百度站长平台快速收录怎么弄广告免费推广网
大模型使用——超算上部署LLAMA-2-70B-Chat
前言
1、本机为Inspiron 5005,为64位,所用操作系统为Windos 10。超算的操作系统为基于Centos的linux,GPU配置为A100,所使用开发环境为Anaconda。
2、本教程主要实现了在超算上部署LLAMA2-70B-Chat。
实现步骤
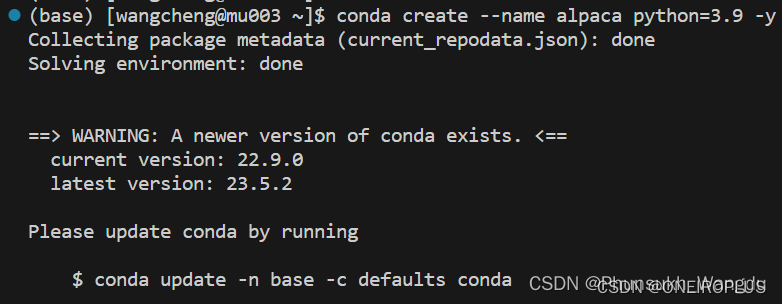
1、连接上超算以后,执行如下命令在超算上创建一个虚拟环境。
conda create --name alpaca python=3.9 -y
2、运行如下命令激活虚拟环境。
conda activate alpaca

3、在到LLAMA2的Github地址下载好llama2项目。
4、将下载好llama2项目的文件通过自己windows上的cmd中输入scp指令传输到超算上。
scp -r E:\llama-main wangcheng@10.26.14.56:/public/home/wangcheng/


5、在超算上进入llama-main文件夹,然后输入如下命令安装稳定版的llama2运行的依赖。
cd llama-main
pip install -e .

6、在Meta申请LLAMA2使用的链接地址上填写资料,然后申请LLAMA2模型的下载链接,申请完毕可以得到一份邮件,邮件中包含了下载链接。
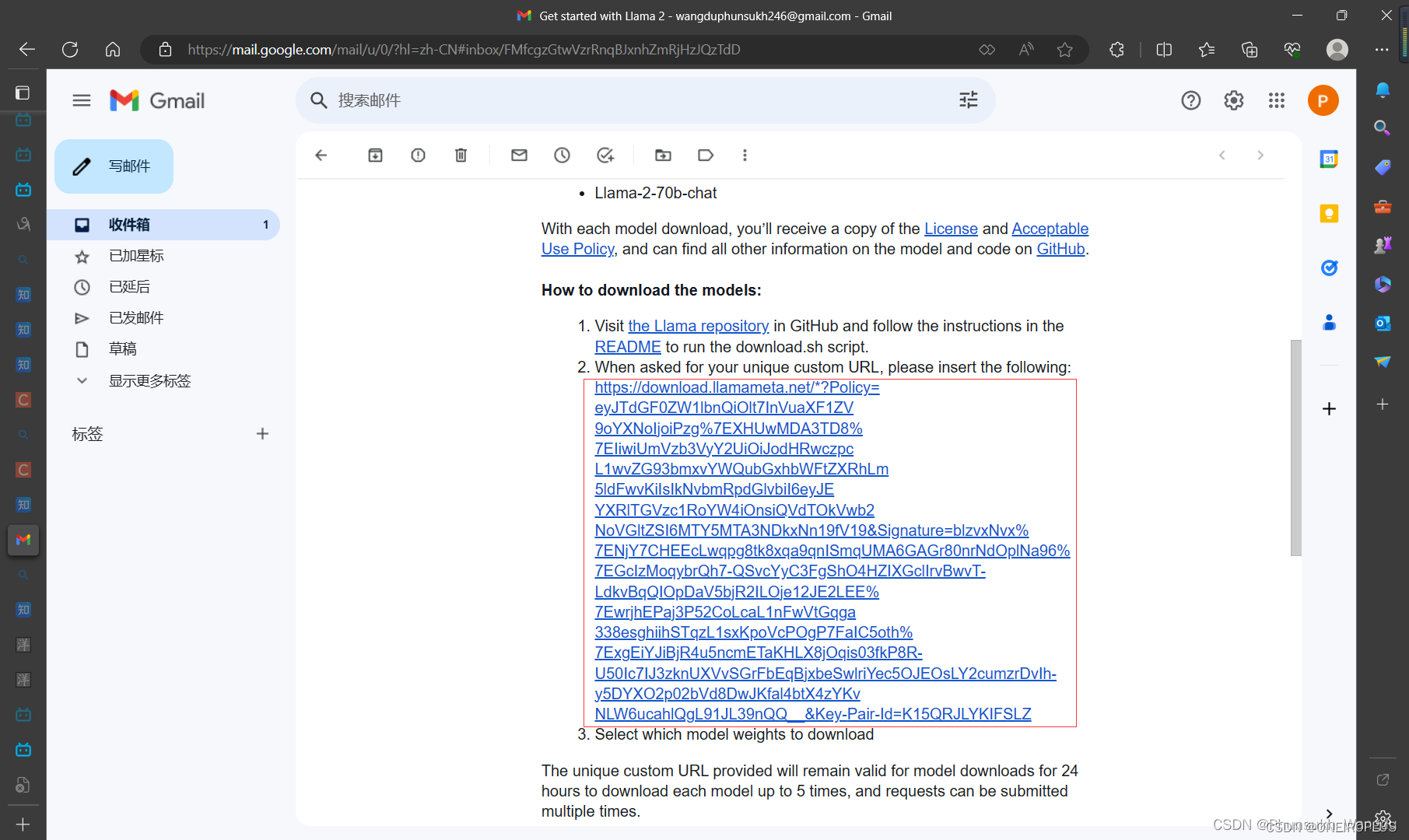
7、在超算的llama-main目录下使用如下指令开始下载模型,在下载模型开始时,会要求你输入下载链接,第二步会让你选择要下载的模型,你选好要下载的模型以后,程序便会自己进行下载,整个过程时间比较长,在模型下载完毕后会自己先进行一步模型文件下载是否完整的校验,若你要自己进行一下文件的校验,可以使用如下所示的第二条指令,第二条指令双引号中的内容在下载的模型文件夹中包含的checklist.chk文件中找到,然后进行替换校验即可。
bash download.sh
echo "6efc8dab194ab59e49cd24be5574d85e consolidated.00.pth" | md5sum --check -

