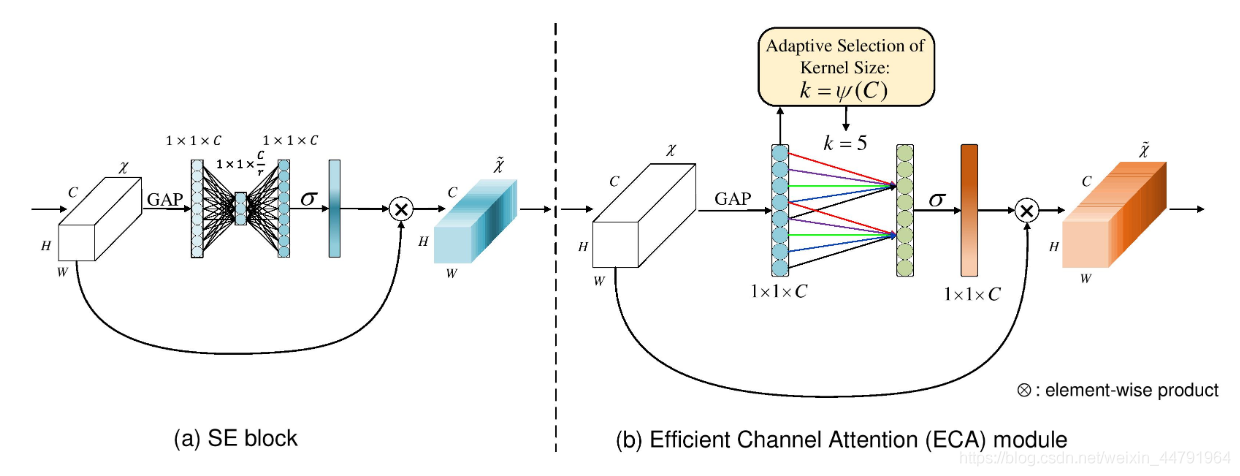
代码
import mathimport torch
import torch.nn as nnclass eca_block(nn.Module):def __init__(self,channel,gamma= 2,b = 1):super(eca_block,self).__init__() # 初始化父类kernel_size = int(abs((math.log(channel, 2)+b )/ gamma)) # 计算卷积核大小kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1 # 卷积核大小必须为奇数padding = kernel_size//2 # 填充大小self.avg_pool = nn.AdaptiveAvgPool2d(1) # 1.全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图,这里的1表示输出的通道数# 定义1D卷积self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=padding, bias=False) # 2.一维卷积,这里的1,1是把它当作序列模型来看self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):b, c, h, w = x.size() # b为batch_size,c为通道数,h为高,w为宽avg = self.avg_pool(x).view([b,1,c]) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*1*c, 第一个维度是batchsize, 第二个维度是通道数,第二个维度是特征长度,第三个维度代表每个时序out = self.conv(avg) # 一维卷积out = self.sigmoid(out).view(b,c,1,1) # 激活函数,再reshape成b*c*1*1return out*x# 测试一下
model = eca_block(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)自注意力
首先我们要区分一般的注意力机制和自注意力机制
一般注意力的过程是通过一个查询变量 Q,去找到 V 里面比较重要的东西:
1)它先假设 K==V,然后 QK 相乘求相似度A,然后 AV 相乘得到注意力值Z,这个 Z 就是 V 的另外一种形式的表示
Q 可以是任何一个东西,V 也是任何一个东西, K往往是等同于 V 的(同源),但是不同源也可以!!!
总之,注意力机制是一个很宽泛(宏大)的一个概念,QKV 相乘就是注意力,但是他没有规定 QKV是怎么来的,他只规定 QKV 怎么做
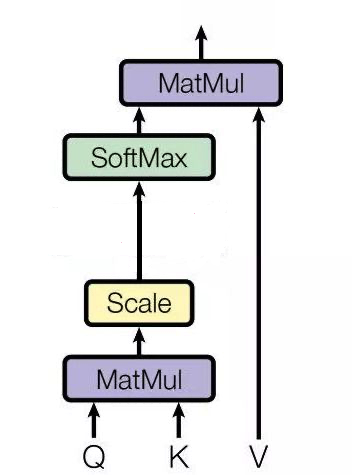
而QKV如果从同一个矩阵中获得,那么就叫做自注意力,不仅规定了 QKV 同源,而且固定了 QKV 的做法
QKV不同源呢,就是交叉注意力机制
感觉还蛮流行的,到时候单独写一篇好了
注意力机制应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面,可以放在主干网络,也可以放在加强特征提取网络。
由于放置在主干会导致网络的预训练权重无法使用,一般将注意力机制应用加强特征提取网络上。
下面是一些添加注意力模块时的常见情况,以及可能会产生好坏效果的因素:
添加效果会好的情况:
-
大尺寸图像或复杂任务:当处理大尺寸图像或者复杂的任务时,网络需要处理更多的信息和细节。此时,注意力机制可以帮助网络在解码器阶段集中注意力,关注对任务更重要的局部信息,而忽略不重要的区域。
-
长距离依赖:在一些任务中,像语义分割或图像生成等,信息的联系可能存在长距离的依赖。注意力机制可以帮助捕获远距离区域之间的关系,从而更好地理解图像的语义。
-
不平衡数据:当数据集存在类别不平衡时,注意力机制可以帮助网络更好地处理少数类别,从而提高模型对少数类别的分割效果。
添加会起到反作用的情况:
-
小数据集:对于小规模数据集,引入复杂的注意力机制可能导致过拟合,因为模型可能会在训练数据中过度关注细节,而无法泛化到新数据上。
-
简单任务:在处理相对简单的任务或者小尺寸图像时,注意力机制可能会引入额外的计算负担,而无法给模型带来明显的性能提升。
-
不恰当的设计:如果注意力模块的设计不当,例如过于复杂、参数量过大或者超参数设置不合理,可能会导致模型收敛困难或者性能下降。
未来展望
-
注意力机制的充分必要条件
-
更加通用的注意力模块
-
注意力机制的可解释性
-
注意力机制中的稀疏激活
-
基于注意力机制的预训练模型
-
适用于注意力机制的优化方法
-
部署注意力机制的模型