全网营销型网站建设模板百度关键词seo优化

苏州大学从头训练的双语非对称Encoder-Decoder模型OpenBA已正式开源!
主要亮点包括:
亮点一:此模型为中文开源社区贡献了一个有代表性的编码器解码器大语言模型,其训练过程(包括数据收集与清洗、模型构建与训练)已完全开源。
亮点二:数据方面,OpenBA所使用的数据均公开可获取,模型的能力产生更加透明。
亮点三:针对中文instruction能力,我们基于开源的标注数据构建了大规模中文Flan数据集,并完全开放了其构建方法。
亮点四:仅凭380B token的训练量,在多种中英下游任务上超越了许多同参数量、更大数据训练的模型。
技术报告与项目地址
技术报告:
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
https://arxiv.org/abs/2309.10706
模型:
https://huggingface.co/OpenBA
项目:
https://github.com/OpenNLG/OpenBA.git
论文概述
语言大模型的发展离不开开源社区的贡献。在中文开源领域,虽有GLM,Baichuan,Moss,BatGPT之类的优秀工作,但仍存在以下空白:
主流开源大语言模型主要基于decoder-only架构或其变种,encoder-decoder架构仍待研究。
许多中文开源指令数据集是由ChatGPT生成或从英文翻译而来,存在版权和质量问题。
为填补这些空白,该工作:
采用了非对称的编码器-解码器架构(浅编码器,深解码器),融入UL2多任务训练、长度适应训练和双语Flan训练三个阶段。
构建了包括五千万条指令的中文Flan数据集,涵盖了44个任务,同时完全开放收集和构建方法。
预训练数据构成
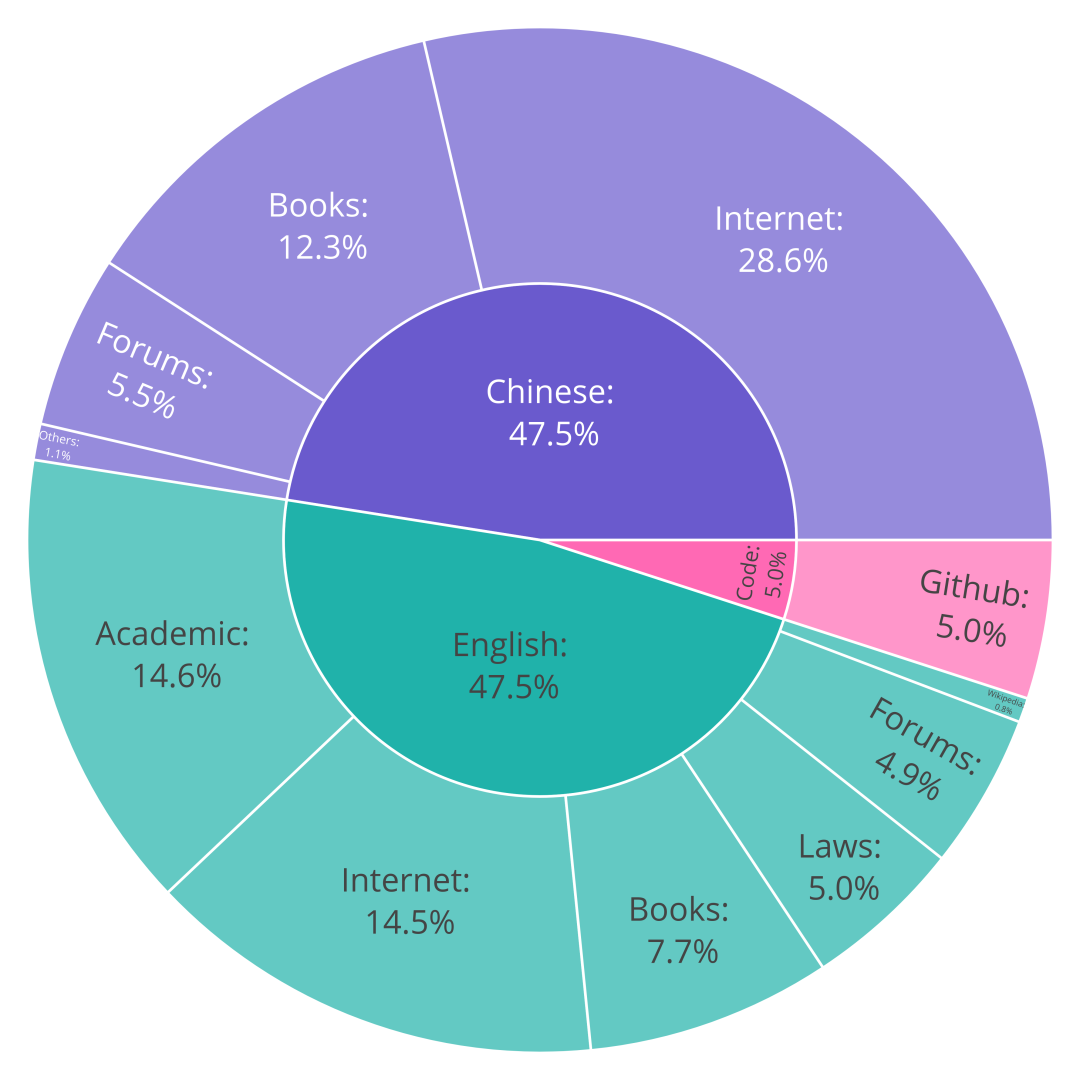
OpenBA的数据构成为190B tokens 英文数据,190B tokens 中文数据和20B tokens 代码数据。其中,英文数据和代码数据从The Pile数据集中采样而来,而中文数据集主要来源于Common Crawl的子集和FudanNLPLAB的CBook-150K数据集。其具体的预训数据构成如下图所示:
双语Flan数据收集
