蛇口做网站谷歌推广新手教程
文章目录
- Overview 概述
- Goal 目标
- Evaluation 评估标准
- Dataset Description 数据集说明
- Dataset Source 数据集来源
- Dataset Fields 数据集字段
- Data Analysis and Visualization 数据分析与可视化
- Correlation 相关性
- Hierarchial Clustering 分层聚类
- Adversarial Validation 对抗验证
- Target 目标
- Model 模型
- Vote 投票
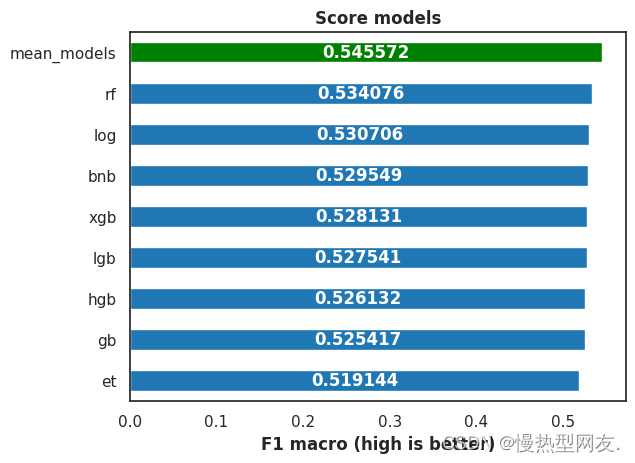
- Score Models 模型评分
Overview 概述
ML Olympiad - Predicting Earthquake Damage是一个由Kaggle和DrivenData合作举办的比赛,旨在通过机器学习算法来预测尼泊尔地震后房屋的损坏程度。这个比赛提供了一个数据集,其中包含了尼泊尔地震期间房屋的各种特征信息,以及每个房屋的损坏程度标签。
参赛者需要利用提供的数据集构建一个模型,通过分析房屋的特征信息来预测房屋的损坏程度。挑战在于需要处理大量的结构化数据,并建立一个高效的预测模型。参赛者可以使用各种机器学习算法、特征工程技巧和模型调优方法来提高他们的预测准确性。

Goal 目标
该比赛的目标是帮助相关组织和机构更好地了解地震对房屋造成的破坏程度,从而提前做好灾害应对和救援准备。通过参与这个比赛,参赛者不仅可以提升他们的机器学习建模能力,还可以为社会做出积极的贡献。
Evaluation 评估标准
macro F score,也称为macro-averaged F1 score,是用于评估多类分类模型性能的指标。它代表了所有类别的平均F1分数,将每个类别视为相等,而不考虑其大小或重要性。
Dataset Description 数据集说明
Dataset Source 数据集来源
本次比赛的合成数据是根据 Richter’s Predictor:Modeling Earthquake Damage 创建的,包含2015年廓尔喀地震建筑位置和施工细节的数据集。这些数据是通过Kathmandu生活实验室和尼泊尔国家计划委员会秘书处下属的中央统计局的调查收集的。这项调查是有史以来收集到的最大灾后数据集之一,包含有关地震影响、家庭状况和社会经济人口统计数据的宝贵信息。文件包括:
train.csv:训练数据集。该数据集包含了4000行和 36 列。
test.csv:测试数据集。与训练数据集类似,该数据集包括 1000 行和 35 列。
sampleSubmission.csv: 示例提交文件。该文件是由最后生成的实际预测结果导出的表格。

Dataset Fields 数据集字段
此处以train.csv为例,描述数据集中的字段及其含义:
| 字段 | 含义 |
|---|---|
| building_id | 建筑物ID |
| count_floors_pre_eq | 地震前楼层数 |
| age | 建筑物年龄 |
| area_percentage | 地块占比 |
| height_percentage | 高度占比 |
| land_surface_condition | 土地表面条件 |
| foundation_type | 基础类型 |
| roof_type | 屋顶类型 |
| ground_floor_type | 底层类型 |
| other_floor_type | 其他楼层类型 |
| position | 位置 |
| plan_configuration | 平面配置 |
| has_superstructure_adobe_mud | 是否有土坯结构 |
| has_superstructure_mud_mortar_stone | 是否有泥砂砂浆石结构 |
