做设计最好的参考网站添加友情链接的技巧
(1)cifar10数据集预处理
CIFAR-10是一个广泛使用的图像数据集,它由10个类别的共60000张32x32彩色图像组成,每个类别有6000张图像。
CIFAR-10官网
以下为CIFAR-10数据集data_batch_*表示训练集数据,test_batch表示测试集数据
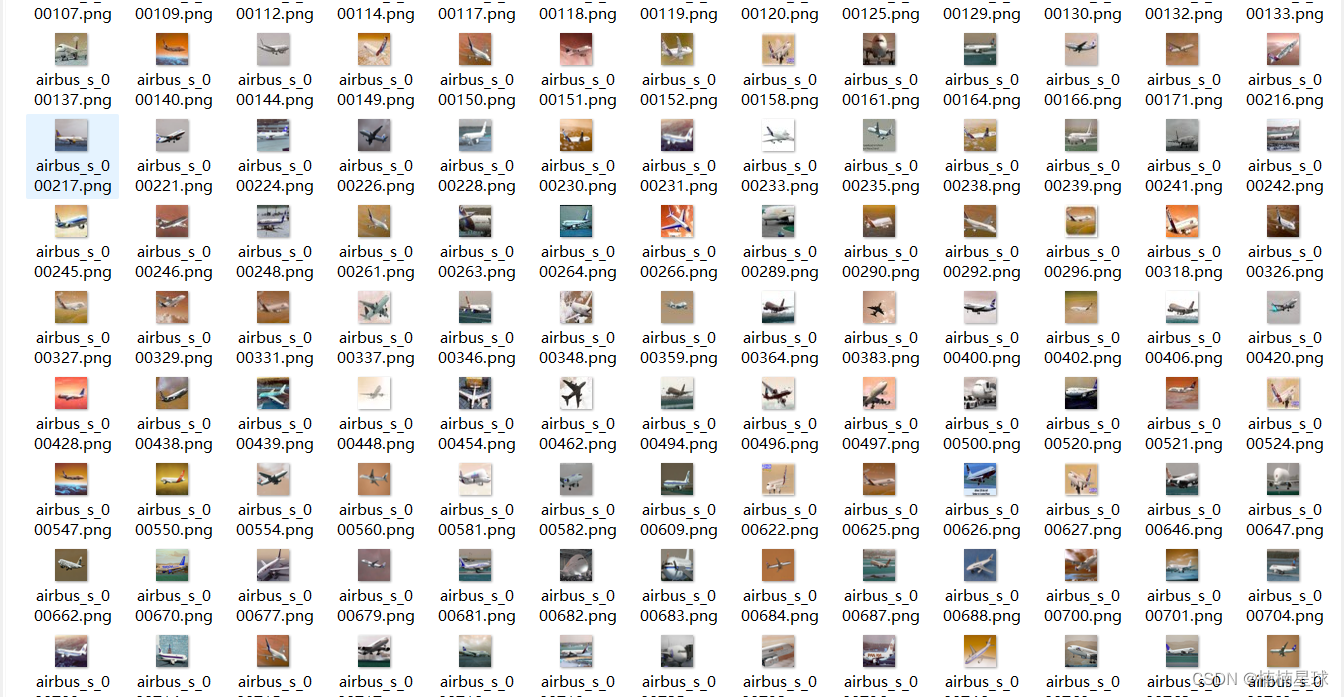
预处理结果(将CIFAR-10保存为图片格式)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: LIFEI
@time: 2024/5/8 15:00
@file: 加载cifar10数据.py
@project: 深度学习(4):深度神经网络(DNN)
@describe: TEXT
@# ------------------------------------------(one)--------------------------------------
@# ------------------------------------------(two)--------------------------------------
"""
import glob
import pickle
import numpy as np
import cv2 as
import os
#%% md
cifar10官网处理函数:
#%%
def unpickle(file):with open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
#%% md
利用上面的函数进行读取数据:
#%%
label = ["airplane","automobile", "bird","cat", 'deer',"dog","frog","horse","ship","truck"] #标签矩阵
filepath = glob.glob("../../test_doucments/cifar-10-batches-py/data_batch_*") # 获取当前文件的路径,返回路径矩阵,获取test数据集时将data_batch——*改为test_batch*
write_path =["./train","./test"] #
print(filepath)
for file in filepath:if not file:print("空集出错")else:# print(file)data_dic = unpickle(file) # 将二进制表示形式转换回 Python 对象的反序列化过程,结果为字节型数据# print(data_dic.keys()) #此处的keys主要有b"data",b"labels",b"filenames"index = 0for im_data in data_dic[b"data"]: # 遍历影像矩阵数据im_label = data_dic[b"labels"][index] # 赋值标签数据im_filename = data_dic[b"filenames"][index] # 赋值影像名字index +=1# print(f"图像的文件名为:{im_filename}\n",f"图像的所属标签为:{im_label}\n",f"图像的矩阵数据为:{im_data}\n")#开始存放数据im_label_name = label[im_label]im_data_data = np.reshape(im_data,(3,32,32)) # 将影像矩阵数据转换为图像形式# 由于需要opencv进行写出图像,因此需要转化通道im_data_data = np.transpose(im_data_data,(1,2,0))imgname = f"当前图像名称{im_label},所属标签{im_label_name}"cv.imshow(str( im_label_name),cv.resize(im_data_data,(500,500))) # 将显示时的图像变大,图像数据本身大小不变cv.waitKey(0)cv.destroyAllWindows()#创建文件夹for path in write_path:if not os.path.exists("{}/{}".format(path,im_label_name)): #查看存储路径中的文件夹是否存在os.mkdir("{}/{}".format(path,im_label_name)) # 没有就创建文件else:breakcv.imwrite("{}/{}/{}".format(write_path[0],im_label_name,str(im_filename,'utf-8')),im_data_data)# #write_path[1]写出测试数据的时候将write_path[0]改为write_path[1]
#%% md
将cifar10数据转为图片格式并保存
(2)利用pytorch将图像转为张量数据
或是批量读取训练集和测试集数据

#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: LIFEI
@time: 2024/5/8 15:00
@file: 加载cifar10数据.py
@project: 深度学习(4):深度神经网络(DNN)
@describe: TEXT
@# ------------------------------------------(one)--------------------------------------
