做文化建设的网站有什么软件可以推广
原文地址:https://pub.towardsai.net/advanced-rag-04-re-ranking-85f6ae8170b1
2024 年 2 月 14 日
重新排序在检索增强生成(RAG)过程中起着至关重要的作用。在简单的 RAG 方法中,可以检索大量上下文,但并非所有上下文都一定与问题相关。重新排序允许对文档进行重新排序和过滤,将相关文档置于最前面,从而提高 RAG 的有效性。
本文介绍了 RAG 的重新排名技术,并演示了如何使用两种方法合并重新排名功能。
重新排序(Re-ranking)简介
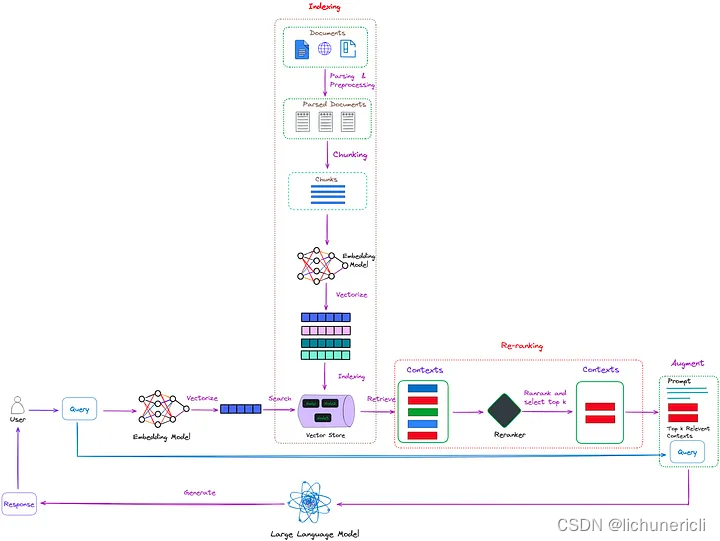 图 1:RAG 中的重新排序,重新排序的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确且相关答案的上下文(红色框)。
图 1:RAG 中的重新排序,重新排序的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确且相关答案的上下文(红色框)。
如图1所示,重新排序的任务就像一个智能过滤器。当检索器从索引集合中检索多个上下文时,这些上下文可能与用户的查询具有不同的相关性。有些上下文可能非常相关(在图 1 中以红色框突出显示),而另一些上下文可能只是轻微相关甚至不相关(在图 1 中以绿色和蓝色框突出显示)。
重新排名的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确且相关答案的上下文。这使得LLMs能够在生成答案时优先考虑这些排名靠前的上下文,从而提高响应的准确性和质量。
简单来说,重新排名就像开卷考试时帮助你从一堆学习材料中选择最相关的参考文献,以便你更高效、更准确地回答问题。
本文介绍的重排序方法主要可以分为以下两种:
- 重新排序模型:这些模型考虑文档和查询之间的交互特征,以更准确地评估它们的相关性。
- LLM:LLM的出现为重新排名开辟了新的可能性。通过彻底理解整个文档和查询,可以更全面地捕获语义信息。
使用重新排序模型作为重排器
重新排序模型与嵌入模型不同,它将查询和上下文作为输入,直接输出相似性得分而不是嵌入得分。值得注意的是,重新排序模型是利用交叉熵损失进行优化的,因此相关性得分不局限于特定范围,甚至可以是负分。
目前,可用的重新排序模型并不多。一种选择是 Cohere 提供的在线模型,可以通过 API 访问。此外,还有一些开源模型,如 bge-reranker-base 和 bge-reranker-large 等。
图 2 显示了使用命中率(Hit Rate)和平均倒数排名(Mean Reciprocal Rank,MRR)指标的评估结果:

从评估结果可以看出:
- 无论使用哪种嵌入模型,重新排序都能显示出更高的命中率和 MRR,这表明重新排序具有重大影响。
- 目前,最好的重新排名模型是 Cohere,但它是一项付费服务。开源的 bge-reranker-large 模型具有与 Cohere 相似的功能。
- 嵌入模型和重新排序模型的组合也会产生影响,因此开发人员可能需要在实际过程中尝试不同的组合。
本文将使用 bge-reranker-base 模型。
环境配置
导入相关库,设置环境变量和全局变量
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.schema import QueryBundledir_path = "YOUR_DIR_PATH"
目录中只有一个 PDF 文件,即 "TinyLlama: An Open Source Small Language Model"。
(py) Florian:~ Florian$ ls /Users/Florian/Downloads/pdf_test/ tinyllama.pdf
使用 LlamaIndex 构建一个简单的检索器
documents = SimpleDirectoryReader(dir_path).load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k = 3)
基本检索
query = "Can you provide a concise description of the TinyLlama model?"
nodes = retriever.retrieve(query)
for node in nodes:print('----------------------------------------------------')display_source_node(node, source_length = 500)
display_source_node 函数改编自 llama_index 源代码。原始函数是为 Jupyter notebook 设计的,因此修改如下:
from llama_index.schema import ImageNode, MetadataMode, NodeWithScore
from llama_index.utils import truncate_textdef display_source_node(source_node: NodeWithScore,source_length: int = 100,show_source_metadata: bool = False,metadata_mode: MetadataMode = MetadataMode.NONE,
) -> None:"""Display source node"""source_text_fmt = truncate_text(source_node.node.get_content(metadata_mode=metadata_mode).strip(), source_length)text_md = (f"Node ID: {source_node.node.node_id} \n"f"Score: {source_node.score} \n"f"Text: {source_text_fmt} \n")if show_source_metadata:text_md += f"Metadata: {source_node.node.metadata} \n"if isinstance(source_node.node, ImageNode):text_md += "Image:"print(text_md)# display(Markdown(text_md))# if isinstance(source_node.node, ImageNode) and source_node.node.image is not None:# display_image(source_node.node.image)
基本检索结果如下,表示重新排序前的前 3 个节点:
----------------------------------------------------
Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662
Score: 0.8706055408845863
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w... ----------------------------------------------------
Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6
Score: 0.8624531691777889
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr... ----------------------------------------------------
Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f
Score: 0.8346160605298356
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens...