8、模型下载完毕后,通过如下指令将自己创建的llama_test.sh文件进行超算的使用调度。(注:llama_test.sh文件中的代码如下:)
sbatch llama_test.sh
#!/bin/bash
#SBATCH --job-name=llama_job_test
#SBATCH --output=testLLAMAJob.%j.out
#SBATCH --error=testLLAMAJob.%j.err
#SBATCH --partition=GPU_s
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:8starttime=`date +'%Y-%m-%d %H:%M:%S'` # 执行data命令,获取当前的日期和时间的格式化表示,并赋值给starttime
nvidia-smi # 查看NVIDIA GPU的状态和性能信息,输出当前节点上GPU的状态信息
echo "CUDA_VISIBLE_DEVICES = $CUDA_VISIBLE_DEVICES" # 输出当前进程中 CUDA_VISIBLE_DEVICES 的值,echo 命令用于输出字符串source ~/.bashrc # 于重新加载用户的 Bash 配置文件 ~/.bashrc,确保在后续的命令中可以使用最新的环境变量和别名设置
hostname >./hostfile # 获取当前主机的名称,并将其输出到一个名为 hostfile 的文件中echo $SLURM_NTASKS # 输出当前作业中分配的任务数
echo "Date = $(date)" # 输出当前的日期和时间
echo "Hostname = $(hostname -s)" # 输出当前主机的名称
echo "Working Directory = $(pwd)" # 输出当前工作目录的路径
echo "" # 输出一个空行,使易于阅读
echo "Number of Nodes Allocated = $SLURM_JOB_NUM_NODES" # 输出作业节点
echo "Number of Tasks Allocated = $SLURM_NTASKS" # 输出当前作业分配的任务数
echo "Number of Cores/Task Allocated = $SLURM_CPUS_PER_TASK" # 输出每个任务被分配的CPU核心数
echo $SLURM_NPROCS # 输出当前作业中分配的处理器数ulimit -s unlimited # 设置当前shell会话的栈大小限制为无限制
ulimit -v unlimited # 设置当前shell会话的虚拟内存限制为无限制,即不限制进程使用的虚拟内存大小
ulimit -m unlimited # 设置当前shell会话的物理内存限制为无限制module load cuda/11.7 # 加载11.7版本的CUDA软件模块
module load gcc/12.1 # 加载12.1的GCC编译器的软件模块
module load torch/2.0.1 # 加载2.0.1版本的torch# module load cuda/11.6 # 加载11.6版本的CUDA软件模块
# module load gcc/12.1 # 加载12.1的GCC编译器的软件模块
# module load torch/2.0 # 加载2.0版本的torchsource activate alpaca # 激活名为 alpaca 的Python虚拟环境python -V # 显示当前系统上安装的Python版本号
echo "CUDA_VISIBLE_DEVICES = $CUDA_VISIBLE_DEVICES" # 输出当前作业可以使用的CUDA设备的ID列表
echo "CONDA_DEFAULT_ENV = $CONDA_DEFAULT_ENV" # 输出当前工作的conda虚拟环境
# conda list # 列出当前conda环境下安装的python包# export MASTER_ADDR=localhost
# export MASTER_PORT=8888
# export WORLD_SIZE=8
# export NODE_RANK=0
# export OMP_NUM_THREADS=9# 使用torchrun进行分布式部署
# torchrun --nproc_per_node 8 example_chat_completion.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
torchrun --nproc_per_node 8 chat.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# python chat.py --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# python -m torch.distributed.launch --nproc_per_node=8 chat.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
nvidia-smi echo Job ends at `date` # 输出当前的日期
endtime=`date +'%Y-%m-%d %H:%M:%S'` # 执行data命令,获取当前的日期和时间的格式化表示,并赋值给endtime
start_seconds=$(date --date="$starttime" +%s); # 将开始时间转换为秒数
end_seconds=$(date --date="$endtime" +%s); # 将结束时间转换为秒数
echo "本次运行时间: "$((end_seconds-start_seconds))"s" # 输出字符串,得到当前任务
10、在得到的输出文件testLLAMAJob.389396.out中可以看到llama2成功部署到超算上了。
Remark:实行部署笔记纸质档