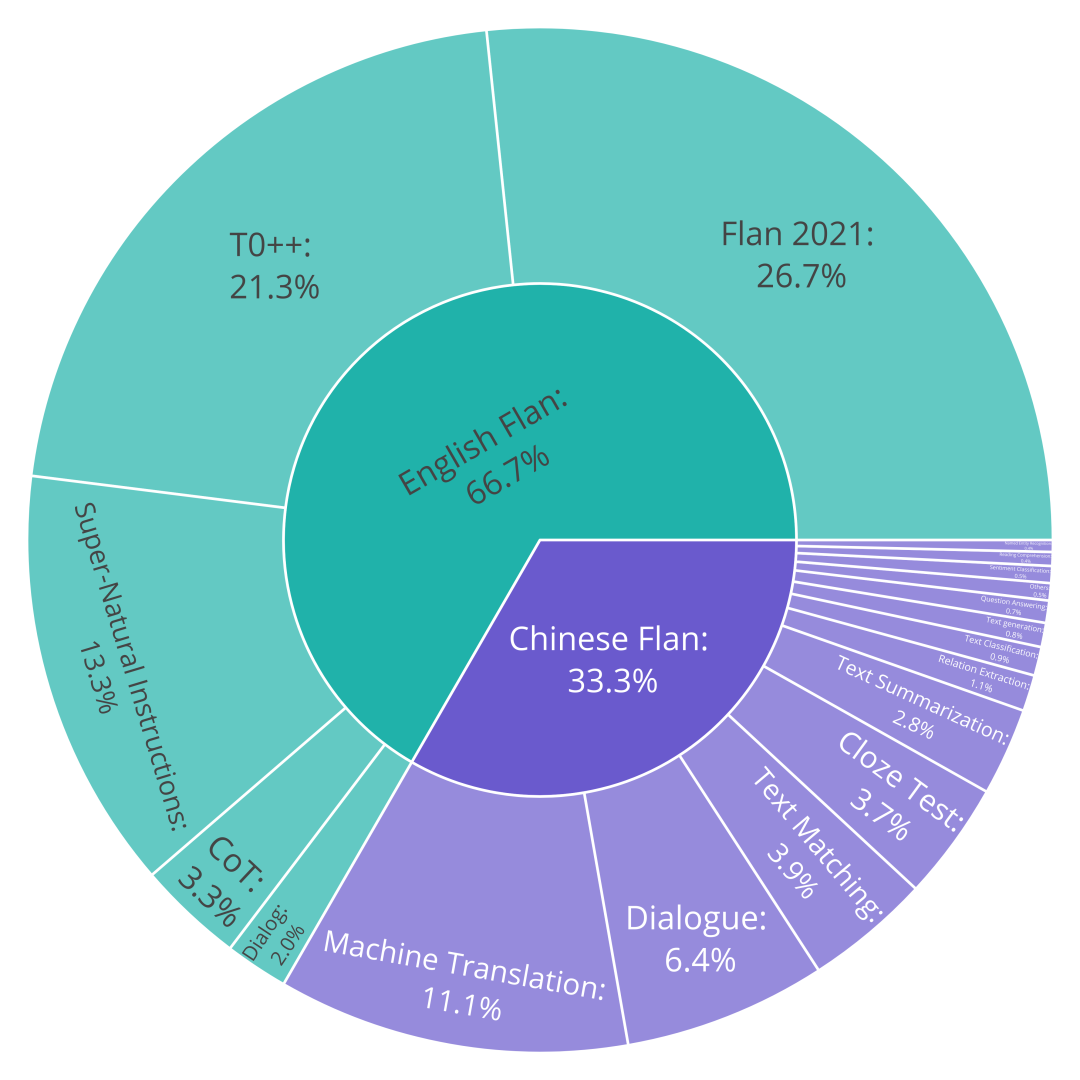
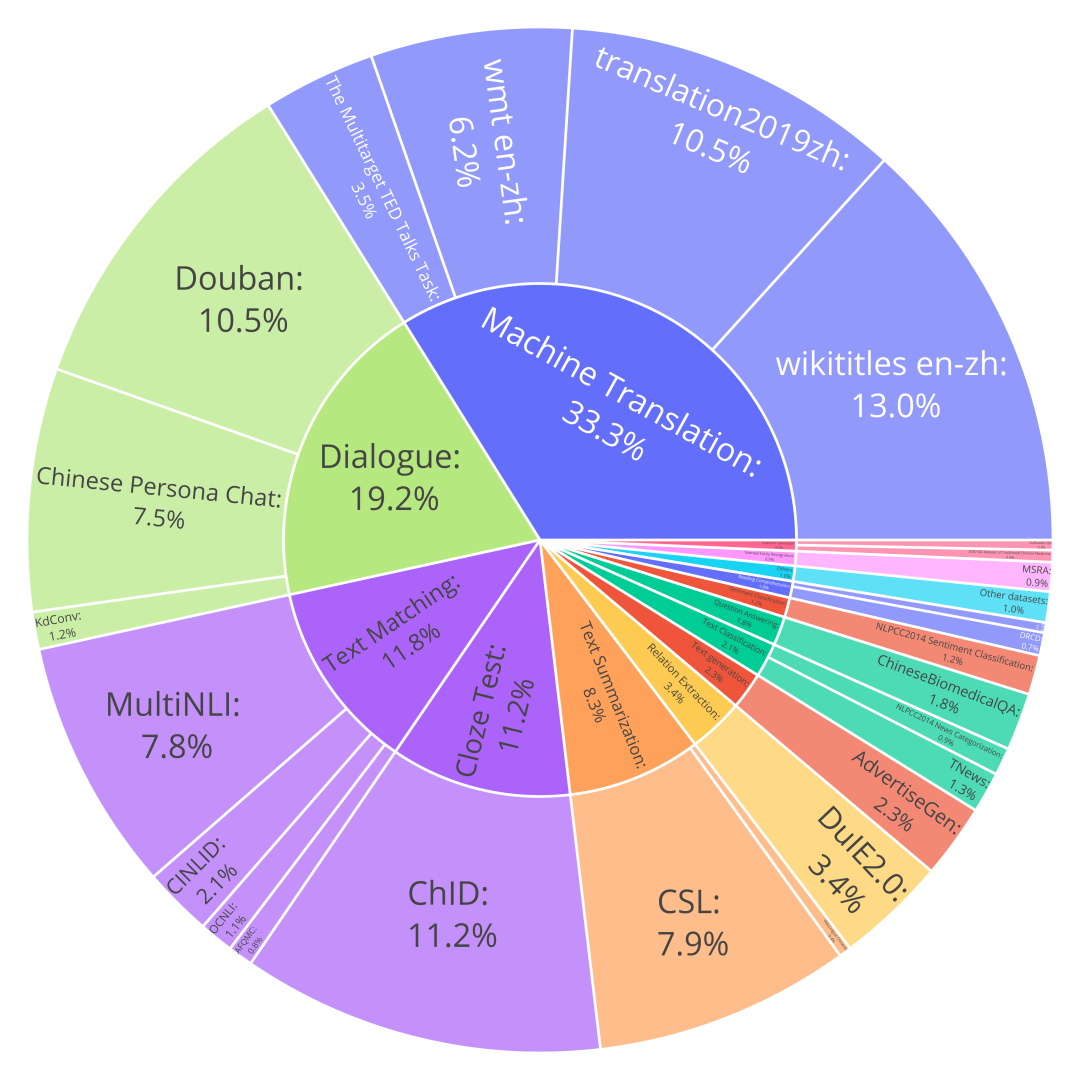
我们选用了The Flan Collection作为英文Flan数据集,而中文Flan数据集则选用了涵盖了44个任务五千万条指令数据,同时完全开放了其构建方法。下面给出了整个双语Flan数据集的分布和具体的中文Flan数据集构成。
非对称Encoder-Decoder模型结构
在模型结构的选择上,OpenBA尝试了三种设置:(1) 更深的decoder,(2) 更深的encoder,(3) 相同层数的encoder和decoder。
论文认为现有的大语言模型主要为decoder-only结构,以生成能力见长,而decoder的层数更深有助于模型生成能力的提升。
针这一点,本文做了一个验证试验,用UL2的训练目标训练上述三种设置的模型,并观察模型在三种denoising验证集上的效果,其中S-Denoising task上的能力可以看作是对模型生成能力的衡量。
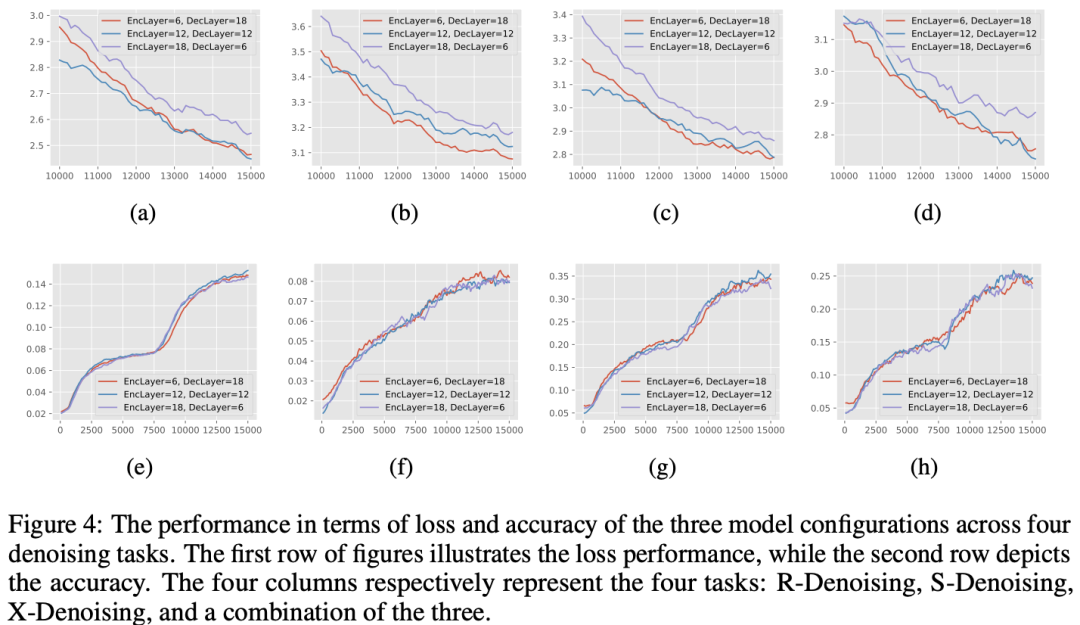
