焦作百姓网seo关键词优化怎么收费
KPU的基础架构
让我们回顾下经典神经网络的基础运算操作:
卷积(Convolution):1x1卷积,3x3卷积,5x5及更高的卷积
批归一化(Batch Normalization)
激活(Activate)
池化(Pooling)
矩阵运算(Matrix Calculate):矩阵乘,加
对于基础的神经网络结构,仅具备1,2,3,4 四种操作;
对于新型网络结构,比如ResNet,在卷积结果后会加一个变量,就需要使用第五种操作,矩阵运算。
对于MAIX的主控芯片K210来说,它内置实现了 卷积,批归一化,激活,池化 这4钟基础操作的硬件加速,但是没有实现一般的矩阵运算,所以在实现的网络结构上有所限制。
对于需要额外操作的网络结构,用户必须在硬件完成基础操作后,手工插入CPU干预的处理层实现,会导致帧数降低,所以建议用户优化自己的网络结构到基础网络形式。
所幸的是,该芯片的第二代将支持通用矩阵计算,并固化更多类型的网络结构。
在KPU中,上述提到的4种基础操作并非是单独的加速模块,而是合成一体的加速模块,有效避免了CPU干预造成的损耗,但也丧失了一些操作上的灵活性。
从standalone sdk/demo 以及 Model Compiler 中分析出 KPU加速模块的原理框图如下,看图即懂。

#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy/model/face_model_at_0x300000.kfpkg
下载后模型文件夹内有二个文件


打开kflash_gui
使用kfpkg将 二个模型文件 与 maixpy 固件打包下载到 flash

打包kfpkg时出错,好像是文件地址范围不同…

尝试多次一直不行,两者不兼容。后来干脆不打包了,只烧录模型文件kfpkg(原来烧录过MaixPy固件V0.4.0),没想到可以了,这下明白了,固件和模型分开烧录也行。

#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy … l_at_0x300000.kfpkg
#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy ... l_at_0x300000.kfpkgimport sensor
import image
import lcd
import KPU as kpulcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.run(1)
task = kpu.load(0x300000) #使用kfpkg将 kmodel 与 maixpy 固件打包下载到 flash
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
a = kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
while(True):img = sensor.snapshot()code = kpu.run_yolo2(task, img)if code:for i in code:print(i)a = img.draw_rectangle(i.rect())a = lcd.display(img)
a = kpu.deinit(task)