| has_superstructure_stone_flag | 是否有石质结构标志 |
| has_superstructure_cement_mortar_stone | 是否有水泥砂砂浆石结构 |
| has_superstructure_mud_mortar_brick | 是否有泥砂砂浆砖结构 |
| has_superstructure_cement_mortar_brick | 是否有水泥砂砂浆砖结构 |
| has_superstructure_timber | 是否有木结构 |
| has_superstructure_bamboo | 是否有竹结构 |
| has_superstructure_rc_non_engineered | 是否有非工程钢筋混凝土结构 |
| has_superstructure_rc_engineered | 是否有工程钢筋混凝土结构 |
| has_superstructure_other | 是否有其他结构 |
| legal_ownership_status | 法律所有权状态 |
| count_families | 家庭数量 |
| has_secondary_use | 是否有次要用途 |
| has_secondary_use_agriculture | 是否有农业次要用途 |
| has_secondary_use_hotel | 是否有酒店次要用途 |
| has_secondary_use_rental | 是否有出租次要用途 |
| has_secondary_use_institution | 是否有机构次要用途 |
| has_secondary_use_school | 是否有学校次要用途 |
| has_secondary_use_industry | 是否有工业次要用途 |
| has_secondary_use_health_post | 是否有医疗设施次要用途 |
| has_secondary_use_gov_office | 是否有政府办公室次要用途 |
| has_secondary_use_use_police | 是否有警察局次要用途 |
| has_secondary_use_other | 是否有其他次要用途 |
| damage_grade | 损坏等级 |
Data Analysis and Visualization 数据分析与可视化
Correlation 相关性
使用斯皮尔曼相关系数计算数据集中数值型特征与目标变量之间的相关性,并创建一个热力图来可视化这些相关性。热力图中的颜色深浅表示了相关性的强弱,同时在图中还显示了具体的相关系数数值。此外,通过掩码操作,对角线以下的相关性值被遮盖,以避免重复显示。
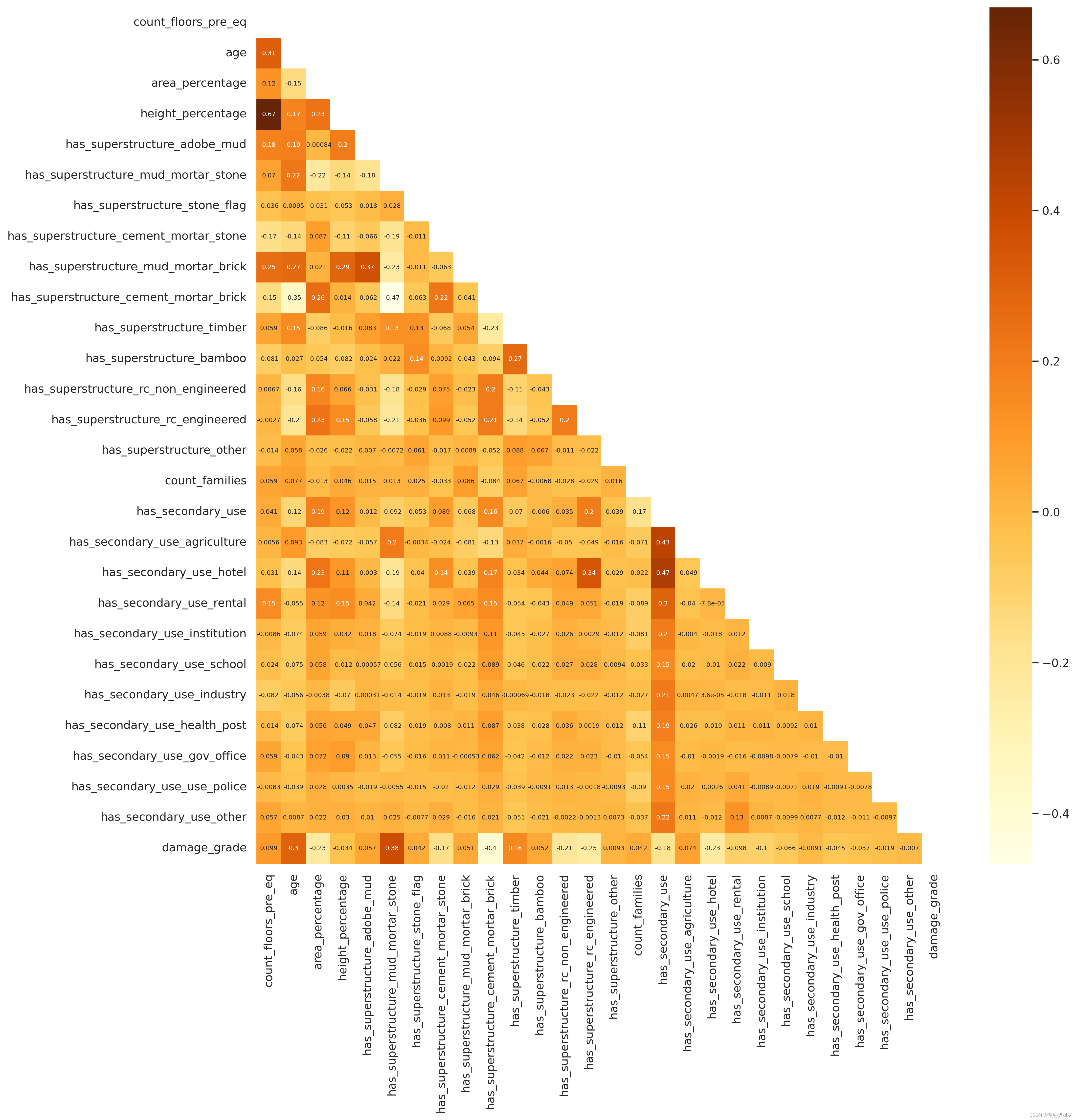
Hierarchial Clustering 分层聚类
通过分层聚类的方法将特征进行聚类。函数接受数据集、标签和方法参数作为输入。首先,它计算特征之间的相关性矩阵,然后利用相关性矩阵构建聚类树。接着,使用函数生成特征之间的链接矩阵表示特征的相似性。最后,通过以树状图的形式可视化特征的聚类结果,并在图表上显示特征的标签。
Adversarial Validation 对抗验证
绘制一个包含多个子图的图表,用于显示训练数据集和测试数据集中数值型特征的分布情况。在每个子图中,使用直方图来展示该特征在训练数据集和测试数据集中的分布情况,其中训练数据集的直方图以红色表示,测试数据集的直方图以绿色表示。同时,对于没有特征对应的子图,将其隐藏。整个图表的标题用于描述特征在不同数据集中的分布情况,并在图例中标识了训练数据集和测试数据集。

在对抗验证中看到,训练和测试数据可能不遵循相同的分布,但是,从视觉上看,一些数值变量在两者中具有相同的分布。
Target 目标
针对训练数据集中目标变量的不同取值,绘制一个柱状图来展示每个取值对应的样本数量。
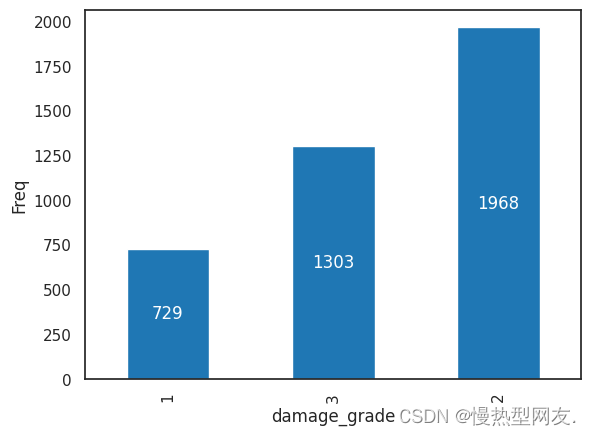
