网站建设福州seo标题优化裤子关键词
文章目录
- 0. 前言
- 1. 网络结构
- 2. VanillaNet非线性表达能力增强策略
- 2.1 深度训练
- 2.2 扩展激活函数
- 3. 总结
- 4. 参考
0. 前言
随着人工智能芯片的发展,神经网络推理速度的瓶颈不再是FLOPs或参数量,因为现代GPU可以很容易地进行计算能力较强的并行计算。相比之下,神经网络复杂的设计和较大的深度阻碍了它们的速度。在此背景下,华为诺亚提出了极简网络架构VanillaNet,在ImageNet数据集上,深度为6的网络即可取得76.36%的精度,深度达到13时便能取得83.1%的精度!
1. 网络结构
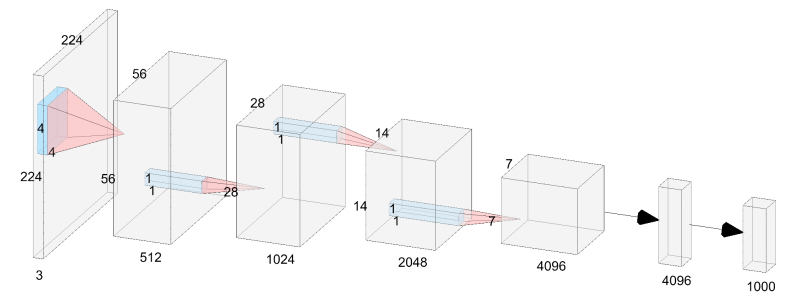
深度为6的VanillaNet结构如上图所示,一共包括三个部分:
- stem部分:一个4×4卷积 + 激活层
- body部分:由3个卷积模块组成,每个卷积模块由“1×1卷积+MaxPool+激活层”构成
- head部分:由“1×1卷积 + 激活 + 1×1卷积”组成
虽然VanillaNet的体系结构简单且相对较浅,但其微弱的非线性限制了其性能,因此,作者们从训练策略和激活函数这两个角度来解决该问题。
2. VanillaNet非线性表达能力增强策略
2.1 深度训练
简单来说,就是将激活函数 A ( x ) A(x) A(x)替换为 A ′ ( x ) A^{\prime}(x) A′(x),如下式:
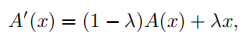
其中, λ = e E \lambda= \frac{e}{E} λ=Ee, e e e表示当前epoch, E E E表示总epoch数。因此,在训练开始时, λ = 0 \lambda=0 λ=0,此时 A ′ ( x ) = A ( x ) A^{\prime}(x)=A(x) A′(x)=A(x),网络具有很强的非线性;当训练结束时, λ = 1 \lambda=1 λ=1,此时 A ′ ( x ) = x A^{\prime}(x)=x A′(x)=x,意味着两个卷积层中间没有激活函数,满足线性条件,可以通过重参数化转换为单个卷积层,从而减小网络深度。
2.2 扩展激活函数
改善神经网络非线性表达能力的方法有两种:叠加非线性激活层或增加每个激活层的非线性,而现有网络的趋势是选择前者,当并行计算能力过剩时,会导致较高的延迟。提高网络非线性的一个直接思想是堆,激活函数的连续叠加是深度网络的关键思想。在VanillaNet中,作者们独辟蹊径,转向并行地堆叠激活函数,如下式:
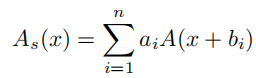
其中, n n n为并行激活函数的数量, a i a_i ai和 b i b_i bi分别为尺度因子和偏执,以避免简单地累加。为进一步丰富表达能力,参考BNET,作者为其引入了全局信息学习能力,此时激活函数表示如下:

这部分建议直接看代码,实现起来就是relu激活后接depthwise卷积,padding设置为并行激活的数量 n n n
3. 总结
如果能够将深度训练和重参数化合理地结合起来,就是模型压缩利器,大有文章可做,挖个坑~
4. 参考
VanillaNet: the Power of Minimalism in Deep Learning