串口输出了大量数据
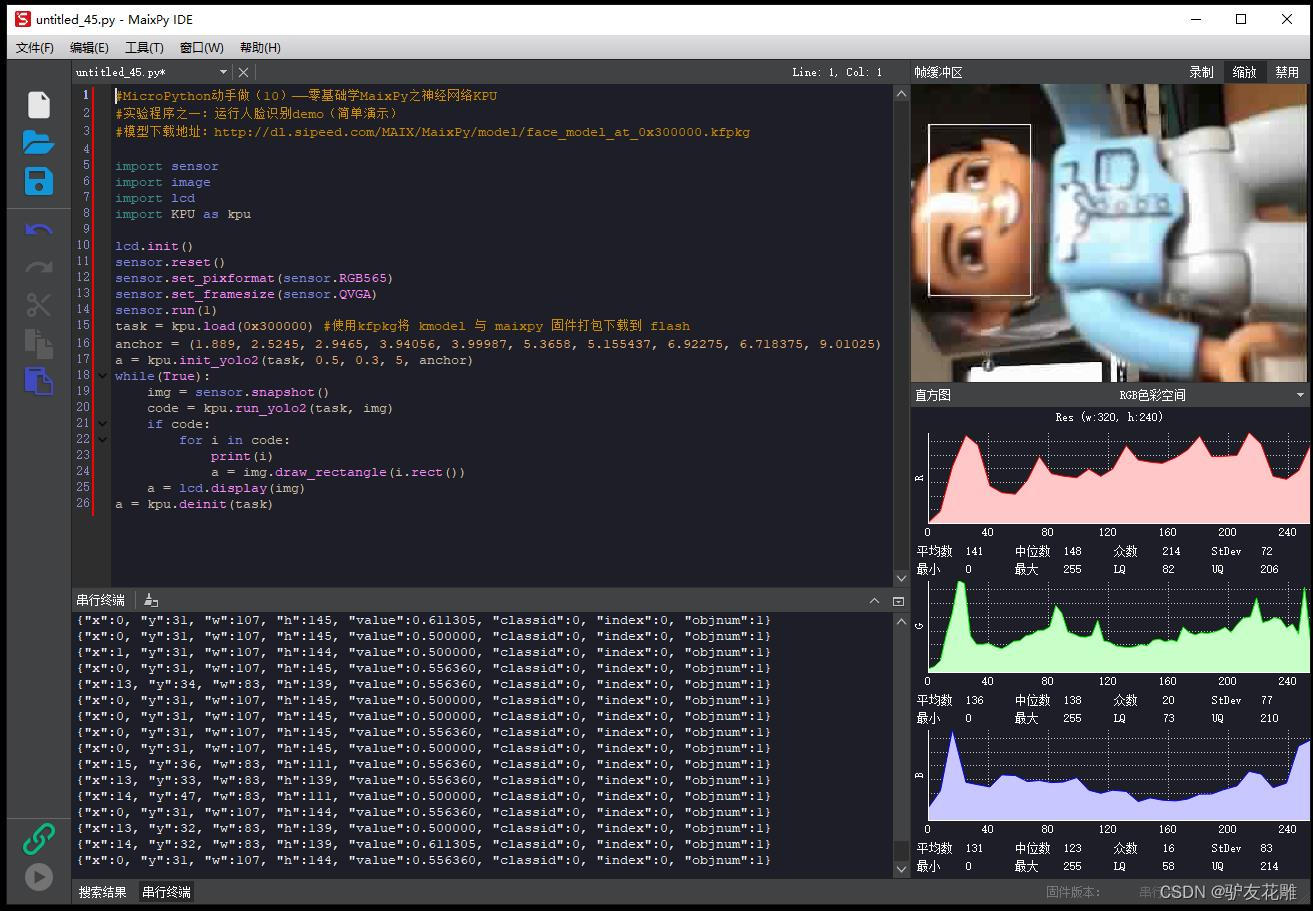
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.611305, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:1, “y”:31, “w”:107, “h”:144, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:34, “w”:83, “h”:139, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:15, “y”:36, “w”:83, “h”:111, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:33, “w”:83, “h”:139, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:14, “y”:47, “w”:83, “h”:111, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:144, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:32, “w”:83, “h”:139, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:14, “y”:32, “w”:83, “h”:139, “value”:0.611305, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:144, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
KPU是通用的神经网络处理器,它可以在低功耗的情况下实现卷积神经网络计算,时时获取被检测目标的大小、坐标和种类,对人脸或者物体进行检测和分类。KPU模块方法:
- 加载模型
从flash或者文件系统中加载模型
import KPU as kpu
task = kpu.load(offset or file_path)
参数
offtset: 模型在 flash 中的偏移大小,如 0xd00000 表示模型烧录在13M起始的地方
file_path: 模型在文件系统中为文件名, 如 “/sd/xxx.kmodel”
返回
kpu_net: kpu 网络对象
- 初始化yolo2网络
为yolo2网络模型传入初始化参数
import KPU as kpu
task = kpu.load(offset or file_path)
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
参数
kpu_net: kpu 网络对象
threshold: 概率阈值
nms_value: box_iou 门限
anchor_num: 锚点数
anchor: 锚点参数与模型参数一致
- 反初始化
import KPU as kpu
task = kpu.load(offset or file_path)
kpu.deinit(task)
参数
kpu_net: kpu_load 返回的 kpu_net 对象
- 运行yolo2网络
import KPU as kpu
import image
task = kpu.load(offset or file_path)
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
img = image.Image()
kpu.run_yolo2(task, img)
参数
kpu_net: kpu_load 返回的 kpu_net 对象
image_t:从 sensor 采集到的图像
返回
list: kpu_yolo2_find 的列表
- 网络前向运算(forward)
计算已加载的网络模型到指定层数,输出目标层的特征图
import KPU as kpu
task = kpu.load(offset or file_path)
……
fmap=kpu.forward(task,img,3)
参数
kpu_net: kpu_net 对象
image_t: 从 sensor 采集到的图像
int: 指定计算到网络的第几层
返回
fmap: 特征图对象,内含当前层所有通道的特征图
- fmap 特征图
取特征图的指定通道数据到image对象
img=kpu.fmap(fmap,1)
参数
fmap: 特征图 对象
int: 指定特征图的通道号】
返回
img_t: 特征图对应通道生成的灰度图
- fmap_free 释放特征图
释放特征图对象
kpu.fmap_free(fmap)
参数
fmap: 特征图 对象
返回
无
- netinfo
获取模型的网络结构信息
info=kpu.netinfo(task)
layer0=info[0]
参数
kpu_net: kpu_net 对象
返回
netinfo list:所有层的信息list, 包含信息为:
index:当前层在网络中的层数
wi:输入宽度
hi:输入高度
wo:输出宽度
ho:输出高度
chi:输入通道数
cho:输出通道数
dw:是否为depth wise layer
kernel_type:卷积核类型,0为1x1, 1为3x3
pool_type:池化类型,0不池化; 1:2x2 max pooling; 2:…
para_size:当前层的卷积参数字节数
KPU寄存器配置说明
芯片厂家没有给出寄存器手册,我们从kpu.c, kpu.h, Model Compiler中分析各寄存器定义。KPU的寄存器配置写在 kpu_layer_argument_t 结构体中,我们取standalone demo中的kpu demo中的gencode.c来分析.(https://github.com/kendryte/kend … pu/gencode_output.c)
//层参数列表,共16层kpu_layer_argument_t la[] __attribute__((aligned(128))) = {
// 第0层{
.kernel_offset.data = {.coef_row_offset = 0, //固定为0.coef_column_offset = 0 //固定为0