重新排序
要对上述节点重新排序,请使用 bge-reranker-base 模型。
print('------------------------------------------------------------------------------------------------')
print('Start reranking...')reranker = FlagEmbeddingReranker(top_n = 3,model = "BAAI/bge-reranker-base",
)query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:print('----------------------------------------------------')display_source_node(ranked_node, source_length = 500)
重新排序后的结果如下:
------------------------------------------------------------------------------------------------
Start reranking...
----------------------------------------------------
Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6
Score: -1.584416151046753
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr... ----------------------------------------------------
Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f
Score: -1.7028117179870605
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens... ----------------------------------------------------
Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662
Score: -2.904750347137451
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
很明显,经过重新排序后,ID 为 ca4db90f-5c6e-47d5-a544-05a9a1d09bc6 的节点的排名从 2 变为 1,这意味着最相关的上下文被排在了第一位。
使用 LLM 作为重排器
现有的涉及 LLM 的重新排序方法大致可分为三类:利用重新排序任务对 LLM 进行微调、提示 LLM 进行重新排序以及在训练过程中使用 LLM 进行数据增强。
提示 LLM 重新排序的方法成本较低。下面是使用 RankGPT 进行的演示,它已被集成到 LlamaIndex 中。
RankGPT 的理念是使用 LLM(如 ChatGPT 或 GPT-4 或其他 LLM)执行零样本列表式段落重新排序。它采用排列生成方法和滑动窗口策略来有效地对段落重新排序。
如图 3 所示,本文提出了三种可行的方法。

前两种方法是传统方法,即给每篇文档打分,然后根据分数对所有段落进行排序。
本文提出了第三种方法,即排列生成法。具体来说,该模型不依赖外部评分,而是直接对段落进行端到端排序。换句话说,它直接利用 LLM 的语义理解能力对所有候选段落进行相关性排序。
然而,候选文档的数量通常非常大,而 LLM 的输入却很有限。因此,通常无法一次性输入所有文本。
因此,如图 4 所示,我们引入了一种滑动窗口法,它沿用了冒泡排序的思想。每次只对前 4 个文本进行排序,然后移动窗口,对后面 4 个文本进行排序。在对整个文本进行反复排序后,我们就可以得到性能最好的文本。
请注意,要使用 RankGPT,您需要安装较新版本的 LlamaIndex。我之前安装的版本(0.9.29)不包含 RankGPT 所需的代码。因此,我用 LlamaIndex 0.9.45.post1 版本创建了一个新的 conda 环境。
代码非常简单,基于上一节的代码,只需将 RankGPT 设置为重选器即可。
from llama_index.postprocessor import RankGPTRerank
from llama_index.llms import OpenAI
reranker = RankGPTRerank(top_n = 3,llm = OpenAI(model="gpt-3.5-turbo-16k"),# verbose=True,
)
总体结果如下:
(llamaindex_new) Florian:~ Florian$ python /Users/Florian/Documents/rerank.py
----------------------------------------------------
Node ID: 20de8234-a668-442d-8495-d39b156b44bb
Score: 0.8703492815379594
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w... ----------------------------------------------------
Node ID: 47ba3955-c6f8-4f28-a3db-f3222b3a09cd
Score: 0.8621633467539512
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr... ----------------------------------------------------
Node ID: 17cd9896-473c-47e0-8419-16b4ac615a59
Score: 0.8343984516104476
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens... ------------------------------------------------------------------------------------------------
Start reranking...
----------------------------------------------------
Node ID: 47ba3955-c6f8-4f28-a3db-f3222b3a09cd
Score: 0.8621633467539512
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr... ----------------------------------------------------
Node ID: 17cd9896-473c-47e0-8419-16b4ac615a59
Score: 0.8343984516104476
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens... ----------------------------------------------------
Node ID: 20de8234-a668-442d-8495-d39b156b44bb
Score: 0.8703492815379594
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
请注意,由于使用了 LLM,重新排序后的分数并未更新。当然,这并不重要。
从结果可以看出,经过重新排序后,排在第一位的结果是包含答案的正确文本,这与前面使用重新排序模型得出的结果一致。
评估
reranker = FlagEmbeddingReranker(top_n = 3,model = "BAAI/bge-reranker-base",use_fp16 = False
)# or using LLM as reranker
# from llama_index.postprocessor import RankGPTRerank
# from llama_index.llms import OpenAI
# reranker = RankGPTRerank(
# top_n = 3,
# llm = OpenAI(model="gpt-3.5-turbo-16k"),
# # verbose=True,
# )query_engine = index.as_query_engine( # add reranker to query_enginesimilarity_top_k = 3, node_postprocessors=[reranker]
)
# query_engine = index.as_query_engine() # original query_engine
参考:https://ai.plainenglish.io/advanced-rag-03-using-ragas-llamaindex-for-rag-evaluation-84756b82dca7
结论
总之,本文介绍了重新排序的原则和两种主流方法。
另一方面,使用 LLM 的方法在多个基准测试中表现良好,但成本较高,而且仅在使用 ChatGPT 和 GPT-4 时表现良好,而在使用 FLAN-T5 和 Vicuna-13B 等其他开源模型时表现不佳。