实验结论表明:更深的decoder设置在S-Denoising任务上的能力要更优,这也证实了更深decoder模型在生成任务上的有效性。
融合UL2的三阶段预训练
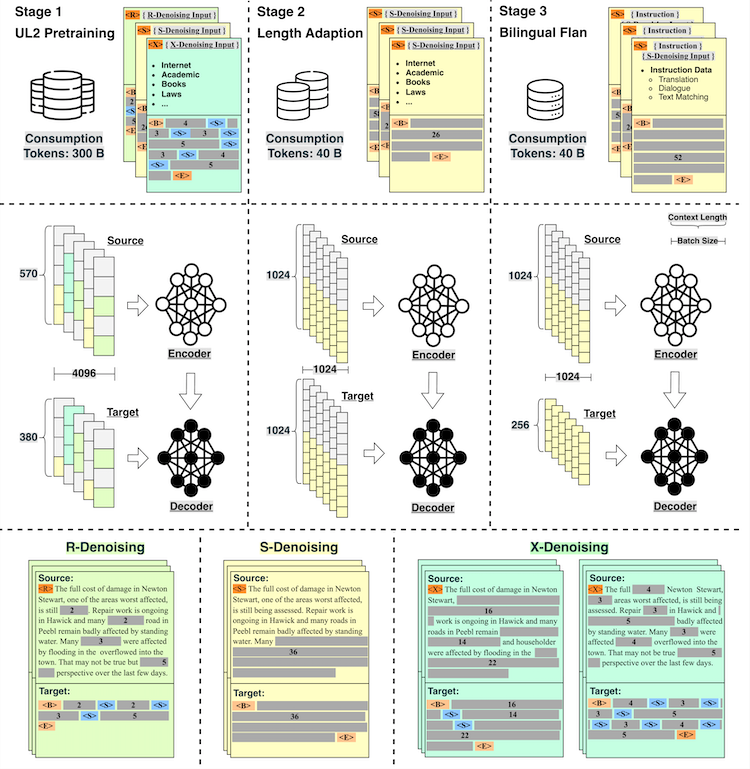
如上图所示,OpenBA经历了三个阶段的预训练,分别是:
UL2 预训练 此阶段主要涉及三个任务:少量随机掩码的R-Denosing,大量随机掩码的X-Denosing,以及序列连续掩码的S-Denosing。
长度适应训练: 在这个阶段,OpenBA将570/380的输入输出最大长度延伸至1024/1024,并仅专注于续写任务。这一步的目的是为了让模型能适应对上下文长度要求更高的下游任务,且进一步增强其生成能力。
双语Flan训练阶段: 在这个阶段,OpenBA在双语Flan数据集上进行了微调,赋予模型更强的遵循指令能力。
实验结果
OpenBA在多个常用中英文Benchmark(MMLU,CMMLU,C-Eval,BBH,SuperGLUE等)以及不同设置下(包括Zero-shot, Few-shot, Held-in, Hold-out)进行了评测,覆盖了常识推理、自然语言生成和自然语言理解等任务。