},
.image_addr.data = { //图像输入输出地址,一个在前,一个在后,下一层运算的时候翻过来,可以避免拷贝工作。.image_dst_addr = (uint64_t)0x6980, //图像输出地址,int((0 if idx & 1 else (img_ram_size - img_output_size)) / 64).image_src_addr = (uint64_t)0x0 //图像加载地址
},
.kernel_calc_type_cfg.data = {.load_act = 1, //使能激活函数,必须使能(硬件设计如此),不使能则输出全为0.active_addr = 0, //激活参数加载首地址,在kpu_task_init里初始化为激活折线表.row_switch_addr = 0x5, //图像宽占用的单元数,一个单元64Byte. ceil(width/64)=ceil(320/64)=5.channel_switch_addr = 0x4b0, //单通道占用的单元数. row_switch_addr*height=5*240=1200=0x4b0.coef_size = 0, //固定为0.coef_group = 1 //一次可以计算的组数,因为一个单元64字节,//所以宽度>32,设置为1;宽度17~32,设置为2;宽度<=16,设置为4
},
.interrupt_enabe.data = {.depth_wise_layer = 0, //常规卷积层,设置为0.ram_flag = 0, //固定为0.int_en = 0, //失能中断.full_add = 0 //固定为0
},
.dma_parameter.data = { //DMA传输参数.dma_total_byte = 307199, //该层输出16通道,即 19200*16=308200.send_data_out = 0, //使能输出数据.channel_byte_num = 19199 //输出单通道的字节数,因为后面是2x2 pooling, 所以大小为160*120=19200
},
.conv_value.data = { //卷积参数,y = (x*arg_x)>>shr_x.arg_x = 0x809179, //24bit 乘法参数.arg_w = 0x0,.shr_x = 8, //4bit 移位参数.shr_w = 0
},
.conv_value2.data = { //arg_add = kernel_size * kernel_size * bw_div_sw * bx_div_sx =3x3x?x?.arg_add = 0
},
.write_back_cfg.data = { //写回配置.wb_row_switch_addr = 0x3, //ceil(160/64)=3.wb_channel_switch_addr = 0x168, //120*3=360=0x168.wb_group = 1 //输入行宽>32,设置为1
},
.image_size.data = { //输入320*240,输出160*120.o_col_high = 0x77,.i_col_high = 0xef,.i_row_wid = 0x13f,.o_row_wid = 0x9f
},
.kernel_pool_type_cfg.data = {.bypass_conv = 0, //硬件不能跳过卷积,固定为0.pad_value = 0x0, //边界填充0.load_para = 1, //硬件不能跳过归一化,固定为1.pad_type = 0, //使用填充值.kernel_type = 1, //3x3设置为1, 1x1设置为0.pool_type = 1, //池化类型,步长为2的2x2 max pooling.dma_burst_size = 15, //dma突发传送大小,16字节;脚本中固定为16.bwsx_base_addr = 0, //批归一化首地址,在kpu_task_init中初始化.first_stride = 0 //图像高度不超过255;图像高度最大为512。
},
.image_channel_num.data = {.o_ch_num_coef = 0xf, //一次性参数加载可计算的通道数,16通道。4K/单通道卷积核数//o_ch_num_coef = math.floor(weight_buffer_size / o_ch_weights_size_pad) .i_ch_num = 0x2, //输入通道,3通道 RGB.o_ch_num = 0xf //输出通道,16通道
},
.kernel_load_cfg.data = {.load_time = 0, //卷积加载次数,不超过72KB,只加载一次.para_size = 864, //卷积参数大小864字节,864=3(RGB)*9(3x3)*2*16.para_start_addr = 0, //起始地址.load_coor = 1 //允许加载卷积参数
}
},//第0层参数结束……
};上表中还有些结构体内容没有填充,是在KPU初始化函数中填充:```kpu_task_t* kpu_task_init(kpu_task_t* task){
la[0].kernel_pool_type_cfg.data.bwsx_base_addr = (uint64_t)&bwsx_base_addr_0; //初始化批归一化表
la[0].kernel_calc_type_cfg.data.active_addr = (uint64_t)&active_addr_0; //初始化激活表
la[0].kernel_load_cfg.data.para_start_addr = (uint64_t)¶_start_addr_0; //初始化参数加载
…… //共16层参数,逐层计算
task->layers = la;
task->layers_length = sizeof(la)/sizeof(la[0]); //16层
task->eight_bit_mode = 0; //16bit模式
task->output_scale = 0.12349300010531557; //输出的缩放,偏置
task->output_bias = -13.528212547302246;
return task;
}```