@# ------------------------------------------(two)--------------------------------------
"""
# 导入库
import glob
from torchvision import transforms
from torch.utils.data import Dataset,DataLoader
import cv2 as cv
# DataLoader参考网址https://blog.csdn.net/sazass/article/details/116641511from PIL import Imagelabel_name = ["airplane","automobile", "bird","cat", 'deer',"dog","frog","horse","ship","truck"]
label_list = {} # 创建一个字典用于存储标签和下标
index = 0
for name in label_name: # 也可以采用for index,name in enumerate(label_name)label_list[name] = index # 字典的常规赋值操作index += 1def default_loder(path):# return Image.open(path).convert("RGB") # 也可采用opencv读取img = cv.imread(path)return cv.cvtColor(img,cv.COLOR_BGR2RGB)# 定义训练集数据的增强 下面的Compose表示拼接需要增强的操作
train_transform = transforms.Compose([transforms.RandomCrop(28,28), #进行随机裁剪为28*28大小transforms.RandomHorizontalFlip(), #垂直方向翻转transforms.RandomVerticalFlip(), #水平方向的翻转transforms.RandomRotation(90), #随机旋转90度transforms.RandomGrayscale(0.1), #灰度转化transforms.ColorJitter(0.3,0.3,0.3,0.3), #随机颜色增强transforms.ToTensor() #将数据转化为张量数据
])# 定义pytorh的dataset类
class MyData(Dataset):def __init__(self,im_list,transform = None,loder = default_loder): #初始化函数super(MyData,self).__init__() #初始化这个类# 获取图片的路径以及标签号images = []for item_data in im_list:# 注意下面这一步,split("\\")根据不同的操作系统会不相同,有的是"/"img_label_name = item_data.split("\\")[-2] #通过遍历每一个路径进行获取当前图片的文字标签images.append([item_data,label_list[img_label_name]])self.images = imagesself.tranform =transformself.loder = loderdef __getitem__(self, index_num): # 此处的index_num是在训练的时候反复传进来的值img_path , img_label = self.images[index_num] #这里的img_data = self.loder(img_path) # 这里用到了self.loder(path)==>default_loder(path)外置函数if self.tranform is not None: # 判断数据是否增强img_data = self.tranform(img_data)return img_data,img_labeldef __len__(self):return len(self.images)train_list = glob.glob("./train/*/*.png") # glob.glob 获取改路径下的所有文件路径并返回为列表
test_list = glob.glob("./test/*/*.png")train_dataset = MyData(train_list,transform = train_transform)
test_dataset = MyData(test_list,transform = transforms.ToTensor()) #测试集无需进行图像增强操作,直接转为张量train_data_loder = DataLoader(dataset =train_dataset,batch_size=6,shuffle=True,num_workers=4)
test_data_loder = DataLoader(dataset =test_dataset,batch_size=6,shuffle=False,num_workers=4)
print(f"训练集的大小:{len(train_dataset)}")
print(f"测试集的大小:{len(test_dataset)}")注:以上代码非原创,仅供个人记录学习笔记,若有侵权,请我联系删除