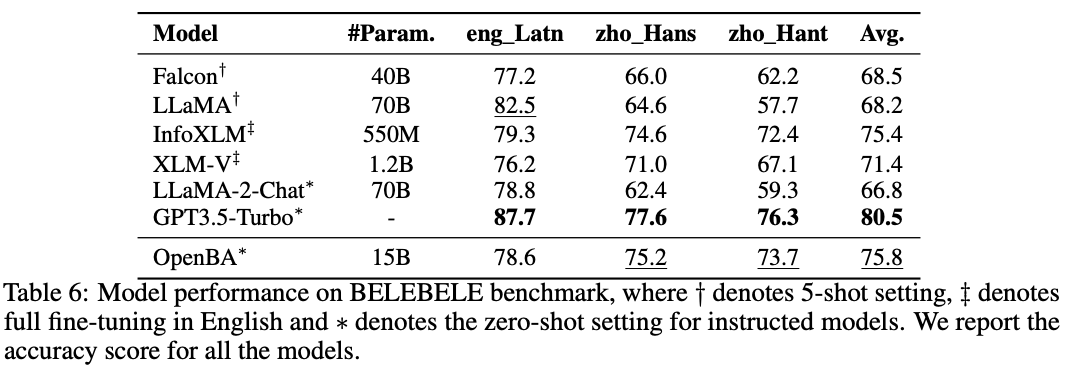
OpenBA在不同任务与设置下均取得了有竞争力的效果。以下为OpenBA在BELEBELE(自然语言理解任务),ROC Story(自然语言生成任务),CMMLU(逻辑推理任务)的部分评测结果。
OpenBA在ROC Story(故事生成)上的人工评测结果:


OpenBA在CMMLU(中文逻辑推理)上的自动指标结果:
小结
尽管OpenBA仅使用了380B tokens,但它在众多benchmarks上均获得了出色的性能,甚至超过了消耗更多数据的模型。苏州大学已开源OpenBA的各阶段checkpoint以及中文Flan数据集的构建方法,以便于广大研究者使用。
OpenBA下一阶段的工作将在通用聊天模型、调用工具模型以及去除偏见与对齐方面进一步深化研究(具体请参考技术报告)。
如果您对OpenBA感兴趣,欢迎合作,一起为开源社区做出贡献。
进NLP群—>加入NLP交流群