这是一个具有不平衡类的数据集,在这种情况下,我们将选择在验证中使用 Stratified K-Fold。
Stratified K-Fold 是一种交叉验证的方法,它能够在划分数据集时保持每个折叠中各个类别样本的比例与整个数据集中各个类别样本的比例相似。在机器学习中,特别是在处理不平衡类别的数据集时,使用 Stratified K-Fold 能够更好地确保模型在交叉验证过程中对各个类别的预测能力。这种方法有助于减少由于不平衡数据引起的模型评估偏差,提高模型评估的准确性和稳健性。
Model 模型
对多个分类模型进行了交叉验证,并记录了它们的性能评分。
models = [('log', LogisticRegression(random_state = SEED, max_iter = 1000000)),('bnb', BernoulliNB()),('rf', RandomForestClassifier(random_state = SEED)),('et', ExtraTreesClassifier(random_state = SEED)),('xgb', XGBClassifier(random_state = SEED)),('lgb', LGBMClassifier(random_state = SEED,verbosity=0)),('gb', GradientBoostingClassifier(random_state = SEED)),('hgb', HistGradientBoostingClassifier(random_state = SEED))
]
这些模型的性能评估结果如下:
Val Score: 0.53032 ± 0.01052 | Train Score: 0.54762 ± 0.00718 | log
Val Score: 0.52955 ± 0.00822 | Train Score: 0.53774 ± 0.00188 | bnb
Val Score: 0.53408 ± 0.01000 | Train Score: 0.99584 ± 0.00076 | rf
Val Score: 0.51914 ± 0.00924 | Train Score: 0.99584 ± 0.00076 | et
Val Score: 0.52693 ± 0.01181 | Train Score: 0.89624 ± 0.00137 | xgb
Val Score: 0.52754 ± 0.01253 | Train Score: 0.83933 ± 0.00353 | lgb
Val Score: 0.52542 ± 0.01657 | Train Score: 0.63977 ± 0.00856 | gb
Val Score: 0.52613 ± 0.00736 | Train Score: 0.88695 ± 0.00303 | hgb
根据结果来看,各个模型的验证集得分(Val Score)大致在 0.52 到 0.53 之间,训练集得分(Train Score)则普遍较高。这可能表明模型存在一定程度的过拟合,即在训练集上表现优秀,但在验证集上的表现较差。特别地,随机森林(rf)和极端随机树(et)模型在训练集上获得了接近1的得分,可能存在过拟合的风险。
Vote 投票
定义了一个投票分类器 voting,将之前定义的多个模型 models 作为投票的选项,并使用软投票策略进行投票。
Val Score: 0.54648 ± 0.01122 | Train Score: 0.96209 ± 0.00166 | mean_models
根据结果来看,使用投票分类器进行软投票(voting=‘soft’)得到的验证集得分为 0.54648,训练集得分为 0.96209。与之前单个模型相比,投票分类器在验证集上的得分略有提升,说明投票策略可以有效地改善模型性能。
Score Models 模型评分
对模型评分进行可视化展示,以便更清晰地展示模型评分的信息。